Posts Tagged Spring Cloud Config
Diving Deeper into ‘Getting Started with Spring Cloud’
Posted by Gary A. Stafford in DevOps, Enterprise Software Development, Java Development, Software Development on February 15, 2016

Explore the integration of Spring Cloud and Spring Cloud Netflix tooling, through a deep dive into Pivotal’s ‘Getting Started with Spring Cloud’ presentation.
Introduction
Keeping current with software development and DevOps trends can often make us feel we are, as the overused analogy describes, drinking from a firehose, often several hoses at once. Recently joining a large client engagement, I found it necessary to supplement my knowledge of cloud-native solutions, built with the support of Spring Cloud and Spring Cloud Netflix technologies. One of my favorite sources of information on these subjects is presentations by people like Josh Long, Dr. Dave Syer, and Cornelia Davis of Pivotal Labs, and Jon Schneider and Taylor Wicksell of Netflix.
One presentation, in particular, Getting Started with Spring Cloud, by Long and Syer, provides an excellent end-to-end technical overview of the latest Spring and Netflix technologies. Josh Long’s fast-paced, eighty-minute presentation, available on YouTube, was given at SpringOne2GX 2015 with co-presenter, Dr. Dave Syer, founder of Spring Cloud, Spring Boot, and Spring Batch.
As the presenters of Getting Started with Spring Cloud admit, the purpose of the presentation was to get people excited about Spring Cloud and Netflix technologies, not to provide a deep dive into each technology. However, I believe the presentation’s Reservation Service example provides an excellent learning opportunity. In the following post, we will examine the technologies, components, code, and configuration presented in Getting Started with Spring Cloud. The goal of the post is to provide a greater understanding of the Spring Cloud and Spring Cloud Netflix technologies.
System Overview
Technologies
The presentation’s example introduces a dizzying array of technologies, which include:
Spring Boot
Stand-alone, production-grade Spring-based applications
Spring Data REST / Spring HATEOAS
Spring-based applications following HATEOAS principles
Spring Cloud Config
Centralized external configuration management, backed by Git
Netflix Eureka
REST-based service discovery and registration for failover and load-balancing
Netflix Ribbon
IPC library with built-in client-side software load-balancers
Netflix Zuul
Dynamic routing, monitoring, resiliency, security, and more
Netflix Hystrix
Latency and fault tolerance for distributed system
Netflix Hystrix Dashboard
Web-based UI for monitoring Hystrix
Spring Cloud Stream
Messaging microservices, backed by Redis
Spring Data Redis
Configuration and access to Redis from a Spring app, using Jedis
Spring Cloud Sleuth
Distributed tracing solution for Spring Cloud, sends traces via Thrift to the Zipkin collector service
Twitter Zipkin
Distributed tracing system, backed by Apache Cassandra
H2
In-memory Java SQL database, embedded and server modes
Docker
Package applications with dependencies into standardized Linux containers
System Components
Several components and component sub-systems comprise the presentation’s overall Reservation Service example. Each component implements a combination of the technologies mentioned above. Below is a high-level architectural diagram of the presentation’s example. It includes a few additional features, added as part of this post.

Individual system components include:
Spring Cloud Config Server
Stand-alone Spring Boot application provides centralized external configuration to multiple Reservation system components
Spring Cloud Config Git Repo
Git repository containing multiple Reservation system components configuration files, served by Spring Cloud Config Server
H2 Java SQL Database Server (New)
This post substitutes the original example’s use of H2’s embedded version with a TCP Server instance, shared by Reservation Service instances
Reservation Service
Multi load-balanced instances of stand-alone Spring Boot application, backed by H2 database
Reservation Client
Stand-alone Spring Boot application (aka edge service or client-side proxy), forwards client-side load-balanced requests to the Reservation Service, using Eureka, Zuul, and Ribbon
Reservation Data Seeder (New)
Stand-alone Spring Boot application, seeds H2 with initial data, instead of the Reservation Service
Eureka Service
Stand-alone Spring Boot application provides service discovery and registration for failover and load-balancing
Hystrix Dashboard
Stand-alone Spring Boot application provides web-based Hystrix UI for monitoring system performance and Hystrix circuit-breakers
Zipkin
Zipkin Collector, Query, and Web, and Cassandra database, receives, correlates, and displays traces from Spring Cloud Sleuth
Redis
In-memory data structure store, acting as message broker/transport for Spring Cloud Stream
Github
All the code for this post is available on Github, split between two repositories. The first repository, spring-cloud-demo, contains the source code for all of the components listed above, except the Spring Cloud Config Git Repo. To function correctly, the configuration files, consumed by the Spring Cloud Config Server, needs to be placed into a separate repository, spring-cloud-demo-config-repo.
The first repository contains a git submodule , docker-zipkin. If you are not familiar with submodules, you may want to take a moment to read the git documentation. The submodule contains a dockerized version of Twitter’s OpenZipkin, docker-zipkin. To clone the two repositories, use the following commands. The --recursive option is required to include the docker-zipkin submodule in the project.
| git clone https://github.com/garystafford/spring-cloud-demo-config-repo.git | |
| git clone --recursive https://github.com/garystafford/spring-cloud-demo.git |
Configuration
To try out the post’s Reservation system example, you need to configure at least one property. The Spring Cloud Config Server needs to know the location of the Spring Cloud Config Repository, which is the second GitHub repository you cloned, spring-cloud-demo-config-repo. From the root of the spring-cloud-demo repo, edit the Spring Cloud Config Server application.properties file, located in config-server/src/main/resources/application.properties. Change the following property’s value to your local path to the spring-cloud-demo-config-repo repository:
| spring.cloud.config.server.git.uri=file:<YOUR_PATH_GOES_HERE>/spring-cloud-demo-config-repo |
Startup
There are a few ways you could run the multiple components that make up the post’s example. I suggest running one component per terminal window, in the foreground. In this way, you can monitor the output from the bootstrap and startup processes of the system’s components. Furthermore, you can continue to monitor the system’s components once they are up and running, and receiving traffic. Yes, that is twelve terminal windows…
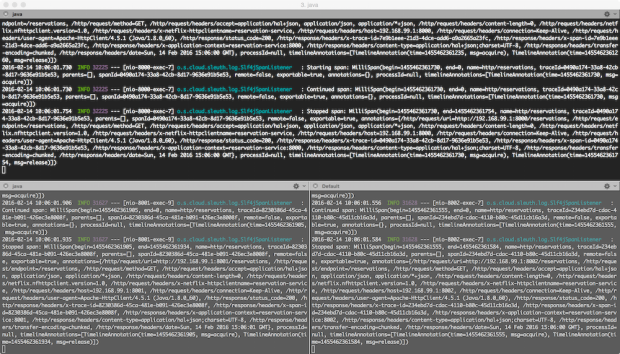
There is a required startup order for the components. For example, Spring Cloud Config Server needs to start before the other components that rely on it for configuration. Netflix’s Eureka needs to start before the Reservation Client and ReservationServices, so they can register with Eureka on startup. Similarly, Zipkin needs to be started in its Docker container before the Reservation Client and Services, so Spring Cloud Sleuth can start sending traces. Redis needs to be started in its Docker container before Spring Cloud Stream tries to create the message queue. All instances of the Reservation Service needs to start before the Reservation Client. Once every component is started, the Reservation Data Seeder needs to be run once to create initial data in H2. For best results, follow the instructions below. Let each component start completely, before starting the next component.
| # IMPORTANT: set this to the spring-cloud-demo repo directory | |
| export SPRING_DEMO=<YOUR_PATH_GOES_HERE>/spring-cloud-demo | |
| # Redis - on Mac, in Docker Quickstart Terminal | |
| cd ${SPRING_DEMO}/docker-redis/ | |
| docker-compose up | |
| # Zipkin - on Mac, in Docker Quickstart Terminal | |
| cd ${SPRING_DEMO}/docker-zipkin/ | |
| docker-compose up | |
| # *** MAKE SURE ZIPKIN STARTS SUCCESSFULLY! *** | |
| # *** I HAVE TO RESTART >50% OF TIME... *** | |
| # H2 Database Server - in new terminal window | |
| cd ${SPRING_DEMO}/h2-server | |
| java -cp h2*.jar org.h2.tools.Server -webPort 6889 | |
| # Spring Cloud Config Server - in new terminal window | |
| cd ${SPRING_DEMO}/config-server | |
| mvn clean package spring-boot:run | |
| # Eureka Service - in new terminal window | |
| cd ${SPRING_DEMO}/eureka-server | |
| mvn clean package spring-boot:run | |
| # Hystrix Dashboard - in new terminal window | |
| cd ${SPRING_DEMO}/hystrix-dashboard | |
| mvn clean package spring-boot:run | |
| # Reservation Service - instance 1 - in new terminal window | |
| cd ${SPRING_DEMO}/reservation-service | |
| mvn clean package | |
| mvn spring-boot:run -Drun.jvmArguments='-Dserver.port=8000' | |
| # Reservation Service - instance 2 - in new terminal window | |
| cd ${SPRING_DEMO}/reservation-service | |
| mvn spring-boot:run -Drun.jvmArguments='-Dserver.port=8001' | |
| # Reservation Service - instance 3 - in new terminal window | |
| cd ${SPRING_DEMO}/reservation-service | |
| mvn spring-boot:run -Drun.jvmArguments='-Dserver.port=8002' | |
| # Reservation Client - in new terminal window | |
| cd ${SPRING_DEMO}/reservation-client | |
| mvn clean package spring-boot:run | |
| # Load seed data into H2 - in new terminal window | |
| cd ${SPRING_DEMO}/reservation-data-seeder | |
| mvn clean package spring-boot:run | |
| # Redis redis-cli monitor - on Mac, in new Docker Quickstart Terminal | |
| docker exec -it dockerredis_redis_1 redis-cli | |
| 127.0.0.1:6379> monitor |
Docker
Both Zipkin and Redis run in Docker containers. Redis runs in a single container. Zipkin’s four separate components run in four separate containers. Be advised, Zipkin seems to have trouble successfully starting all four of its components on a consistent basis. I believe it’s a race condition caused by Docker Compose simultaneously starting the four Docker containers, ignoring a proper startup order. More than half of the time, I have to stop Zipkin and rerun the docker command to get Zipkin to start without any errors.
If you’ve followed the instructions above, you should see the following Docker images and Docker containers installed and running in your local environment.
| docker is configured to use the default machine with IP 192.168.99.100 | |
| gstafford@nagstaffo:~$ docker images | |
| REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE | |
| redis latest 8bccd73928d9 5 weeks ago 151.3 MB | |
| openzipkin/zipkin-cassandra 1.30.0 8bbc92bceff0 5 weeks ago 221.9 MB | |
| openzipkin/zipkin-web 1.30.0 c854ecbcef86 5 weeks ago 155.1 MB | |
| openzipkin/zipkin-query 1.30.0 f0c45a26988a 5 weeks ago 180.3 MB | |
| openzipkin/zipkin-collector 1.30.0 5fcf0ba455a0 5 weeks ago 183.8 MB | |
| gstafford@nagstaffo:~$ docker ps -a | |
| CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES | |
| 1fde6bb2dc99 openzipkin/zipkin-web:1.30.0 "/usr/local/bin/run" 3 weeks ago Up 11 days 0.0.0.0:8080->8080/tcp, 0.0.0.0:9990->9990/tcp dockerzipkin_web_1 | |
| 16e65180296e openzipkin/zipkin-query:1.30.0 "/usr/local/bin/run.s" 3 weeks ago Up 11 days 0.0.0.0:9411->9411/tcp, 0.0.0.0:9901->9901/tcp dockerzipkin_query_1 | |
| b1ca16408274 openzipkin/zipkin-collector:1.30.0 "/usr/local/bin/run.s" 3 weeks ago Up 11 days 0.0.0.0:9410->9410/tcp, 0.0.0.0:9900->9900/tcp dockerzipkin_collector_1 | |
| c7195ee9c4ff openzipkin/zipkin-cassandra:1.30.0 "/bin/sh -c /usr/loca" 3 weeks ago Up 11 days 7000-7001/tcp, 7199/tcp, 9160/tcp, 0.0.0.0:9042->9042/tcp dockerzipkin_cassandra_1 | |
| fe0396908e29 redis "/entrypoint.sh redis" 3 weeks ago Up 11 days 0.0.0.0:6379->6379/tcp dockerredis_redis_1 |
Components
Spring Cloud Config Server
At the center of the Reservation system is Spring Cloud Config. Configuration, typically found in the application.properties file, for the Reservation Services, Reservation Client, Reservation Data Seeder, Eureka Service, and Hystix Dashboard, has been externalized with Spring Cloud Config.
Each component has a bootstrap.properties file, which modifies its startup behavior during the bootstrap phase of an application context. Each bootstrap.properties file contains the component’s name and the address of the Spring Cloud Config Server. Components retrieve their configuration from the Spring Cloud Config Server at runtime. Below, is an example of the Reservation Client’s bootstrap.properties file.
| # reservation client bootstrap props | |
| spring.application.name=reservation-client | |
| spring.cloud.config.uri=http://localhost:8888 |
Spring Cloud Config Git Repo
In the presentation, as in this post, the Spring Cloud Config Server is backed by a locally cloned Git repository, the Spring Cloud Config Git Repo. The Spring Cloud Config Server’s application.properties file contains the address of the Git repository. Each properties file within the Git repository corresponds to a system component. Below, is an example of the reservation-client.properties file, from the Spring Cloud Config Git Repo.
| # reservation client app props | |
| server.port=8050 | |
| message=Spring Cloud Config: Reservation Client | |
| # spring cloud stream / redis | |
| spring.cloud.stream.bindings.output=reservations | |
| spring.redis.host=192.168.99.100 | |
| spring.redis.port=6379 | |
| # zipkin / spring cloud sleuth | |
| spring.zipkin.host=192.168.99.100 | |
| spring.zipkin.port=9410 |
As shown in the original presentation, the configuration files can be viewed using HTTP endpoints of the Spring Cloud Config Server. To view the Reservation Service’s configuration stored in the Spring Cloud Config Git Repo, issue an HTTP GET request to http://localhost:8888/reservation-service/master. The master URI refers to the Git repo branch in which the configuration resides. This will return the configuration, in the response body, as JSON:

In a real Production environment, the Spring Cloud Config Server would be backed by a highly-available Git Server or GitHub repository.
Reservation Service
The Reservation Service is the core component in the presentation’s example. The Reservation Service is a stand-alone Spring Boot application. By implementing Spring Data REST and Spring HATEOAS, Spring automatically creates REST representations from the Reservation JPA Entity class of the Reservation Service. There is no need to write a Spring Rest Controller and explicitly code each endpoint.

Spring HATEOAS allows us to interact with the Reservation Entity, using HTTP methods, such as GET and POST. These endpoints, along with all addressable endpoints, are displayed in the terminal output when a Spring Boot application starts. For example, we can use an HTTP GET request to call the reservations/{id} endpoint, such as:
| curl -X GET -H "Content-Type: application/json" \ | |
| --url 'http://localhost:8000/reservations' | |
| curl -X GET -H "Content-Type: application/json" \ | |
| --url 'http://localhost:8000/reservations/2' |
The Reservation Service also makes use of the Spring RepositoryRestResource annotation. By annotating the RepositoryReservation Interface, which extends JpaRepository, we can customize export mapping and relative paths of the Reservation JPA Entity class. As shown below, the RepositoryReservation Interface contains the findByReservationName method signature, annotated with /by-name endpoint, which accepts the rn input parameter.
| @RepositoryRestResource | |
| interface ReservationRepository extends JpaRepository<Reservation, Long> { | |
| @RestResource(path = "by-name") | |
| Collection<Reservation> findByReservationName(@Param("rn") String rn); | |
| } |
Calling the findByReservationName method, we can search for a particular reservation by using an HTTP GET request to call the reservations/search/by-name?rn={reservationName} endpoint.
| curl -X GET -H "Content-Type: application/json" \ | |
| --url 'http://localhost:8000/reservations/search/by-name?rn=Amit' |

Reservation Client
Querying the Reservation Service directly is possible, however, is not the recommended. Instead, the presentation suggests using the Reservation Client as a proxy to the Reservation Service. The presentation offers three examples of using the Reservation Client as a proxy.
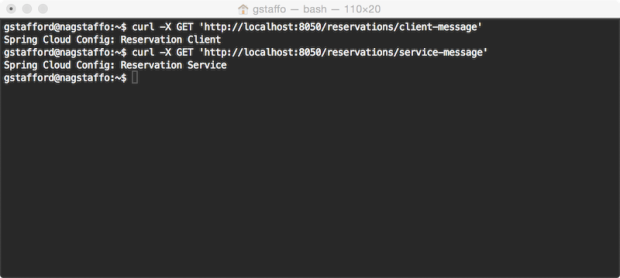
The first demonstration of the Reservation Client uses the /message endpoint on the Reservation Client to return a string from the Reservation Service. The message example has been modified to include two new endpoints on the Reservation Client. The first endpoint, /reservations/client-message, returns a message directly from the Reservation Client. The second endpoint, /reservations/service-message, returns a message indirectly from the Reservation Service. To retrieve the message from the Reservation Service, the Reservation Client sends a request to the endpoint Reservation Service’s /message endpoint.
| @RequestMapping(path = "/client-message", method = RequestMethod.GET) | |
| public String getMessage() { | |
| return this.message; | |
| } | |
| @RequestMapping(path = "/service-message", method = RequestMethod.GET) | |
| public String getReservationServiceMessage() { | |
| return this.restTemplate.getForObject( | |
| "http://reservation-service/message", | |
| String.class); | |
| } |
To retrieve both messages, send separate HTTP GET requests to each endpoint:
| curl 'http://localhost:8050/reservations/client-message' | |
| curl 'http://localhost:8050/reservations/service-message' |
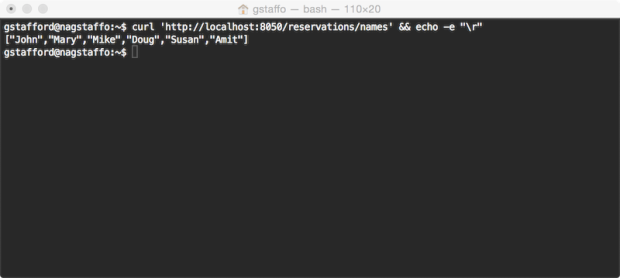
The second demonstration of the Reservation Client uses a Data Transfer Object (DTO). Calling the Reservation Client’s reservations/names endpoint, invokes the getReservationNames method. This method, in turn, calls the Reservation Service’s /reservations endpoint. The response object returned from the Reservation Service, a JSON array of reservation records, is deserialized and mapped to the Reservation Client’s Reservation DTO. Finally, the method returns a collection of strings, representing just the names from the reservations.
| @RequestMapping(path = "/names", method = RequestMethod.GET) | |
| public Collection<String> getReservationNames() { | |
| ParameterizedTypeReference<Resources<Reservation>> ptr = | |
| new ParameterizedTypeReference<Resources<Reservation>>() {}; | |
| return this.restTemplate.exchange("http://reservation-service/reservations", GET, null, ptr) | |
| .getBody() | |
| .getContent() | |
| .stream() | |
| .map(Reservation::getReservationName) | |
| .collect(toList()); | |
| } |
To retrieve the collection of reservation names, an HTTP GET request is sent to the /reservations/names endpoint:
| curl 'http://localhost:8050/reservations/names' |
Spring Cloud Stream
One of the more interesting technologies in the presentation is Spring’s Spring Cloud Stream. The Spring website describes Spring Cloud Stream as a project that allows users to develop and run messaging microservices using Spring Integration. In other words, it provides native Spring messaging capabilities, backed by a choice of message buses, including Redis, RabbitMQ, and Apache Kafka, to Spring Boot applications.
A detailed explanation of Spring Cloud Stream would take an entire post. The best technical demonstration I have found is the presentation, Message Driven Microservices in the Cloud, by speakers Dr. David Syer and Dr. Mark Pollack, given in January 2016, also at SpringOne2GX 2015.

In the presentation, a new reservation is submitted via an HTTP POST to the acceptNewReservations method of the Reservation Client. The method, in turn, builds (aka produces) a message, containing the new reservation, and publishes that message to the queue.reservation queue.
| @Autowired | |
| @Output(OUTPUT) | |
| private MessageChannel messageChannel; | |
| @Value("${message}") | |
| private String message; | |
| @Description("Post new reservations using Spring Cloud Stream") | |
| @RequestMapping(method = POST) | |
| public void acceptNewReservations(@RequestBody Reservation r) { | |
| Message<String> build = withPayload(r.getReservationName()).build(); | |
| this.messageChannel.send(build); | |
| } |
The queue.reservation queue is located in Redis, which is running inside a Docker container. To view the messages being published to the queue in real-time, use the redis-cli, with the monitor command, from within the Redis Docker container. Below is an example of tests messages pushed (LPUSH) to the reservations queue from the Reservation Client.
| gstafford@nagstaffo:~$ docker exec -it dockerredis_redis_1 redis-cli | |
| 127.0.0.1:6379> monitor | |
| OK | |
| 1455332771.709412 [0 192.168.99.1:62177] "BRPOP" "queue.reservations" "1" | |
| 1455332772.110386 [0 192.168.99.1:59782] "BRPOP" "queue.reservations" "1" | |
| 1455332773.689777 [0 192.168.99.1:62183] "LPUSH" "queue.reservations" "\xff\x04\x0bcontentType\x00\x00\x00\x0c\"text/plain\"\tX-Span-Id\x00\x00\x00&\"49a5b1d1-e7e9-46de-9d9f-647d5b19a77b\"\nX-Trace-Id\x00\x00\x00&\"49a5b1d1-e7e9-46de-9d9f-647d5b19a77b\"\x0bX-Span-Name\x00\x00\x00\x13\"http/reservations\"Test-Name-01" | |
| 1455332777.124788 [0 192.168.99.1:59782] "BRPOP" "queue.reservations" "1" | |
| 1455332777.425655 [0 192.168.99.1:59776] "BRPOP" "queue.reservations" "1" | |
| 1455332777.581693 [0 192.168.99.1:62183] "LPUSH" "queue.reservations" "\xff\x04\x0bcontentType\x00\x00\x00\x0c\"text/plain\"\tX-Span-Id\x00\x00\x00&\"32db0e25-982a-422f-88bb-2e7c2e4ce393\"\nX-Trace-Id\x00\x00\x00&\"32db0e25-982a-422f-88bb-2e7c2e4ce393\"\x0bX-Span-Name\x00\x00\x00\x13\"http/reservations\"Test-Name-02" | |
| 1455332781.442398 [0 192.168.99.1:59776] "BRPOP" "queue.reservations" "1" | |
| 1455332781.643077 [0 192.168.99.1:62177] "BRPOP" "queue.reservations" "1" | |
| 1455332781.669264 [0 192.168.99.1:62183] "LPUSH" "queue.reservations" "\xff\x04\x0bcontentType\x00\x00\x00\x0c\"text/plain\"\tX-Span-Id\x00\x00\x00&\"85ebf225-3324-434e-ba38-17411db745ac\"\nX-Trace-Id\x00\x00\x00&\"85ebf225-3324-434e-ba38-17411db745ac\"\x0bX-Span-Name\x00\x00\x00\x13\"http/reservations\"Test-Name-03" | |
| 1455332785.452291 [0 192.168.99.1:59776] "BRPOP" "queue.reservations" "1" | |
| 1455332785.652809 [0 192.168.99.1:62177] "BRPOP" "queue.reservations" "1" | |
| 1455332785.706438 [0 192.168.99.1:62183] "LPUSH" "queue.reservations" "\xff\x04\x0bcontentType\x00\x00\x00\x0c\"text/plain\"\tX-Span-Id\x00\x00\x00&\"aaad3210-cfda-49b9-ba34-a1e8c1b2995c\"\nX-Trace-Id\x00\x00\x00&\"aaad3210-cfda-49b9-ba34-a1e8c1b2995c\"\x0bX-Span-Name\x00\x00\x00\x13\"http/reservations\"Test-Name-04" | |
| 1455332789.665349 [0 192.168.99.1:62177] "BRPOP" "queue.reservations" "1" | |
| 1455332789.764794 [0 192.168.99.1:59782] "BRPOP" "queue.reservations" "1" | |
| 1455332790.064547 [0 192.168.99.1:62183] "LPUSH" "queue.reservations" "\xff\x04\x0bcontentType\x00\x00\x00\x0c\"text/plain\"\tX-Span-Id\x00\x00\x00&\"545ce7b9-7ba4-42ae-8d2a-374ec7914240\"\nX-Trace-Id\x00\x00\x00&\"545ce7b9-7ba4-42ae-8d2a-374ec7914240\"\x0bX-Span-Name\x00\x00\x00\x13\"http/reservations\"Test-Name-05" | |
| 1455332790.070190 [0 192.168.99.1:59776] "BRPOP" "queue.reservations" "1" | |
| 1455332790.669056 [0 192.168.99.1:62177] "BRPOP" "queue.reservations" "1" |
The published messages are consumed by subscribers to the reservation queue. In this example, the consumer is the Reservation Service. The Reservation Service’s acceptNewReservation method processes the message and saves the new reservation to the H2 database. In Spring Cloud Stream terms, the Reservation Client is the Sink.
| @MessageEndpoint | |
| class ReservationProcessor { | |
| @Autowired | |
| private ReservationRepository reservationRepository; | |
| @ServiceActivator(inputChannel = INPUT) | |
| public void acceptNewReservation(String rn) { | |
| this.reservationRepository.save(new Reservation(rn)); | |
| } | |
| } |
Netflix Eureka
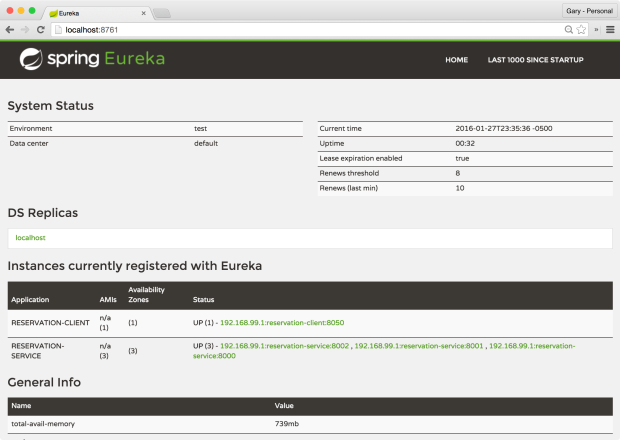
Netflix’s Eureka, in combination with Netflix’s Zuul and Ribbon, provide the ability to scale the Reservation Service horizontally, and to load balance those instances. By using the @EnableEurekaClient annotation on the Reservation Client and Reservation Services, each instance will automatically register with Eureka on startup, as shown in the Eureka Web UI, below.

The names of the registered instances are in three parts: the address of the host on which the instance is running, followed by the value of the spring.application.name property of the instance’s bootstrap.properties file, and finally, the port number the instance is running on. Eureka displays each instance’s status, along with additional AWS information, if you are running on AWS, as Netflix does.

According to Spring in their informative post, Spring Cloud, service discovery is one of the key tenets of a microservice based architecture. Trying to hand-configure each client, or to rely on convention over configuration, can be difficult to do and is brittle. Eureka is the Netflix Service Discovery Server and Client. A client (Spring Boot application), registers with Eureka, providing metadata about itself. Eureka then receives heartbeat messages from each instance. If the heartbeat fails over a configurable timetable, the instance is normally removed from the registry.
The Reservation Client application is also annotated with @EnableZuulProxy. Adding this annotation pulls in Spring Cloud’s embedded Zuul proxy. Again, according to Spring, the proxy is used by front-end applications to proxy calls to one or more back-end services, avoiding the need to manage CORS and authentication concerns independently for all the backends. In the presentation and this post, the front end is the Reservation Client and the back end is the Reservation Service.
In the code snippet below from the ReservationApiGatewayRestController, note the URL of the endpoint requested in the getReservationNames method. Instead of directly calling http://localhost:8000/reservations, the method calls http://reservation-service/reservations. The reservation-service segment of the URL is the registered name of the service in Eureka and contained in the Reservation Service’s bootstrap.properties file.
| @RequestMapping(path = "/names", method = RequestMethod.GET) | |
| public Collection<String> getReservationNames() { | |
| ParameterizedTypeReference<Resources<Reservation>> ptr = | |
| new ParameterizedTypeReference<Resources<Reservation>>() {}; | |
| return this.restTemplate.exchange("http://reservation-service/reservations", GET, null, ptr) | |
| .getBody() | |
| .getContent() | |
| .stream() | |
| .map(Reservation::getReservationName) | |
| .collect(toList()); | |
| } |
In the following abridged output from the Reservation Client, you can clearly see the interaction of Zuul, Ribbon, Eureka, and Spring Cloud Config. Note the Client application has successfully registering itself with Eureka, along with the Reservation Client’s status. Also, note Zuul mapping the Reservation Service’s URL path.
| 2016-01-28 00:00:03.667 INFO 17223 --- [ main] com.netflix.discovery.DiscoveryClient : Getting all instance registry info from the eureka server | |
| 2016-01-28 00:00:03.813 INFO 17223 --- [ main] com.netflix.discovery.DiscoveryClient : The response status is 200 | |
| 2016-01-28 00:00:03.814 INFO 17223 --- [ main] com.netflix.discovery.DiscoveryClient : Starting heartbeat executor: renew interval is: 30 | |
| 2016-01-28 00:00:03.817 INFO 17223 --- [ main] c.n.discovery.InstanceInfoReplicator : InstanceInfoReplicator onDemand update allowed rate per min is 4 | |
| 2016-01-28 00:00:03.935 INFO 17223 --- [ main] c.n.e.EurekaDiscoveryClientConfiguration : Registering application reservation-client with eureka with status UP | |
| 2016-01-28 00:00:03.936 INFO 17223 --- [ main] com.netflix.discovery.DiscoveryClient : Saw local status change event StatusChangeEvent [current=UP, previous=STARTING] | |
| 2016-01-28 00:00:03.941 INFO 17223 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_RESERVATION-CLIENT/192.168.99.1:reservation-client:8050: registering service... | |
| 2016-01-28 00:00:03.942 INFO 17223 --- [ main] o.s.c.n.zuul.web.ZuulHandlerMapping : Mapped URL path [/reservation-service/**] onto handler of type [class org.springframework.cloud.netflix.zuul.web.ZuulController] | |
| 2016-01-28 00:00:03.981 INFO 17223 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_RESERVATION-CLIENT/192.168.99.1:reservation-client:8050 - registration status: 204 | |
| 2016-01-28 00:00:04.075 INFO 17223 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8050 (http) | |
| 2016-01-28 00:00:04.076 INFO 17223 --- [ main] c.n.e.EurekaDiscoveryClientConfiguration : Updating port to 8050 | |
| 2016-01-28 00:00:04.080 INFO 17223 --- [ main] c.example.ReservationClientApplication : Started ReservationClientApplication in 9.172 seconds (JVM running for 12.536) |
Load Balancing
One shortcoming of the original presentation was true load balancing. With only a single instance of the Reservation Service in the original presentation, there is nothing to load balance; it’s more of a reverse proxy example. To demonstrate load balancing, we need to spin up additional instances of the Reservation Service. Following the post’s component start-up instructions, we should have three instances of the Reservation Service running, on ports 8000, 8001, and 8002, each in separate terminal windows.
To confirm the three instances of the Reservation Service were successfully registered with Eureka, review the output from the Eureka Server terminal window. The output should show three instances of the Reservation Service registering on startup, in addition to the Reservation Client.
| 2016-01-27 23:34:40.496 INFO 16668 --- [nio-8761-exec-9] c.n.e.registry.AbstractInstanceRegistry : Registered instance RESERVATION-SERVICE/192.168.99.1:reservation-service:8000 with status UP (replication=false) | |
| 2016-01-27 23:34:53.167 INFO 16668 --- [nio-8761-exec-7] c.n.e.registry.AbstractInstanceRegistry : Registered instance RESERVATION-SERVICE/192.168.99.1:reservation-service:8001 with status UP (replication=false) | |
| 2016-01-27 23:34:55.924 INFO 16668 --- [nio-8761-exec-1] c.n.e.registry.AbstractInstanceRegistry : Registered instance RESERVATION-SERVICE/192.168.99.1:reservation-service:8002 with status UP (replication=false) | |
| 2016-01-27 23:40:35.963 INFO 16668 --- [nio-8761-exec-5] c.n.e.registry.AbstractInstanceRegistry : Registered instance RESERVATION-CLIENT/192.168.99.1:reservation-client:8050 with status UP (replication=false) |
Viewing Eureka’s web console, we should observe three members in the pool of Reservation Services.
Lastly, looking at the terminal output of the Reservation Client, we should see three instances of the Reservation Service being returned by Ribbon (aka the DynamicServerListLoadBalancer).
| 2016-01-27 23:41:01.357 INFO 17125 --- [estController-1] c.netflix.config.ChainedDynamicProperty : Flipping property: reservation-service.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647 | |
| 2016-01-27 23:41:01.359 INFO 17125 --- [estController-1] c.n.l.DynamicServerListLoadBalancer : DynamicServerListLoadBalancer for client reservation-service initialized: DynamicServerListLoadBalancer:{NFLoadBalancer:name=reservation-service,current list of Servers=[192.168.99.1:8000, 192.168.99.1:8002, 192.168.99.1:8001],Load balancer stats=Zone stats: {defaultzone=[Zone:defaultzone; Instance count:3; Active connections count: 0; Circuit breaker tripped count: 0; Active connections per server: 0.0;] | |
| },Server stats: [[Server:192.168.99.1:8000; Zone:defaultZone; Total Requests:0; Successive connection failure:0; Total blackout seconds:0; Last connection made:Wed Dec 31 19:00:00 EST 1969; First connection made: Wed Dec 31 19:00:00 EST 1969; Active Connections:0; total failure count in last (1000) msecs:0; average resp time:0.0; 90 percentile resp time:0.0; 95 percentile resp time:0.0; min resp time:0.0; max resp time:0.0; stddev resp time:0.0] | |
| , [Server:192.168.99.1:8001; Zone:defaultZone; Total Requests:0; Successive connection failure:0; Total blackout seconds:0; Last connection made:Wed Dec 31 19:00:00 EST 1969; First connection made: Wed Dec 31 19:00:00 EST 1969; Active Connections:0; total failure count in last (1000) msecs:0; average resp time:0.0; 90 percentile resp time:0.0; 95 percentile resp time:0.0; min resp time:0.0; max resp time:0.0; stddev resp time:0.0] | |
| , [Server:192.168.99.1:8002; Zone:defaultZone; Total Requests:0; Successive connection failure:0; Total blackout seconds:0; Last connection made:Wed Dec 31 19:00:00 EST 1969; First connection made: Wed Dec 31 19:00:00 EST 1969; Active Connections:0; total failure count in last (1000) msecs:0; average resp time:0.0; 90 percentile resp time:0.0; 95 percentile resp time:0.0; min resp time:0.0; max resp time:0.0; stddev resp time:0.0] | |
| ]}ServerList:org.springframework.cloud.netflix.ribbon.eureka.DomainExtractingServerList@6e7a0f39 | |
| 2016-01-27 23:41:01.391 INFO 17125 --- [estController-1] com.netflix.http4.ConnectionPoolCleaner : Initializing ConnectionPoolCleaner for NFHttpClient:reservation-service | |
| 2016-01-27 23:41:01.828 INFO 17125 --- [nio-8050-exec-1] o.s.cloud.sleuth.log.Slf4jSpanListener : Stopped span: MilliSpan(begin=1453956061003, end=1453956061818, name=http/reservations/names, traceId=1f06b3ce-a5b9-4689-b1e7-22fb1f3ee10d, parents=[], spanId=1f06b3ce-a5b9-4689-b1e7-22fb1f3ee10d, remote=false, exportable=true, annotations={/http/request/uri=http://localhost:8050/reservations/names, /http/request/endpoint=/reservations/names, /http/request/method=GET, /http/request/headers/host=localhost:8050, /http/request/headers/connection=keep-alive, /http/request/headers/user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36, /http/request/headers/cache-control=no-cache, /http/request/headers/postman-token=0ee95302-3af6-b08a-a784-43490d74925b, /http/request/headers/content-type=application/json, /http/request/headers/accept=*/*, /http/request/headers/accept-encoding=gzip, deflate, sdch, /http/request/headers/accept-language=en-US,en;q=0.8, /http/response/status_code=200, /http/response/headers/x-trace-id=1f06b3ce-a5b9-4689-b1e7-22fb1f3ee10d, /http/response/headers/x-span-id=1f06b3ce-a5b9-4689-b1e7-22fb1f3ee10d, /http/response/headers/x-application-context=reservation-client:8050, /http/response/headers/content-type=application/json;charset=UTF-8, /http/response/headers/transfer-encoding=chunked, /http/response/headers/date=Thu, 28 Jan 2016 04:41:01 GMT}, processId=null, timelineAnnotations=[TimelineAnnotation(time=1453956061004, msg=acquire), TimelineAnnotation(time=1453956061818, msg=release)]) | |
| 2016-01-27 23:41:02.345 INFO 17125 --- [ool-14-thread-1] c.netflix.config.ChainedDynamicProperty : Flipping property: reservation-service.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647 |
Requesting http://localhost:8050/reservations/names, Ribbon forwards the request to one of the three Reservation Service instances registered with Eureka. By default, Ribbon uses a round-robin load-balancing strategy to select an instance from the pool of available Reservation Services.
H2 Server
The original presentation’s Reservation Service used an embedded instance of H2. To scale out the Reservation Service, we need a common database for multiple instances to share. Otherwise, queries would return different results, specific to the particular instance of Reservation Service chosen by the load-balancer. To solve this, the original presentation’s embedded version of H2 has been replaced with the TCP Server client/server version of H2.

Thanks to more Spring magic, the only change we need to make to the original presentation’s code is a few additional properties added to the Reservation Service’s reservation-service.properties file. This changes H2 from the embedded version to the TCP Server version.
| # reservation service app props | |
| message=Spring Cloud Config: Reservation Service\n | |
| # h2 database server | |
| spring.datasource.url=jdbc:h2:tcp://localhost/~/reservationdb | |
| spring.datasource.username=dbuser | |
| spring.datasource.password=dbpass | |
| spring.datasource.driver-class-name=org.h2.Driver | |
| spring.jpa.hibernate.ddl-auto=validate | |
| # spring cloud stream / redis | |
| spring.cloud.stream.bindings.input=reservations | |
| spring.redis.host=192.168.99.100 | |
| spring.redis.port=6379 | |
| # zipkin / spring cloud sleuth | |
| spring.zipkin.host=192.168.99.100 | |
| spring.zipkin.port=9410 |
Reservation Data Seeder
In the original presentation, the Reservation Service created several sample reservation records in its embedded H2 database on startup. Since we now have multiple instances of the Reservation Service running, the sample data creation task has been moved from the Reservation Service to the new Reservation Data Seeder. The Reservation Service only now validates the H2 database schema on startup. The Reservation Data Seeder now updates the schema based on its entities. This also means the seed data will be persisted across restarts of the Reservation Service, unlike in the original configuration.
| # reservation data seeder app props | |
| # h2 database server | |
| spring.datasource.url=jdbc:h2:tcp://localhost/~/reservationdb | |
| spring.datasource.username=dbuser | |
| spring.datasource.password=dbpass | |
| spring.datasource.driver-class-name=org.h2.Driver | |
| spring.h2.console.enabled=true | |
| spring.jpa.hibernate.ddl-auto=update |
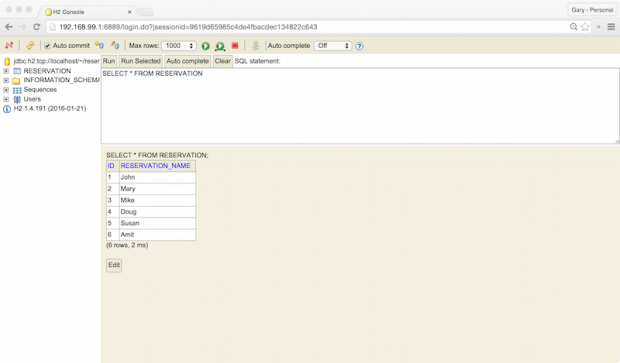
Running the Reservation Data Seeder once will create several reservation records into the H2 database. To confirm the H2 Server is running and the initial reservation records were created by the Reservation Data Seeder, point your web browser to the H2 login page at http://192.168.99.1:6889. and log in using the credentials in the reservation-service.properties file.

The H2 Console should contain the RESERVATION table, which holds the reservation sample records.
Spring Cloud Sleuth and Twitter’s Zipkin
According to the project description, “Spring Cloud Sleuth implements a distributed tracing solution for Spring Cloud. All your interactions with external systems should be instrumented automatically. You can capture data simply in logs, or by sending it to a remote collector service.” In our case, that remote collector service is Zipkin.
Zipkin describes itself as, “a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems in microservice architectures. It manages both the collection and lookup of this data through a Collector and a Query service.” Zipkin provides critical insights into how microservices perform in a distributed system.

In the presentation, as in this post, the Reservation Client’s main ReservationClientApplication class contains the alwaysSampler bean, which returns a new instance of org.springframework.cloud.sleuth.sampler.AlwaysSampler. As long as Spring Cloud Sleuth is on the classpath and you have added alwaysSampler bean, the Reservation Client will automatically generate trace data.
| @Bean | |
| AlwaysSampler alwaysSampler() { | |
| return new AlwaysSampler(); | |
| } |
Sending a request to the Reservation Client’s service/message endpoint (http://localhost:8050/reservations/service-message,), will generate a trace, composed of spans. in this case, the spans are individual segments of the HTTP request/response lifecycle. Traces are sent by Sleuth to Zipkin, to be collected. According to Spring, if spring-cloud-sleuth-zipkin is available, then the application will generate and collect Zipkin-compatible traces using Brave). By default, it sends them via Apache Thrift to a Zipkin collector service on port 9410.
Zipkin’s web-browser interface, running on port 8080, allows us to view traces and drill down into individual spans.

Zipkin contains fine-grain details about each span within a trace, as shown below.

Correlation IDs
Note the x-trace-id and x-span-id in the request header, shown below. Sleuth injects the trace and span IDs to the SLF4J MDC (Simple Logging Facade for Java – Mapped Diagnostic Context). According to Spring, IDs provides the ability to extract all the logs from a given trace or span in a log aggregator. The use of correlation IDs and log aggregation are essential for monitoring and supporting a microservice architecture.

Hystix and Hystrix Dashboard
The last major technology highlighted in the presentation is Netflix’s Hystrix. According to Netflix, “Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems, services, and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.” Hystrix is essential, it protects applications from cascading dependency failures, an issue common to complex distributed architectures, with multiple dependency chains. According to Netflix, Hystrix uses multiple isolation techniques, such as bulkhead, swimlane, and circuit breaker patterns, to limit the impact of any one dependency on the entire system.
The presentation demonstrates one of the simpler capabilities of Hystrix, fallback. The getReservationNames method is decorated with the @HystrixCommand annotation. This annotation contains the fallbackMethod. According to Netflix, a graceful degradation of a method is provided by adding a fallback method. Hystrix will call to obtain a default value or values, in case the main command fails. In the presentation’s example, the Reservation Service, a direct dependency of the Reservation Client, has failed. The Reservation Service failure causes the failure of the Reservation Client.
In the presentation’s example, the Reservation Service, a direct dependency of the Reservation Client, has failed. The Reservation Service failure causes the failure of the Reservation Client’s getReservationNames method to return a collection of reservation names. Hystrix redirects the application to the getReservationNameFallback method. Instead of returning a collection of reservation names, the getReservationNameFallback returns an empty collection, as opposed to an error message to the client.
| public Collection<String> getReservationNameFallback() { | |
| return emptyList(); | |
| } | |
| @HystrixCommand(fallbackMethod = "getReservationNameFallback", commandProperties = { | |
| @HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "3000") | |
| }) | |
| @RequestMapping(path = "/names", method = RequestMethod.GET) | |
| public Collection<String> getReservationNames() { | |
| ParameterizedTypeReference<Resources<Reservation>> ptr = | |
| new ParameterizedTypeReference<Resources<Reservation>>() { | |
| }; | |
| return this.restTemplate.exchange( | |
| "http://reservation-service/reservations", GET, null, ptr) | |
| .getBody() | |
| .getContent() | |
| .stream() | |
| .map(Reservation::getReservationName) | |
| .collect(toList()); | |
| } |
A more relevant example involves Netflix movie recommendation service. In the event a failure of the recommendation service’s method to return a collection of personalized list of movie recommendations to a customer, Hystrix fallbacks to a method that returns a generic list of the most popular movies to the customer. Netflix has determined that, in the event of a failure of their recommendation service, falling back to a generic list of movies is better than returning no movies at all.
The Hystrix Dashboard is a tool, available with Hystrix, to visualize the current state of Hystrix instrumented methods. Although visually simplistic, the dashboard effectively presents the health of calls to external systems, which are wrapped in a HystrixCommand or HystrixObservableCommand.

The Hystrix dashboard is a visual representation of the Hystrix Stream. This stream is a live feed of data sent by the Hystrix instrumented application, in this case, the Reservation Client. For a single Hystrix application, such as the Reservation Client, the feed requested from the application’s hystrix.stream endpoint is http://localhost:8050/hystrix.stream. The dashboard consumes the stream resource’s response and visualizes it in the browser using JavaScript, jQuery, and d3.
In the post, as in the presentation, hitting the Reservation Client with a volume of requests, we observe normal activity in Hystrix Dashboard. All three instances of the Reservation Service are running and returning the collection of reservations from H2, to the Reservation Client.

If all three instances of the Reservation Service fail or the maximum latency is exceeded, the Reservation Client falls back to returning an empty collection in the response body. In the example below, 15 requests, representing 100% of the current traffic, to the getReservationNames method failed and subsequently fell back to return an empty collection. Hystrix succeeded in helping the application gracefully fall back to an alternate response.

Conclusion
It’s easy to see how Spring Cloud and Netflix’s technologies are easily combined to create a performant, horizontally scalable, reliable system. With the addition of a few missing components, such metrics monitoring and log aggregation, this example could easily be scaled up to support a production-grade microservices-based, enterprise software platform.
Gary Stafford
AWS Area Principal Solutions Architect | 10x AWS Certified Pro | DevOps | Data/ML | Serverless | Polyglot Developer | Former ThoughtWorks and Accenture
