Posts Tagged Spring
Eventual Consistency with Spring for Apache Kafka: Part 2 of 2
Posted by Gary A. Stafford in Java Development, Kubernetes on May 22, 2021
Using Spring for Apache Kafka to manage a Distributed Data Model in MongoDB across multiple microservices
As discussed in Part One of this post, given a modern distributed system composed of multiple microservices, each possessing a sub-set of a domain’s aggregate data, the system will almost assuredly have some data duplication. Given this duplication, how do we maintain data consistency? In this two-part post, we explore one possible solution to this challenge — Apache Kafka and the model of eventual consistency.
Part Two
In Part Two of this post, we will review how to deploy and run the storefront API components in a local development environment running on Kubernetes with Istio, using minikube. For simplicity’s sake, we will only run a single instance of each service. Additionally, we are not implementing custom domain names, TLS/HTTPS, authentication and authorization, API keys, or restricting access to any sensitive operational API endpoints or ports, all of which we would certainly do in an actual production environment.
To provide operational visibility, we will add Yahoo’s CMAK (Cluster Manager for Apache Kafka), Mongo Express, Kiali, Prometheus, and Grafana to our system.

Prerequisites
This post will assume a basic level of knowledge of Kubernetes, minikube, Docker, and Istio. Furthermore, the post assumes you have already installed recent versions of minikube, kubectl, Docker, and Istio. Meaning, that the kubectl, istioctl, docker, and minikube commands are all available from the terminal.
For this post demonstration, I am using an Apple MacBook Pro running macOS as my development machine. I have the latest versions of Docker Desktop, minikube, kubectl, and Istio installed as of May 2021.
Source Code
The source code for this post is open-source and is publicly available on GitHub. Clone the GitHub project using the following command:
clone --branch 2021-istio \
--single-branch --depth 1 \
https://github.com/garystafford/storefront-demo.git
Minikube
Part of the Kubernetes project, minikube is local Kubernetes, focusing on making it easy to learn and develop for Kubernetes. Minikube quickly sets up a local Kubernetes cluster on macOS, Linux, and Windows. Given the number of Kubernetes resources we will be deploying to minikube, I would recommend at least 3 CPUs and 4–5 GBs of memory. If you choose to deploy multiple observability tools, you may want to increase both of these resources if you can afford it. I maxed out both CPUs and memory several times while setting up this demonstration, causing temporary lock-ups of minikube.
minikube --cpus 3 --memory 5g --driver=docker start start

The Docker driver allows you to install Kubernetes into an existing Docker install. If you are using Docker, please be aware that you must have at least an equivalent amount of resources allocated to Docker to apportion to minikube.

Before continuing, confirm minikube is up and running and confirm the current context of kubectl is minikube.
minikube status
kubectl config current-context
The statuses should look similar to the following:

Use the eval below command to point your shell to minikube’s docker-daemon. You can confirm this by using the docker image ls and docker container ls command to view running Kubernetes containers on minikube.
eval $(minikube -p minikube docker-env)
docker image ls
docker container ls
The output should look similar to the following:

You can also check the status of minikube from Docker Desktop. Minikube is running as a container, instantiated from a Docker image, gcr.io/k8s-minikube/kicbase. View the container’s Stats, as shown below.

Istio
Assuming you have downloaded and configured Istio, install it onto minikube. I currently have Istio 1.10.0 installed and have theISTIO_HOME environment variable set in my Oh My Zsh .zshrc file. I have also set Istio’s bin/ subdirectory in my PATH environment variable. The bin/ subdirectory contains the istioctl executable.
echo $ISTIO_HOME
> /Applications/Istio/istio-1.10.0
where istioctl
> /Applications/Istio/istio-1.10.0/bin/istioctl
istioctl version
> client version: 1.10.0
control plane version: 1.10.0
data plane version: 1.10.0 (4 proxies)
Istio comes with several built-in configuration profiles. The profiles provide customization of the Istio control plane and of the sidecars for the Istio data plane.
istioctl profile list
> Istio configuration profiles:
default
demo
empty
external
minimal
openshift
preview
remote
For this demonstration, we will use the default profile, which installs istiod and an istio-ingressgateway. We will not require the use of an istio-egressgateway, since all components will be installed locally on minikube.
istioctl install --set profile=default -y
> ✔ Istio core installed
✔ Istiod installed
✔ Ingress gateways installed
✔ Installation complete

Minikube Tunnel
kubectl get svc istio-ingressgateway -n istio-system
To associate an IP address, run the minikube tunnel command in a separate terminal tab. Since it requires opening privileged ports 80 and 443 to be exposed, this command will prompt you for your sudo password.
Services of the type LoadBalancer can be exposed by using the minikube tunnel command. It must be run in a separate terminal window to keep the LoadBalancer running. We previously created the istio-ingressgateway. Run the following command and note that the status of EXTERNAL-IP is <pending>. There is currently no external IP address associated with our LoadBalancer.
minikube tunnel
Rerun the previous command. There should now be an external IP address associated with the LoadBalancer. In my case, 127.0.0.1.
kubectl get svc istio-ingressgateway -n istio-system
The external IP address shown is the address we will use to access the resources we chose to expose externally on minikube.
Minikube Dashboard
Once again, in a separate terminal tab, open the Minikube Dashboard (aka Kubernetes Dashboard).
minikube dashboard
The dashboard will give you a visual overview of all your installed Kubernetes components.

Namespaces
Kubernetes supports multiple virtual clusters backed by the same physical cluster. These virtual clusters are called namespaces. For this demonstration, we will use four namespaces to organize our deployed resources: dev, mongo, kafka, and storefront-kafka-project. The dev namespace is where we will deploy our Storefront API’s microservices: accounts, orders, and fulfillment. We will deploy MongoDB and Mongo Express to the mongo namespace. Lastly, we will use the kafka and storefront-kafka-project namespaces to deploy Apache Kafka to minikube using Strimzi, a Cloud Native Computing Foundation sandbox project, and CMAK.
kubectl apply -f ./minikube/resources/namespaces.yaml
Automatic Sidecar Injection
In order to take advantage of all of Istio’s features, pods in the mesh must be running an Istio sidecar proxy. When you set the istio-injection=enabled label on a namespace and the injection webhook is enabled, any new pods created in that namespace will automatically have a sidecar added to them. Labeling the dev namespace for automatic sidecar injection ensures that our Storefront API’s microservices — accounts, orders, and fulfillment— will have Istio sidecar proxy automatically injected into their pods.
kubectl label namespace dev istio-injection=enabled
MongoDB
Next, deploy MongoDB and Mongo Express to the mongo namespace on minikube. To ensure a successful connection to MongoDB from Mongo Express, I suggest giving MongoDB a chance to start up fully before deploying Mongo Express.
kubectl apply -f ./minikube/resources/mongodb.yaml -n mongo
sleep 60
kubectl apply -f ./minikube/resources/mongo-express.yaml -n mongo
To confirm the success of the deployments, use the following command:
kubectl get services -n mongo
Or use the Kubernetes Dashboard to confirm deployments.
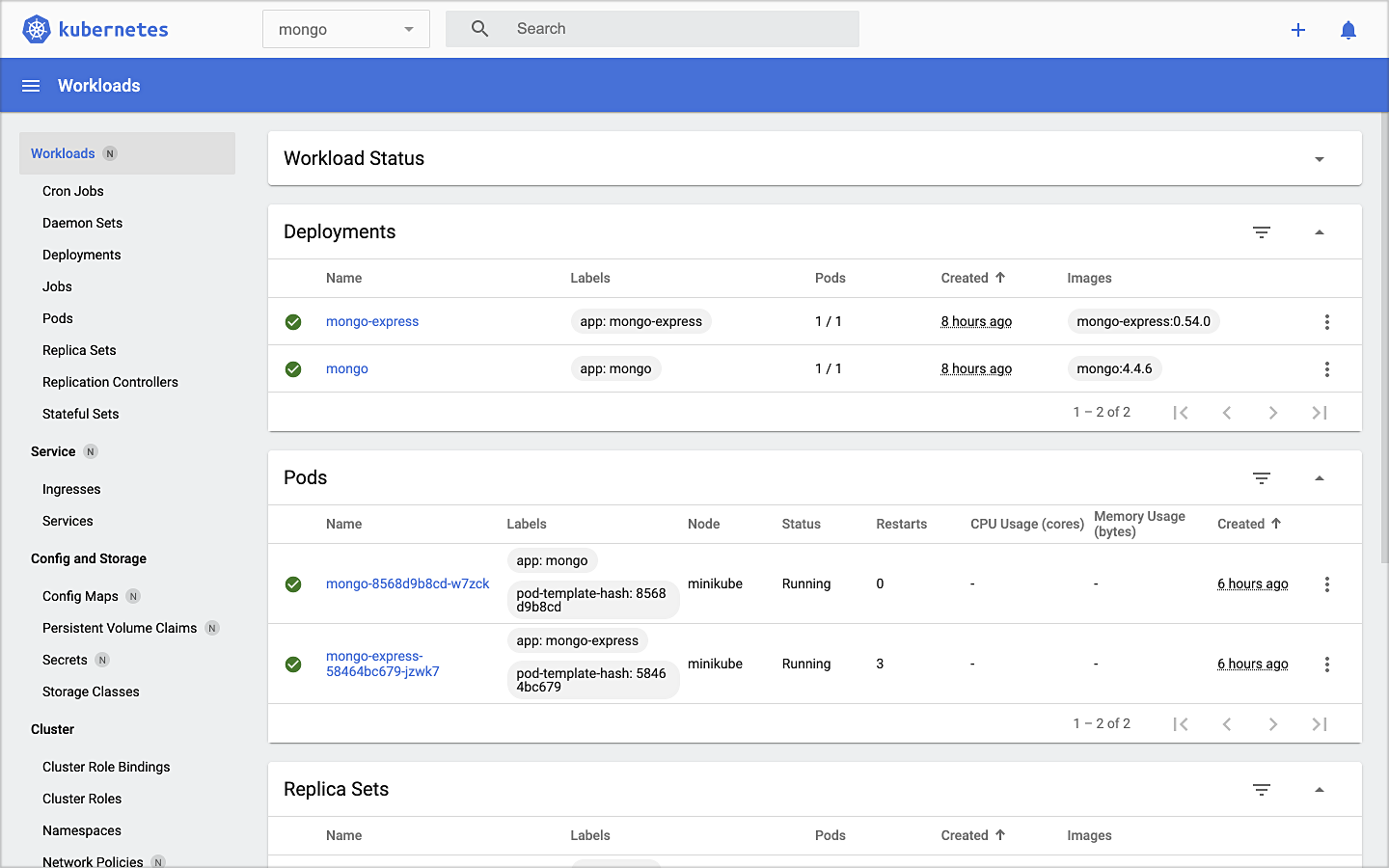
Mongo Express UI Access
For parts of your application (for example, frontends) you may want to expose a Service onto an external IP address outside of your cluster. Kubernetes ServiceTypes allows you to specify what kind of Service you want; the default is ClusterIP.
Note that while MongoDB uses the ClusterIP, Mongo Express uses NodePort. With NodePort, the Service is exposed on each Node’s IP at a static port (the NodePort). You can contact the NodePort Service, from outside the cluster, by requesting <NodeIP>:<NodePort>.
In a separate terminal tab, open Mongo Express using the following command:
minikube service --url mongo-express -n mongo
You should see output similar to the following:

Click on the link to open Mongo Express. There should already be three MongoDB operational databases shown in the UI. The three Storefront databases and collections will be created automatically, later in the post: accounts, orders, and fulfillment.

Apache Kafka using Strimzi
Next, we will install Apache Kafka and Apache Zookeeper into the kafka and storefront-kafka-project namespaces on minikube, using Strimzi. Since Strimzi has a great, easy-to-use Quick Start guide, I will not detail the complete install complete process in this post. I suggest using their guide to understand the process and what each command does. Then, use the slightly modified Strimzi commands I have included below to install Kafka and Zookeeper.
# assuming 0.23.0 is latest version available
curl -L -O https://github.com/strimzi/strimzi-kafka-operator/releases/download/0.23.0/strimzi-0.23.0.zip
unzip strimzi-0.23.0.zip
cd strimzi-0.23.0
sed -i '' 's/namespace: .*/namespace: kafka/' install/cluster-operator/*RoleBinding*.yaml
# manually change STRIMZI_NAMESPACE value to storefront-kafka-project
nano install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml
kubectl create -f install/cluster-operator/ -n kafka
kubectl create -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n storefront-kafka-project
kubectl create -f install/cluster-operator/032-RoleBinding-strimzi-cluster-operator-topic-operator-delegation.yaml -n storefront-kafka-project
kubectl create -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n storefront-kafka-project
kubectl apply -f ../storefront-demo/minikube/resources/strimzi-kafka-cluster.yaml -n storefront-kafka-project
kubectl wait kafka/kafka-cluster --for=condition=Ready --timeout=300s -n storefront-kafka-project
kubectl apply -f ../storefront-demo/minikube/resources/strimzi-kafka-topics.yaml -n storefront-kafka-project
Zoo Entrance
We want to install Yahoo’s CMAK (Cluster Manager for Apache Kafka) to give us a management interface for Kafka. However, CMAK required access to Zookeeper. You can not access Strimzi’s Zookeeper directly from CMAK; this is intentional to avoid performance and security issues. See this GitHub issue for a better explanation of why. We will use the appropriately named Zoo Entrance as a proxy for CMAK to Zookeeper to overcome this challenge.
To install Zoo Entrance, review the GitHub project’s install guide, then use the following commands:
git clone https://github.com/scholzj/zoo-entrance.git
cd zoo-entrance
# optional: change my-cluster to kafka-cluster
sed -i '' 's/my-cluster/kafka-cluster/' deploy.yaml
kubectl apply -f deploy.yaml -n storefront-kafka-project
Cluster Manager for Apache Kafka
Next, install Yahoo’s CMAK (Cluster Manager for Apache Kafka) to give us a management interface for Kafka. Run the following command to deploy CMAK into the storefront-kafka-project namespace.
kubectl apply -f ./minikube/resources/cmak.yaml -n storefront-kafka-project

Similar to Mongo Express, we can access CMAK’s UI using its NodePort. In a separate terminal tab, run the following command:
minikube service --url cmak -n storefront-kafka-project
You should see output similar to Mongo Express. Click on the link provided to access CMAK. Choose ‘Add Cluster’ in CMAK to add our existing Kafka cluster to CMAK’s management interface. Use Zoo Enterence’s service address for the Cluster Zookeeper Hosts value.
zoo-entrance.storefront-kafka-project.svc:2181

Once complete, you should see the three Kafka topics we created previously with Strimzi: accounts.customer.change, fulfillment.order.change, and orders.order.change. Each topic will have three partitions, one replica, and one broker. You should also see the _consumer_offsets topic that Kafka uses to store information about committed offsets for each topic:partition per group of consumers (groupID).

Storefront API Microservices
We are finally ready to install our Storefront API’s microservices into the dev namespace. Each service is preconfigured to access Kafka and MongoDB in their respective namespaces.
kubectl apply -f ./minikube/resources/accounts.yaml -n dev
kubectl apply -f ./minikube/resources/orders.yaml -n dev
kubectl apply -f ./minikube/resources/fulfillment.yaml -n dev
Spring Boot services usually take about two minutes to fully start. The time required to download the Docker Images from docker.com and the start-up time means it could take 3–4 minutes for each of the three services to be ready to accept API traffic.

Istio Components
We want to be able to access our Storefront API’s microservices through our Kubernetes LoadBalancer, while also leveraging all the capabilities of Istio as a service mesh. To do so, we need to deploy an Istio Gateway and a VirtualService. We will also need to deploy DestinationRule resources. A Gateway describes a load balancer operating at the edge of the mesh receiving incoming or outgoing HTTP/TCP connections. A VirtualService defines a set of traffic routing rules to apply when a host is addressed. Lastly, a DestinationRule defines policies that apply to traffic intended for a Service after routing has occurred.
kubectl apply -f ./minikube/resources/destination_rules.yaml -n dev
kubectl apply -f ./minikube/resources/istio-gateway.yaml -n dev
Testing the System and Creating Sample Data
I have provided a Python 3 script that runs a series of seven HTTP GET requests, in a specific order, against the Storefront API. These calls will validate the deployments, confirm the API’s services can access Kafka and MongoDB, generate some initial data, and automatically create the MongoDB database collections from the initial Insert statements.
python3 -m pip install -r ./utility_scripts/requirements.txt -U
python3 ./utility_scripts/refresh.py
The script’s output should be as follows:

If we now look at Mongo Express, we should note three new databases: accounts, orders, and fulfillment.

Observability Tools
Istio makes it easy to integrate with a number of common tools, including cert-manager, Prometheus, Grafana, Kiali, Zipkin, and Jaeger. In order to better observe our Storefront API, we will install three well-known observability tools: Kiali, Prometheus, and Grafana. Luckily, these tools are all included with Istio. You can install any or all of these to minikube. I suggest installing the tools one at a time as not to overwhelm minikube’s CPU and memory resources.
kubectl apply -f ./minikube/resources/prometheus.yaml kubectl apply -f $ISTIO_HOME/samples/addons/grafana.yaml kubectl apply -f $ISTIO_HOME/samples/addons/kiali.yaml
Once deployment is complete, to access any of the UI’s for these tools, use the istioctl dashboard command from a new terminal window:
istioctl dashboard kiali istioctl dashboard prometheus istioctl dashboard grafana
Kiali
Below we see a view of Kiali with API traffic flowing to Kafka and MongoDB.

Prometheus
Each of the three Storefront API microservices has a dependency on Micrometer; specifically, a dependency on micrometer-registry-prometheus. As an instrumentation facade, Micrometer allows you to instrument your code with dimensional metrics with a vendor-neutral interface and decide on the monitoring system as a last step. Instrumenting your core library code with Micrometer allows the libraries to be included in applications that ship metrics to different backends. Given the Micrometer Prometheus dependency, each microservice exposes a /prometheus endpoint (e.g., http://127.0.0.1/accounts/actuator/prometheus) as shown below in Postman.

The /prometheus endpoint exposes dozens of useful metrics and is configured to be scraped by Prometheus. These metrics can be displayed in Prometheus and indirectly in Grafana dashboards via Prometheus. I have customized Istio’s version of Prometheus and included it in the project (prometheus.yaml), which now scrapes the Storefront API’s metrics.
scrape_configs:
- job_name: 'spring_micrometer'
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['accounts.dev:8080','orders.dev:8080','fulfillment.dev:8080']
Here we see an example graph of a Spring Kafka Listener metric, spring_kafka_listener_seconds_sum, in Prometheus. There are dozens of metrics exposed to Prometheus from our system that we can observe and alert on.

Grafana
Lastly, here is an example Spring Boot Dashboard in Grafana. More dashboards are available on Grafana’s community dashboard page. The Grafana dashboard uses Prometheus as the source of its metrics data.

Storefront API Endpoints
The three storefront services are fully functional Spring Boot, Spring Data REST, Spring HATEOAS-enabled applications. Each service exposes a rich set of CRUD endpoints for interacting with the service’s data entities. To better understand the Storefront API, each Spring Boot microservice uses SpringFox, which produces automated JSON API documentation for APIs built with Spring. The service builds also include the springfox-swagger-ui web jar, which ships with Swagger UI. Swagger takes the manual work out of API documentation, with a range of solutions for generating, visualizing, and maintaining API docs.
From a web browser, you can use the /swagger-ui/ subdirectory/subpath with any of the three microservices to access the fully-featured Swagger UI (e.g., http://127.0.0.1/accounts/swagger-ui/).

Each service’s data model (POJOs) is also exposed through the Swagger UI.

Spring Boot Actuator
Additionally, each service includes Spring Boot Actuator. The Actuator exposes additional operational endpoints, allowing us to observe the running services. With Actuator, you get many features, including access to available operational-oriented endpoints, using the /actuator/ subdirectory/subpath (e.g., http://127.0.0.1/accounts/actuator/). For this demonstration, I have not restricted access to any available Actuator endpoints.


Conclusion
In this two-part post, we learned how to build an API using Spring Boot. We ensured the API’s distributed data integrity using a pub/sub model with Spring for Apache Kafka Project. When a relevant piece of data was changed by one microservice, that state change triggered a state change event that was shared with other microservices using Kafka topics.
We also learned how to deploy and run the API in a local development environment running on Kubernetes with Istio, using minikube. We have added production-tested observability tools to provide operational visibility, including CMAK, Mongo Express, Kiali, Prometheus, and Grafana.
This blog represents my own viewpoints and not of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners.
Using Eventual Consistency and Spring for Kafka to Manage a Distributed Data Model: Part 2
Posted by Gary A. Stafford in Enterprise Software Development, Java Development, Software Development on June 18, 2018
** This post has been rewritten and updated in May 2021 **
Given a modern distributed system, composed of multiple microservices, each possessing a sub-set of the domain’s aggregate data they need to perform their functions autonomously, we will almost assuredly have some duplication of data. Given this duplication, how do we maintain data consistency? In this two-part post, we’ve been exploring one possible solution to this challenge, using Apache Kafka and the model of eventual consistency. In Part One, we examined the online storefront domain, the storefront’s microservices, and the system’s state change event message flows.
Part Two
In Part Two of this post, I will briefly cover how to deploy and run a local development version of the storefront components, using Docker. The storefront’s microservices will be exposed through an API Gateway, Netflix’s Zuul. Service discovery and load balancing will be handled by Netflix’s Eureka. Both Zuul and Eureka are part of the Spring Cloud Netflix project. To provide operational visibility, we will add Yahoo’s Kafka Manager and Mongo Express to our system.

Source code for deploying the Dockerized components of the online storefront, shown in this post, is available on GitHub. All Docker Images are available on Docker Hub. I have chosen the wurstmeister/kafka-docker version of Kafka, available on Docker Hub; it has 580+ stars and 10M+ pulls on Docker Hub. This version of Kafka works well, as long as you run it within a Docker Swarm, locally.
Code samples in this post are displayed as Gists, which may not display correctly on some mobile and social media browsers. Links to gists are also provided.
Deployment Options
For simplicity, I’ve used Docker’s native Docker Swarm Mode to support the deployed online storefront. Docker requires minimal configuration as opposed to other CaaS platforms. Usually, I would recommend Minikube for local development if the final destination of the storefront were Kubernetes in Production (AKS, EKS, or GKE). Alternatively, if the final destination of the storefront was Red Hat OpenShift in Production, I would recommend Minishift for local development.
Docker Deployment
We will break up our deployment into two parts. First, we will deploy everything except our services. We will allow Kafka, MongoDB, Eureka, and the other components to start up fully. Afterward, we will deploy the three online storefront services. The storefront-kafka-docker project on Github contains two Docker Compose files, which are divided between the two tasks.
The middleware Docker Compose file (gist).
| version: '3.2' | |
| services: | |
| zuul: | |
| image: garystafford/storefront-zuul:latest | |
| expose: | |
| - "8080" | |
| ports: | |
| - "8080:8080/tcp" | |
| depends_on: | |
| - kafka | |
| - mongo | |
| - eureka | |
| hostname: zuul | |
| environment: | |
| # LOGGING_LEVEL_ROOT: DEBUG | |
| RIBBON_READTIMEOUT: 3000 | |
| RIBBON_SOCKETTIMEOUT: 3000 | |
| ZUUL_HOST_CONNECT_TIMEOUT_MILLIS: 3000 | |
| ZUUL_HOST_CONNECT_SOCKET_MILLIS: 3000 | |
| networks: | |
| - kafka-net | |
| eureka: | |
| image: garystafford/storefront-eureka:latest | |
| expose: | |
| - "8761" | |
| ports: | |
| - "8761:8761/tcp" | |
| hostname: eureka | |
| networks: | |
| - kafka-net | |
| mongo: | |
| image: mongo:latest | |
| command: --smallfiles | |
| # expose: | |
| # - "27017" | |
| ports: | |
| - "27017:27017/tcp" | |
| hostname: mongo | |
| networks: | |
| - kafka-net | |
| mongo_express: | |
| image: mongo-express:latest | |
| expose: | |
| - "8081" | |
| ports: | |
| - "8081:8081/tcp" | |
| hostname: mongo_express | |
| networks: | |
| - kafka-net | |
| zookeeper: | |
| image: wurstmeister/zookeeper:latest | |
| ports: | |
| - "2181:2181/tcp" | |
| hostname: zookeeper | |
| networks: | |
| - kafka-net | |
| kafka: | |
| image: wurstmeister/kafka:latest | |
| depends_on: | |
| - zookeeper | |
| # expose: | |
| # - "9092" | |
| ports: | |
| - "9092:9092/tcp" | |
| environment: | |
| KAFKA_ADVERTISED_HOST_NAME: kafka | |
| KAFKA_CREATE_TOPICS: "accounts.customer.change:1:1,fulfillment.order.change:1:1,orders.order.fulfill:1:1" | |
| KAFKA_ADVERTISED_PORT: 9092 | |
| KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 | |
| KAFKA_DELETE_TOPIC_ENABLE: "true" | |
| volumes: | |
| - /var/run/docker.sock:/var/run/docker.sock | |
| hostname: kafka | |
| networks: | |
| - kafka-net | |
| kafka_manager: | |
| image: hlebalbau/kafka-manager:latest | |
| ports: | |
| - "9000:9000/tcp" | |
| expose: | |
| - "9000" | |
| depends_on: | |
| - kafka | |
| environment: | |
| ZK_HOSTS: "zookeeper:2181" | |
| APPLICATION_SECRET: "random-secret" | |
| command: -Dpidfile.path=/dev/null | |
| hostname: kafka_manager | |
| networks: | |
| - kafka-net | |
| networks: | |
| kafka-net: | |
| driver: overlay |
The services Docker Compose file (gist).
| version: '3.2' | |
| services: | |
| accounts: | |
| image: garystafford/storefront-accounts:latest | |
| depends_on: | |
| - kafka | |
| - mongo | |
| hostname: accounts | |
| # environment: | |
| # LOGGING_LEVEL_ROOT: DEBUG | |
| networks: | |
| - kafka-net | |
| orders: | |
| image: garystafford/storefront-orders:latest | |
| depends_on: | |
| - kafka | |
| - mongo | |
| - eureka | |
| hostname: orders | |
| # environment: | |
| # LOGGING_LEVEL_ROOT: DEBUG | |
| networks: | |
| - kafka-net | |
| fulfillment: | |
| image: garystafford/storefront-fulfillment:latest | |
| depends_on: | |
| - kafka | |
| - mongo | |
| - eureka | |
| hostname: fulfillment | |
| # environment: | |
| # LOGGING_LEVEL_ROOT: DEBUG | |
| networks: | |
| - kafka-net | |
| networks: | |
| kafka-net: | |
| driver: overlay |
In the storefront-kafka-docker project, there is a shell script, stack_deploy_local.sh. This script will execute both Docker Compose files in succession, with a pause in between. You may need to adjust the timing for your own system (gist).
| #!/bin/sh | |
| # Deploys the storefront Docker stack | |
| # usage: sh ./stack_deploy_local.sh | |
| set -e | |
| docker stack deploy -c docker-compose-middleware.yml storefront | |
| echo "Starting the stack: middleware...pausing for 30 seconds..." | |
| sleep 30 | |
| docker stack deploy -c docker-compose-services.yml storefront | |
| echo "Starting the stack: services...pausing for 10 seconds..." | |
| sleep 10 | |
| docker stack ls | |
| docker stack services storefront | |
| docker container ls | |
| echo "Script completed..." | |
| echo "Services may take up to several minutes to start, fully..." |
Start by running docker swarm init. This command will initialize a Docker Swarm. Next, execute the stack deploy script, using an sh ./stack_deploy_local.sh command. The script will deploy a new Docker Stack, within the Docker Swarm. The Docker Stack will hold all storefront components, deployed as individual Docker containers. The stack is deployed within its own isolated Docker overlay network, kafka-net.
Note that we are not using host-based persistent storage for this local development demo. Destroying the Docker stack or the individual Kafka, Zookeeper, or MongoDB Docker containers will result in a loss of data.

Before completion, the stack deploy script runs docker stack ls command, followed by a docker stack services storefront command. You should see one stack, named storefront, with ten services. You should also see each of the ten services has 1/1 replicas running, indicating everything has started or is starting correctly, without failure. Failure would be reflected here as a service having 0/1 replicas.

Before completion, the stack deploy script also runs docker container ls command. You should observe each of the ten running containers (‘services’ in the Docker stack), along with their instance names and ports.

There is also a shell script, stack_delete_local.sh, which will issue a docker stack rm storefront command to destroy the stack when you are done.
Using the names of the storefront’s Docker containers, you can check the start-up logs of any of the components, using the docker logs command.

Testing the Stack
With the storefront stack deployed, we need to confirm that all the components have started correctly and are communicating with each other. To accomplish this, I’ve written a simple Python script, refresh.py. The refresh script has multiple uses. It deletes any existing storefront service MongoDB databases. It also deletes any existing Kafka topics; I call the Kafka Manager’s API to accomplish this. We have no databases or topics since our stack was just created. However, if you are actively developing your data models, you will likely want to purge the databases and topics regularly (gist).
| #!/usr/bin/env python3 | |
| # Delete (3) MongoDB databases, (3) Kafka topics, | |
| # create sample data by hitting Zuul API Gateway endpoints, | |
| # and return MongoDB documents as verification. | |
| # usage: python3 ./refresh.py | |
| from pprint import pprint | |
| from pymongo import MongoClient | |
| import requests | |
| import time | |
| client = MongoClient('mongodb://localhost:27017/') | |
| def main(): | |
| delete_databases() | |
| delete_topics() | |
| create_sample_data() | |
| get_mongo_doc('accounts', 'customer.accounts') | |
| get_mongo_doc('orders', 'customer.orders') | |
| get_mongo_doc('fulfillment', 'fulfillment.requests') | |
| def delete_databases(): | |
| dbs = ['accounts', 'orders', 'fulfillment'] | |
| for db in dbs: | |
| client.drop_database(db) | |
| print('MongoDB dropped: ' + db) | |
| dbs = client.database_names() | |
| print('Reamining databases:') | |
| print(dbs) | |
| print('\n') | |
| def delete_topics(): | |
| # call Kafka Manager API | |
| topics = ['accounts.customer.change', | |
| 'orders.order.fulfill', | |
| 'fulfillment.order.change'] | |
| for topic in topics: | |
| kafka_manager_url = 'http://localhost:9000/clusters/dev/topics/delete?t=' + topic | |
| r = requests.post(kafka_manager_url, data={'topic': topic}) | |
| time.sleep(3) | |
| print('Kafka topic deleted: ' + topic) | |
| print('\n') | |
| def create_sample_data(): | |
| sample_urls = [ | |
| 'http://localhost:8080/accounts/customers/sample', | |
| 'http://localhost:8080/orders/customers/sample/orders', | |
| 'http://localhost:8080/orders/customers/sample/fulfill', | |
| 'http://localhost:8080/fulfillment/fulfillments/sample/process', | |
| 'http://localhost:8080/fulfillment/fulfillments/sample/ship', | |
| 'http://localhost:8080/fulfillment/fulfillments/sample/in-transit', | |
| 'http://localhost:8080/fulfillment/fulfillments/sample/receive'%5D | |
| for sample_url in sample_urls: | |
| r = requests.get(sample_url) | |
| print(r.text) | |
| time.sleep(5) | |
| print('\n') | |
| def get_mongo_doc(db_name, collection_name): | |
| db = client[db_name] | |
| collection = db[collection_name] | |
| pprint(collection.find_one()) | |
| print('\n') | |
| if __name__ == "__main__": | |
| main() |
Next, the refresh script calls a series of RESTful HTTP endpoints, in a specific order, to create sample data. Our three storefront services each expose different endpoints. Different /sample endpoints create sample customers, orders, order fulfillment requests, and shipping notifications. The create sample data endpoints include, in order:
- Sample Customer: /accounts/customers/sample
- Sample Orders: /orders/customers/sample/orders
- Sample Fulfillment Requests: /orders/customers/sample/fulfill
- Sample Processed Order Events: /fulfillment/fulfillment/sample/process
- Sample Shipped Order Events: /fulfillment/fulfillment/sample/ship
- Sample In-Transit Order Events: /fulfillment/fulfillment/sample/in-transit
- Sample Received Order Events: /fulfillment/fulfillment/sample/receive
You can create data on your own by POSTing to the exposed CRUD endpoints on each service. However, given the complex data objects required in the request payloads, it is too time-consuming for this demo.
To execute the script, use a python3 ./refresh.py command. I am using Python 3 in the demo, but the script should also work with Python 2.x if you change shebang.

If everything was successful, the script returns one document from each of the three storefront service’s MongoDB database collections. A result of ‘None’ for any of the MongoDB documents usually indicates one of the earlier commands failed. Given an abnormally high response latency, due to the load of the ten running containers on my laptop, I had to increase the Zuul/Ribbon timeouts.
Observing the System
We should now have the online storefront Docker stack running, three MongoDB databases created and populated with sample documents (data), and three Kafka topics, which have messages in them. Based on the fact we saw database documents printed out with our refresh script, we know the topics were used to pass data between the message producing and message consuming services.
In most enterprise environments, a developer may not have the access, nor the operational knowledge to interact with Kafka or MongoDB from within a container, on the command line. So how else can we interact with the system?
Kafka Manager
Kafka Manager gives us the ability to interact with Kafka via a convenient browser-based user interface. For this demo, the Kafka Manager UI is available on the default port 9000.

To make Kafka Manager useful, define the Kafka cluster. The Cluster Name is up to you. The Cluster Zookeeper Host should be zookeeper:2181, for our demo.

Kafka Manager gives us useful insights into many aspects of our simple, single-broker cluster. You should observe three topics, created during the deployment of Kafka.

Kafka Manager is an appealing alternative, as opposed to connecting with the Kafka container, with a docker exec command, to interact with Kafka. A typical use case might be deleting a topic or adding partitions to a topic. We can also see which Consumers are consuming which topics, from within Kafka Manager.

Mongo Express
Similar to Kafka Manager, Mongo Express gives us the ability to interact with Kafka via a user interface. For this demo, the Mongo Express browser-based user interface is available on the default port 8081. The initial view displays each of the existing databases. Note our three service’s databases, including accounts, orders, and fulfillment.

Drilling into an individual database, we can view each of the database’s collections. Digging in further, we can interact with individual database collection documents.

We may even edit and save the documents.

SpringFox and Swagger
Each of the storefront services also implements SpringFox, the automated JSON API documentation for API’s built with Spring. With SpringFox, each service exposes a rich Swagger UI. The Swagger UI allows us to interact with service endpoints.
Since each service exposes its own Swagger interface, we must access them through the Zuul API Gateway on port 8080. In our demo environment, the Swagger browser-based user interface is accessible at /swagger-ui.html. Below is a fully self-documented Orders service API, as seen through the Swagger UI.
I believe there are still some incompatibilities with the latest SpringFox release and Spring Boot 2, which prevents Swagger from showing the default Spring Data REST CRUD endpoints. Currently, you only see the API endpoints you explicitly declare in your Controller classes.

The service’s data models (POJOs) are also exposed through the Swagger UI by default. Below we see the Orders service’s models.

The Swagger UI allows you to drill down into the complex structure of the models, such as the CustomerOrder entity, exposing each of the entity’s nested data objects.

Spring Cloud Netflix Eureka
This post does not cover the use of Eureka or Zuul. Eureka gives us further valuable insight into our storefront system. Eureka is our systems service registry and provides load-balancing for our services if we have multiple instances.
For this demo, the Eureka browser-based user interface is available on the default port 8761. Within the Eureka user interface, we should observe the three storefront services and Zuul, the API Gateway, registered with Eureka. If we had more than one instance of each service, we would see all of them listed here.

Although of limited use in a local environment, we can observe some general information about our host.

Interacting with the Services
The three storefront services are fully functional Spring Boot / Spring Data REST / Spring HATEOAS-enabled applications. Each service exposes a rich set of CRUD endpoints for interacting with the service’s data entities. Additionally, each service includes Spring Boot Actuator. Actuator exposes additional operational endpoints, allowing us to observe the running services. Again, this post is not intended to be a demonstration of Spring Boot or Spring Boot Actuator.
Using an application such as Postman, we can interact with our service’s RESTful HTTP endpoints. As shown below, we are calling the Account service’s customers resource. The Accounts request is proxied through the Zuul API Gateway.

The above Postman Storefront Collection and Postman Environment are both exported and saved with the project.
Some key endpoints to observe the entities that were created using Event-Carried State Transfer are shown below. They assume you are using localhost as a base URL.
- Zuul Registered Routes: /actuator/routes
- Accounts Service Customers: /accounts/customers
- Orders Service Customer Orders: /orders/customerOrderses
- Fulfillment Service Fulfillments: /fulfillment/fulfillments
References
Links to my GitHub projects for this post
- storefront-kafka-docker
- storefront-zuul-proxy
- storefront-eureka-server
- storefront-demo-accounts
- storefront-demo-orders
- storefront-demo-fulfillment
Some additional references I found useful while authoring this post and the online storefront code:
- Wurstmeister’s kafka-docker GitHub README
- Spring for Apache Kafka Reference Documentation
- Baeldung’s Intro to Apache Kafka with Spring
- CodeNotFound.com’s Spring Kafka – Consumer Producer Example
- MemoryNotFound’s Spring Kafka – Consumer and Producer Example
All opinions expressed in this post are my own and not necessarily the views of my current or past employers or their clients.
Using Eventual Consistency and Spring for Kafka to Manage a Distributed Data Model: Part 1
Posted by Gary A. Stafford in Enterprise Software Development, Java Development, Software Development on June 17, 2018
** This post has been rewritten and updated in May 2021 **
Given a modern distributed system, composed of multiple microservices, each possessing a sub-set of the domain’s aggregate data they need to perform their functions autonomously, we will almost assuredly have some duplication of data. Given this duplication, how do we maintain data consistency? In this two-part post, we will explore one possible solution to this challenge, using Apache Kafka and the model of eventual consistency.
I previously covered the topic of eventual consistency in a distributed system, using RabbitMQ, in the post, Eventual Consistency: Decoupling Microservices with Spring AMQP and RabbitMQ. This post is featured on Pivotal’s RabbitMQ website.
Introduction
To ground the discussion, let’s examine a common example of the online storefront. Using a domain-driven design (DDD) approach, we would expect our problem domain, the online storefront, to be composed of multiple bounded contexts. Bounded contexts would likely include Shopping, Customer Service, Marketing, Security, Fulfillment, Accounting, and so forth, as shown in the context map, below.

Given this problem domain, we can assume we have the concept of the Customer. Further, the unique properties that define a Customer are likely to be spread across several bounded contexts. A complete view of a Customer would require you to aggregate data from multiple contexts. For example, the Accounting context may be the system of record (SOR) for primary customer information, such as the customer’s name, contact information, contact preferences, and billing and shipping addresses. Marketing may possess additional information about the customer’s use of the store’s loyalty program. Fulfillment may maintain a record of all the orders shipped to the customer. Security likely holds the customer’s access credentials and privacy settings.
Below, Customer data objects are shown in yellow. Orange represents logical divisions of responsibility within each bounded context. These divisions will manifest themselves as individual microservices in our online storefront example. 
Distributed Data Consistency
If we agree that the architecture of our domain’s data model requires some duplication of data across bounded contexts, or even between services within the same contexts, then we must ensure data consistency. Take, for example, a change in a customer’s address. The Accounting context is the system of record for the customer’s addresses. However, to fulfill orders, the Shipping context might also need to maintain the customer’s address. Likewise, the Marketing context, who is responsible for direct-mail advertising, also needs to be aware of the address change, and update its own customer records.
If a piece of shared data is changed, then the party making the change should be responsible for communicating the change, without the expectation of a response. They are stating a fact, not asking a question. Interested parties can choose if, and how, to act upon the change notification. This decoupled communication model is often described as Event-Carried State Transfer, as defined by Martin Fowler, of ThoughtWorks, in his insightful post, What do you mean by “Event-Driven”?. A change to a piece of data can be thought of as a state change event. Coincidentally, Fowler also uses a customer’s address change as an example of Event-Carried State Transfer. The Event-Carried State Transfer Pattern is also detailed by fellow ThoughtWorker and noted Architect, Graham Brooks.
Consistency Strategies
Multiple architectural approaches could be taken to solve for data consistency in a distributed system. For example, you could use a single relational database to persist all data, avoiding the distributed data model altogether. Although I would argue, using a single database just turned your distributed system back into a monolith.
You could use Change Data Capture (CDC) to track changes to each database and send a record of those changes to Kafka topics for consumption by interested parties. Kafka Connect is an excellent choice for this, as explained in the article, No More Silos: How to Integrate your Databases with Apache Kafka and CDC, by Robin Moffatt of Confluent.
Alternately, we could use a separate data service, independent of the domain’s other business services, whose sole role is to ensure data consistency across domains. If messages are persisted in Kafka, the service have the added ability to provide data auditability through message replay. Of course, another set of services adds additional operational complexity.
Storefront Example
In this post, our online storefront’s services will be built using Spring Boot. Thus, we will ensure the uniformity of distributed data by using a Publish/Subscribe model with the Spring for Apache Kafka Project. When a piece of data is changed by one Spring Boot service, if appropriate, that state change will trigger an event, which will be shared with other services using Kafka topics.
We will explore different methods of leveraging Spring Kafka to communicate state change events, as they relate to the specific use case of a customer placing an order through the online storefront. An abridged view of the storefront ordering process is shown in the diagram below. The arrows represent the exchange of data. Kafka will serve as a means of decoupling services from each one another, while still ensuring the data is exchanged.

Given the use case of placing an order, we will examine the interactions of three services, the Accounts service within the Accounting bounded context, the Fulfillment service within the Fulfillment context, and the Orders service within the Order Management context. We will examine how the three services use Kafka to communicate state changes (changes to their data) to each other, in a decoupled manner.
The diagram below shows the event flows between sub-systems discussed in the post. The numbering below corresponds to the numbering in the ordering process above. We will look at event flows 2, 5, and 6. We will simulate event flow 3, the order being created by the Shopping Cart service. Kafka Producers may also be Consumers within our domain.

Below is a view of the online storefront, through the lens of the major sub-systems involved. Although the diagram is overly simplified, it should give you the idea of where Kafka, and Zookeeper, Kafka’s cluster manager, might sit in a typical, highly-available, microservice-based, distributed, application platform.

This post will focus on the storefront’s services, database, and messaging sub-systems.

Storefront Microservices
First, we will explore the functionality of each of the three microservices. We will examine how they share state change events using Kafka. Each storefront service is built using Spring Boot 2.0 and Gradle. Each Spring Boot service includes Spring Data REST, Spring Data MongoDB, Spring for Apache Kafka, Spring Cloud Sleuth, SpringFox, Spring Cloud Netflix Eureka, and Spring Boot Actuator. For simplicity, Kafka Streams and the use of Spring Cloud Stream is not part of this post.
Code samples in this post are displayed as Gists, which may not display correctly on some mobile and social media browsers. Links to gists are also provided.
Accounts Service
The Accounts service is responsible for managing basic customer information, such as name, contact information, addresses, and credit cards for purchases. A partial view of the data model for the Accounts service is shown below. This cluster of domain objects represents the Customer Account Aggregate.

The Customer class, the Accounts service’s primary data entity, is persisted in the Accounts MongoDB database. A Customer, represented as a BSON document in the customer.accounts database collection, looks as follows (gist).
| { | |
| "_id": ObjectId("5b189af9a8d05613315b0212"), | |
| "name": { | |
| "title": "Mr.", | |
| "firstName": "John", | |
| "middleName": "S.", | |
| "lastName": "Doe", | |
| "suffix": "Jr." | |
| }, | |
| "contact": { | |
| "primaryPhone": "555-666-7777", | |
| "secondaryPhone": "555-444-9898", | |
| "email": "john.doe@internet.com" | |
| }, | |
| "addresses": [{ | |
| "type": "BILLING", | |
| "description": "My cc billing address", | |
| "address1": "123 Oak Street", | |
| "city": "Sunrise", | |
| "state": "CA", | |
| "postalCode": "12345-6789" | |
| }, | |
| { | |
| "type": "SHIPPING", | |
| "description": "My home address", | |
| "address1": "123 Oak Street", | |
| "city": "Sunrise", | |
| "state": "CA", | |
| "postalCode": "12345-6789" | |
| } | |
| ], | |
| "creditCards": [{ | |
| "type": "PRIMARY", | |
| "description": "VISA", | |
| "number": "1234-6789-0000-0000", | |
| "expiration": "6/19", | |
| "nameOnCard": "John S. Doe" | |
| }, | |
| { | |
| "type": "ALTERNATE", | |
| "description": "Corporate American Express", | |
| "number": "9999-8888-7777-6666", | |
| "expiration": "3/20", | |
| "nameOnCard": "John Doe" | |
| } | |
| ], | |
| "_class": "com.storefront.model.Customer" | |
| } |
Along with the primary Customer entity, the Accounts service contains a CustomerChangeEvent class. As a Kafka producer, the Accounts service uses the CustomerChangeEvent domain event object to carry state information about the client the Accounts service wishes to share when a new customer is added, or a change is made to an existing customer. The CustomerChangeEvent object is not an exact duplicate of the Customer object. For example, the CustomerChangeEvent object does not share sensitive credit card information with other message Consumers (the CreditCard data object).

Since the CustomerChangeEvent domain event object is not persisted in MongoDB, to examine its structure, we can look at its JSON message payload in Kafka. Note the differences in the data structure between the Customer document in MongoDB and the Kafka CustomerChangeEvent message payload (gist).
| { | |
| "id": "5b189af9a8d05613315b0212", | |
| "name": { | |
| "title": "Mr.", | |
| "firstName": "John", | |
| "middleName": "S.", | |
| "lastName": "Doe", | |
| "suffix": "Jr." | |
| }, | |
| "contact": { | |
| "primaryPhone": "555-666-7777", | |
| "secondaryPhone": "555-444-9898", | |
| "email": "john.doe@internet.com" | |
| }, | |
| "addresses": [{ | |
| "type": "BILLING", | |
| "description": "My cc billing address", | |
| "address1": "123 Oak Street", | |
| "address2": null, | |
| "city": "Sunrise", | |
| "state": "CA", | |
| "postalCode": "12345-6789" | |
| }, { | |
| "type": "SHIPPING", | |
| "description": "My home address", | |
| "address1": "123 Oak Street", | |
| "address2": null, | |
| "city": "Sunrise", | |
| "state": "CA", | |
| "postalCode": "12345-6789" | |
| }] | |
| } |
For simplicity, we will assume other services do not make changes to the customer’s name, contact information, or addresses. It is the sole responsibility of the Accounts service.
Source code for the Accounts service is available on GitHub.
Orders Service
The Orders service is responsible for managing a customer’s past and current orders; it is the system of record for the customer’s order history. A partial view of the data model for the Orders service is shown below. This cluster of domain objects represents the Customer Orders Aggregate.

The CustomerOrders class, the Order service’s primary data entity, is persisted in MongoDB. This entity contains a history of all the customer’s orders (Order data objects), along with the customer’s name, contact information, and addresses. In the Orders MongoDB database, a CustomerOrders, represented as a BSON document in the customer.orders database collection, looks as follows (gist).
| { | |
| "_id": ObjectId("5b189af9a8d05613315b0212"), | |
| "name": { | |
| "title": "Mr.", | |
| "firstName": "John", | |
| "middleName": "S.", | |
| "lastName": "Doe", | |
| "suffix": "Jr." | |
| }, | |
| "contact": { | |
| "primaryPhone": "555-666-7777", | |
| "secondaryPhone": "555-444-9898", | |
| "email": "john.doe@internet.com" | |
| }, | |
| "addresses": [{ | |
| "type": "BILLING", | |
| "description": "My cc billing address", | |
| "address1": "123 Oak Street", | |
| "city": "Sunrise", | |
| "state": "CA", | |
| "postalCode": "12345-6789" | |
| }, | |
| { | |
| "type": "SHIPPING", | |
| "description": "My home address", | |
| "address1": "123 Oak Street", | |
| "city": "Sunrise", | |
| "state": "CA", | |
| "postalCode": "12345-6789" | |
| } | |
| ], | |
| "orders": [{ | |
| "guid": "df78784f-4d1d-48ad-a3e3-26a4fe7317a4", | |
| "orderStatusEvents": [{ | |
| "timestamp": NumberLong("1528339278058"), | |
| "orderStatusType": "CREATED" | |
| }, | |
| { | |
| "timestamp": NumberLong("1528339278058"), | |
| "orderStatusType": "APPROVED" | |
| }, | |
| { | |
| "timestamp": NumberLong("1528339278058"), | |
| "orderStatusType": "PROCESSING" | |
| }, | |
| { | |
| "timestamp": NumberLong("1528339278058"), | |
| "orderStatusType": "COMPLETED" | |
| } | |
| ], | |
| "orderItems": [{ | |
| "product": { | |
| "guid": "7f3c9c22-3c0a-47a5-9a92-2bd2e23f6e37", | |
| "title": "Green Widget", | |
| "description": "Gorgeous Green Widget", | |
| "price": "11.99" | |
| }, | |
| "quantity": 2 | |
| }, | |
| { | |
| "product": { | |
| "guid": "d01fde07-7c24-49c5-a5f1-bc2ce1f14c48", | |
| "title": "Red Widget", | |
| "description": "Reliable Red Widget", | |
| "price": "3.99" | |
| }, | |
| "quantity": 3 | |
| } | |
| ] | |
| }, | |
| { | |
| "guid": "29692d7f-3ca5-4684-b5fd-51dbcf40dc1e", | |
| "orderStatusEvents": [{ | |
| "timestamp": NumberLong("1528339278058"), | |
| "orderStatusType": "CREATED" | |
| }, | |
| { | |
| "timestamp": NumberLong("1528339278058"), | |
| "orderStatusType": "APPROVED" | |
| } | |
| ], | |
| "orderItems": [{ | |
| "product": { | |
| "guid": "a9d5a5c7-4245-4b4e-b1c3-1d3968f36b2d", | |
| "title": "Yellow Widget", | |
| "description": "Amazing Yellow Widget", | |
| "price": "5.99" | |
| }, | |
| "quantity": 1 | |
| }] | |
| } | |
| ], | |
| "_class": "com.storefront.model.CustomerOrders" | |
| } |
Along with the primary CustomerOrders entity, the Orders service contains the FulfillmentRequestEvent class. As a Kafka producer, the Orders service uses the FulfillmentRequestEvent domain event object to carry state information about an approved order, ready for fulfillment, which it sends to Kafka for consumption by the Fulfillment service. TheFulfillmentRequestEvent object only contains the information it needs to share. In our example, it shares a single Order, along with the customer’s name, contact information, and shipping address.

Since the FulfillmentRequestEvent domain event object is not persisted in MongoDB, we can look at it’s JSON message payload in Kafka. Again, note the structural differences between the CustomerOrders document in MongoDB and the FulfillmentRequestEvent message payload in Kafka (gist).
| { | |
| "timestamp": 1528334218821, | |
| "name": { | |
| "title": "Mr.", | |
| "firstName": "John", | |
| "middleName": "S.", | |
| "lastName": "Doe", | |
| "suffix": "Jr." | |
| }, | |
| "contact": { | |
| "primaryPhone": "555-666-7777", | |
| "secondaryPhone": "555-444-9898", | |
| "email": "john.doe@internet.com" | |
| }, | |
| "address": { | |
| "type": "SHIPPING", | |
| "description": "My home address", | |
| "address1": "123 Oak Street", | |
| "address2": null, | |
| "city": "Sunrise", | |
| "state": "CA", | |
| "postalCode": "12345-6789" | |
| }, | |
| "order": { | |
| "guid": "facb2d0c-4ae7-4d6c-96a0-293d9c521652", | |
| "orderStatusEvents": [{ | |
| "timestamp": 1528333926586, | |
| "orderStatusType": "CREATED", | |
| "note": null | |
| }, { | |
| "timestamp": 1528333926586, | |
| "orderStatusType": "APPROVED", | |
| "note": null | |
| }], | |
| "orderItems": [{ | |
| "product": { | |
| "guid": "7f3c9c22-3c0a-47a5-9a92-2bd2e23f6e37", | |
| "title": "Green Widget", | |
| "description": "Gorgeous Green Widget", | |
| "price": 11.99 | |
| }, | |
| "quantity": 5 | |
| }] | |
| } | |
| } |
Source code for the Orders service is available on GitHub.
Fulfillment Service
Lastly, the Fulfillment service is responsible for fulfilling orders. A partial view of the data model for the Fulfillment service is shown below. This cluster of domain objects represents the Fulfillment Aggregate.

The Fulfillment service’s primary entity, the Fulfillment class, is persisted in MongoDB. This entity contains a single Order data object, along with the customer’s name, contact information, and shipping address. The Fulfillment service also uses the Fulfillment entity to store the latest shipping event, such as ‘Shipped’, ‘In Transit’, and ‘Received’. The customer’s name, contact information, and shipping addresses are managed by the Accounts service, replicated to the Orders service, and passed to the Fulfillment service, via Kafka, using the FulfillmentRequestEvent entity.
In the Fulfillment MongoDB database, a Fulfillment object, represented as a BSON document in the fulfillment.requests database collection, looks as follows (gist).
| { | |
| "_id": ObjectId("5b1bf1b8a8d0562de5133d64"), | |
| "timestamp": NumberLong("1528553706260"), | |
| "name": { | |
| "title": "Ms.", | |
| "firstName": "Susan", | |
| "lastName": "Blackstone" | |
| }, | |
| "contact": { | |
| "primaryPhone": "433-544-6555", | |
| "secondaryPhone": "223-445-6767", | |
| "email": "susan.m.blackstone@emailisus.com" | |
| }, | |
| "address": { | |
| "type": "SHIPPING", | |
| "description": "Home Sweet Home", | |
| "address1": "33 Oak Avenue", | |
| "city": "Nowhere", | |
| "state": "VT", | |
| "postalCode": "444556-9090" | |
| }, | |
| "order": { | |
| "guid": "2932a8bf-aa9c-4539-8cbf-133a5bb65e44", | |
| "orderStatusEvents": [{ | |
| "timestamp": NumberLong("1528558453686"), | |
| "orderStatusType": "RECEIVED" | |
| }], | |
| "orderItems": [{ | |
| "product": { | |
| "guid": "4efe33a1-722d-48c8-af8e-7879edcad2fa", | |
| "title": "Purple Widget" | |
| }, | |
| "quantity": 2 | |
| }, | |
| { | |
| "product": { | |
| "guid": "b5efd4a0-4eb9-4ad0-bc9e-2f5542cbe897", | |
| "title": "Blue Widget" | |
| }, | |
| "quantity": 5 | |
| }, | |
| { | |
| "product": { | |
| "guid": "a9d5a5c7-4245-4b4e-b1c3-1d3968f36b2d", | |
| "title": "Yellow Widget" | |
| }, | |
| "quantity": 2 | |
| } | |
| ] | |
| }, | |
| "shippingMethod": "Drone", | |
| "_class": "com.storefront.model.Fulfillment" | |
| } |
Along with the primary Fulfillment entity, the Fulfillment service has an OrderStatusChangeEvent class. As a Kafka producer, the Fulfillment service uses the OrderStatusChangeEvent domain event object to carry state information about an order’s fulfillment statuses. The OrderStatusChangeEvent object contains the order’s UUID, a timestamp, shipping status, and an option for order status notes.

Since the OrderStatusChangeEvent domain event object is not persisted in MongoDB, to examine it, we can again look at it’s JSON message payload in Kafka (gist).
| { | |
| "guid": "facb2d0c-4ae7-4d6c-96a0-293d9c521652", | |
| "orderStatusEvent": { | |
| "timestamp": 1528334452746, | |
| "orderStatusType": "PROCESSING", | |
| "note": null | |
| } | |
| } |
Source code for the Fulfillment service is available on GitHub.
State Change Event Messaging Flows
There are three state change event messaging flows demonstrated in this post.
- Change to a Customer triggers an event message by the Accounts service;
- Order Approved triggers an event message by the Orders service;
- Change to the status of an Order triggers an event message by the Fulfillment service;
Each of these state change event messaging flows follow the exact same architectural pattern on both the Producer and Consumer sides of the Kafka topic.

Let’s examine each state change event messaging flow and the code behind them.
Customer State Change
When a new Customer entity is created or updated by the Accounts service, a CustomerChangeEvent message is produced and sent to the accounts.customer.change Kafka topic. This message is retrieved and consumed by the Orders service. This is how the Orders service eventually has a record of all customers who may place an order. It can be said that the Order’s Customer contact information is eventually consistent with the Account’s Customer contact information, by way of Kafka.

There are different methods to trigger a message to be sent to Kafka, For this particular state change, the Accounts service uses a listener. The listener class, which extends AbstractMongoEventListener, listens for an onAfterSave event for a Customer entity (gist).
| @Slf4j | |
| @Controller | |
| public class AfterSaveListener extends AbstractMongoEventListener<Customer> { | |
| @Value("${spring.kafka.topic.accounts-customer}") | |
| private String topic; | |
| private Sender sender; | |
| @Autowired | |
| public AfterSaveListener(Sender sender) { | |
| this.sender = sender; | |
| } | |
| @Override | |
| public void onAfterSave(AfterSaveEvent<Customer> event) { | |
| log.info("onAfterSave event='{}'", event); | |
| Customer customer = event.getSource(); | |
| CustomerChangeEvent customerChangeEvent = new CustomerChangeEvent(); | |
| customerChangeEvent.setId(customer.getId()); | |
| customerChangeEvent.setName(customer.getName()); | |
| customerChangeEvent.setContact(customer.getContact()); | |
| customerChangeEvent.setAddresses(customer.getAddresses()); | |
| sender.send(topic, customerChangeEvent); | |
| } | |
| } |
The listener handles the event by instantiating a new CustomerChangeEvent with the Customer’s information and passes it to the Sender class (gist).
| @Slf4j | |
| public class Sender { | |
| @Autowired | |
| private KafkaTemplate<String, CustomerChangeEvent> kafkaTemplate; | |
| public void send(String topic, CustomerChangeEvent payload) { | |
| log.info("sending payload='{}' to topic='{}'", payload, topic); | |
| kafkaTemplate.send(topic, payload); | |
| } | |
| } |
The configuration of the Sender is handled by the SenderConfig class. This Spring Kafka producer configuration class uses Spring Kafka’s JsonSerializer class to serialize the CustomerChangeEvent object into a JSON message payload (gist).
| @Configuration | |
| @EnableKafka | |
| public class SenderConfig { | |
| @Value("${spring.kafka.bootstrap-servers}") | |
| private String bootstrapServers; | |
| @Bean | |
| public Map<String, Object> producerConfigs() { | |
| Map<String, Object> props = new HashMap<>(); | |
| props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); | |
| props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); | |
| props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); | |
| return props; | |
| } | |
| @Bean | |
| public ProducerFactory<String, CustomerChangeEvent> producerFactory() { | |
| return new DefaultKafkaProducerFactory<>(producerConfigs()); | |
| } | |
| @Bean | |
| public KafkaTemplate<String, CustomerChangeEvent> kafkaTemplate() { | |
| return new KafkaTemplate<>(producerFactory()); | |
| } | |
| @Bean | |
| public Sender sender() { | |
| return new Sender(); | |
| } | |
| } |
The Sender uses a KafkaTemplate to send the message to the Kafka topic, as shown below. Since message order is critical to ensure changes to a Customer’s information are processed in order, all messages are sent to a single topic with a single partition.
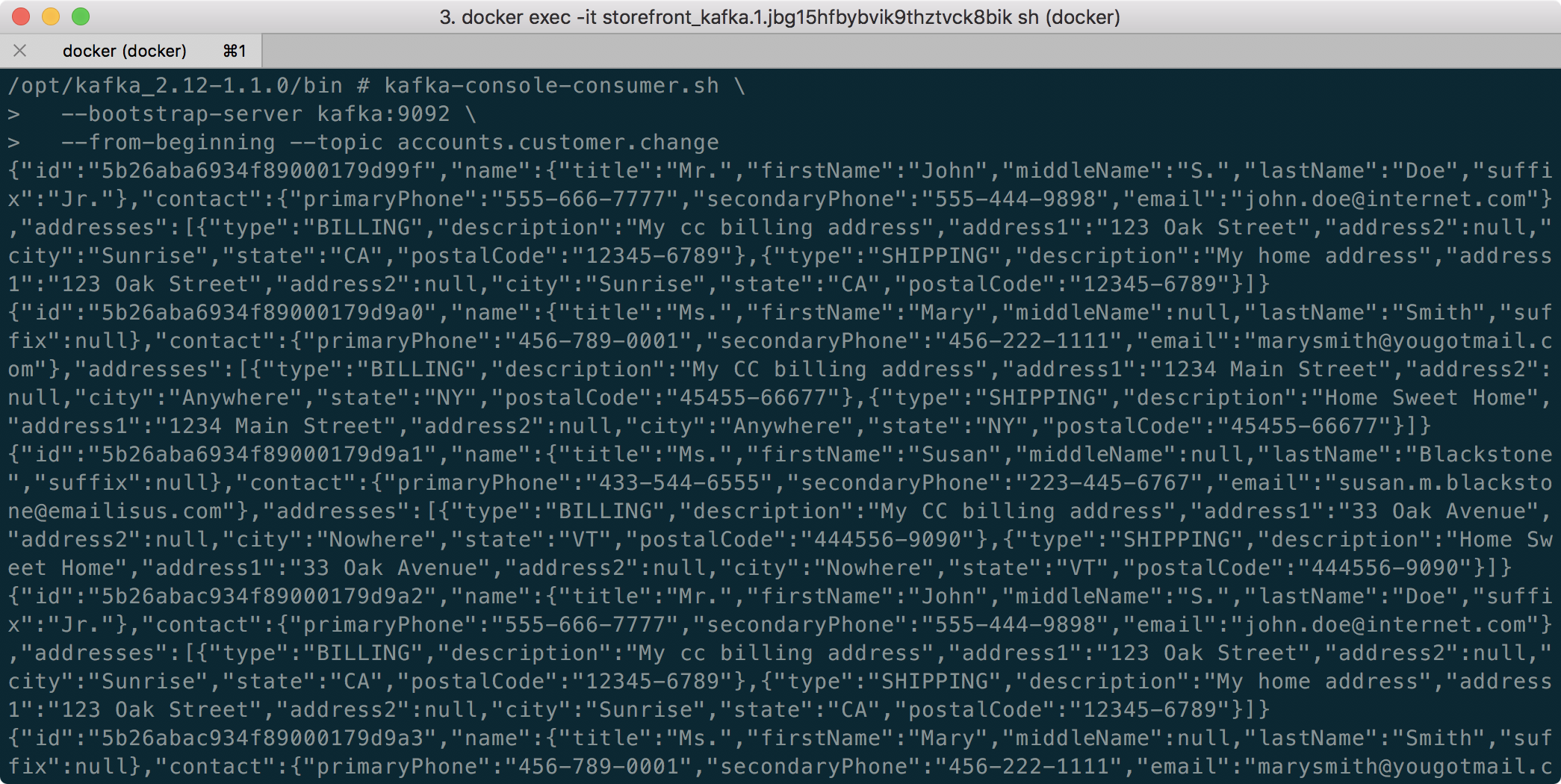
The Orders service’s Receiver class consumes the CustomerChangeEvent messages, produced by the Accounts service (gist).
[gust]cc3c4e55bc291e5435eccdd679d03015[/gist]
The Orders service’s Receiver class is configured differently, compared to the Fulfillment service. The Orders service receives messages from multiple topics, each containing messages with different payload structures. Each type of message must be deserialized into different object types. To accomplish this, the ReceiverConfig class uses Apache Kafka’s StringDeserializer. The Orders service’s ReceiverConfig references Spring Kafka’s AbstractKafkaListenerContainerFactory classes setMessageConverter method, which allows for dynamic object type matching (gist).
| @Configuration | |
| @EnableKafka | |
| public class ReceiverConfigNotConfluent implements ReceiverConfig { | |
| @Value("${spring.kafka.bootstrap-servers}") | |
| private String bootstrapServers; | |
| @Value("${spring.kafka.consumer.group-id}") | |
| private String groupId; | |
| @Value("${spring.kafka.consumer.auto-offset-reset}") | |
| private String autoOffsetReset; | |
| @Override | |
| @Bean | |
| public Map<String, Object> consumerConfigs() { | |
| Map<String, Object> props = new HashMap<>(); | |
| props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); | |
| props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); | |
| props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); | |
| props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); | |
| props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset); | |
| return props; | |
| } | |
| @Override | |
| @Bean | |
| public ConsumerFactory<String, String> consumerFactory() { | |
| return new DefaultKafkaConsumerFactory<>(consumerConfigs(), | |
| new StringDeserializer(), | |
| new StringDeserializer() | |
| ); | |
| } | |
| @Bean | |
| ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() { | |
| ConcurrentKafkaListenerContainerFactory<String, String> factory = | |
| new ConcurrentKafkaListenerContainerFactory<>(); | |
| factory.setConsumerFactory(consumerFactory()); | |
| factory.setMessageConverter(new StringJsonMessageConverter()); | |
| return factory; | |
| } | |
| @Override | |
| @Bean | |
| public Receiver receiver() { | |
| return new Receiver(); | |
| } | |
| } |
Each Kafka topic the Orders service consumes messages from is associated with a method in the Receiver class (shown above). That method accepts a specific object type as input, denoting the object type the message payload needs to be deserialized into. In this way, we can receive multiple message payloads, serialized from multiple object types, and successfully deserialize each type into the correct data object. In the case of a CustomerChangeEvent, the Orders service calls the receiveCustomerOrder method to consume the message and properly deserialize it.
For all services, a Spring application.yaml properties file, in each service’s resources directory, contains the Kafka configuration (gist).
| server: | |
| port: 8080 | |
| spring: | |
| main: | |
| allow-bean-definition-overriding: true | |
| application: | |
| name: orders | |
| data: | |
| mongodb: | |
| uri: mongodb://mongo:27017/orders | |
| kafka: | |
| bootstrap-servers: kafka:9092 | |
| topic: | |
| accounts-customer: accounts.customer.change | |
| orders-order: orders.order.fulfill | |
| fulfillment-order: fulfillment.order.change | |
| consumer: | |
| group-id: orders | |
| auto-offset-reset: earliest | |
| zipkin: | |
| sender: | |
| type: kafka | |
| management: | |
| endpoints: | |
| web: | |
| exposure: | |
| include: '*' | |
| logging: | |
| level: | |
| root: INFO | |
| --- | |
| spring: | |
| config: | |
| activate: | |
| on-profile: local | |
| data: | |
| mongodb: | |
| uri: mongodb://localhost:27017/orders | |
| kafka: | |
| bootstrap-servers: localhost:9092 | |
| server: | |
| port: 8090 | |
| management: | |
| endpoints: | |
| web: | |
| exposure: | |
| include: '*' | |
| logging: | |
| level: | |
| root: DEBUG | |
| --- | |
| spring: | |
| config: | |
| activate: | |
| on-profile: confluent | |
| server: | |
| port: 8080 | |
| logging: | |
| level: | |
| root: INFO | |
| --- | |
| server: | |
| port: 8080 | |
| spring: | |
| config: | |
| activate: | |
| on-profile: minikube | |
| data: | |
| mongodb: | |
| uri: mongodb://mongo.dev:27017/orders | |
| kafka: | |
| bootstrap-servers: kafka-cluster.dev:9092 | |
| management: | |
| endpoints: | |
| web: | |
| exposure: | |
| include: '*' | |
| logging: | |
| level: | |
| root: DEBUG |
Order Approved for Fulfillment
When the status of the Order in a CustomerOrders entity is changed to ‘Approved’ from ‘Created’, a FulfillmentRequestEvent message is produced and sent to the accounts.customer.change Kafka topic. This message is retrieved and consumed by the Fulfillment service. This is how the Fulfillment service has a record of what Orders are ready for fulfillment.

Since we did not create the Shopping Cart service for this post, the Orders service simulates an order approval event, containing an approved order, being received, through Kafka, from the Shopping Cart Service. To simulate order creation and approval, the Orders service can create a random order history for each customer. Further, the Orders service can scan all customer orders for orders that contain both a ‘Created’ and ‘Approved’ order status. This state is communicated as an event message to Kafka for all orders matching those criteria. A FulfillmentRequestEvent is produced, which contains the order to be fulfilled, and the customer’s contact and shipping information. The FulfillmentRequestEvent is passed to the Sender class (gist).
| @Slf4j | |
| public class Sender { | |
| @Autowired | |
| private KafkaTemplate<String, FulfillmentRequestEvent> kafkaTemplate; | |
| public void send(String topic, FulfillmentRequestEvent payload) { | |
| log.info("sending payload='{}' to topic='{}'", payload, topic); | |
| kafkaTemplate.send(topic, payload); | |
| } | |
| } |
The configuration of the Sender class is handled by the SenderConfig class. This Spring Kafka producer configuration class uses the Spring Kafka’s JsonSerializer class to serialize the FulfillmentRequestEvent object into a JSON message payload (gist).
| @Configuration | |
| @EnableKafka | |
| public class SenderConfig { | |
| @Value("${spring.kafka.bootstrap-servers}") | |
| private String bootstrapServers; | |
| @Bean | |
| public Map<String, Object> producerConfigs() { | |
| Map<String, Object> props = new HashMap<>(); | |
| props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); | |
| props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); | |
| props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); | |
| return props; | |
| } | |
| @Bean | |
| public ProducerFactory<String, FulfillmentRequestEvent> producerFactory() { | |
| return new DefaultKafkaProducerFactory<>(producerConfigs()); | |
| } | |
| @Bean | |
| public KafkaTemplate<String, FulfillmentRequestEvent> kafkaTemplate() { | |
| return new KafkaTemplate<>(producerFactory()); | |
| } | |
| @Bean | |
| public Sender sender() { | |
| return new Sender(); | |
| } | |
| } |
The Sender class uses a KafkaTemplate to send the message to the Kafka topic, as shown below. Since message order is not critical messages could be sent to a topic with multiple partitions if the volume of messages required it.
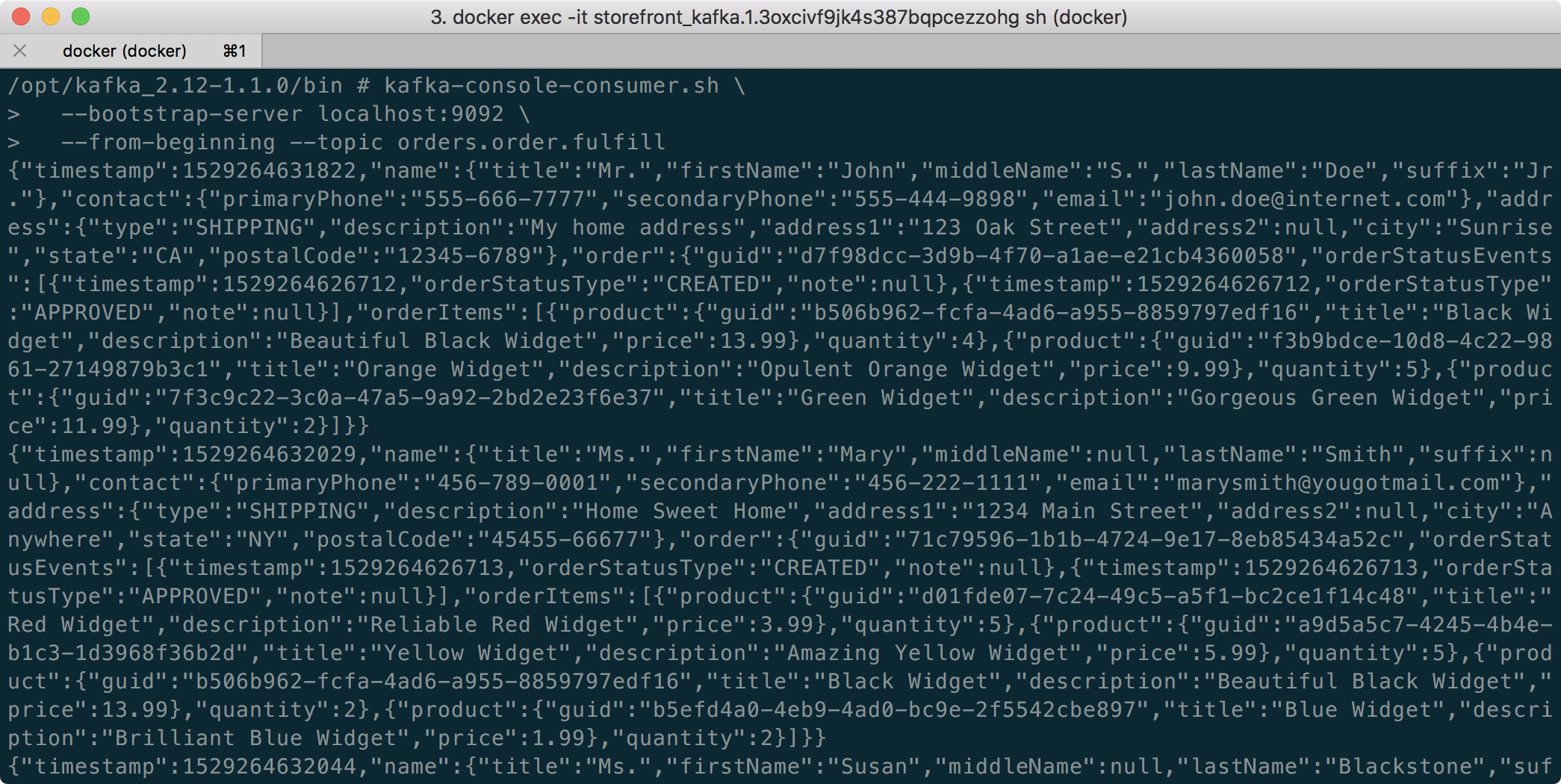
The Fulfillment service’s Receiver class consumes the FulfillmentRequestEvent from the Kafka topic and instantiates a Fulfillment object, containing the data passed in the FulfillmentRequestEvent message payload. This includes the order to be fulfilled and the customer’s contact and shipping information (gist).
| @Slf4j | |
| @Component | |
| public class Receiver { | |
| @Autowired | |
| private FulfillmentRepository fulfillmentRepository; | |
| private CountDownLatch latch = new CountDownLatch(1); | |
| public CountDownLatch getLatch() { | |
| return latch; | |
| } | |
| @KafkaListener(topics = "${spring.kafka.topic.orders-order}") | |
| public void receive(FulfillmentRequestEvent fulfillmentRequestEvent) { | |
| log.info("received payload='{}'", fulfillmentRequestEvent.toString()); | |
| latch.countDown(); | |
| Fulfillment fulfillment = new Fulfillment(); | |
| fulfillment.setId(fulfillmentRequestEvent.getId()); | |
| fulfillment.setTimestamp(fulfillmentRequestEvent.getTimestamp()); | |
| fulfillment.setName(fulfillmentRequestEvent.getName()); | |
| fulfillment.setContact(fulfillmentRequestEvent.getContact()); | |
| fulfillment.setAddress(fulfillmentRequestEvent.getAddress()); | |
| fulfillment.setOrder(fulfillmentRequestEvent.getOrder()); | |
| fulfillmentRepository.save(fulfillment); | |
| } | |
| } |
The Fulfillment service’s ReceiverConfig class defines the DefaultKafkaConsumerFactory and ConcurrentKafkaListenerContainerFactory, responsible for deserializing the message payload from JSON into a FulfillmentRequestEvent object (gist).
| @Configuration | |
| @EnableKafka | |
| public class ReceiverConfigNotConfluent implements ReceiverConfig { | |
| @Value("${spring.kafka.bootstrap-servers}") | |
| private String bootstrapServers; | |
| @Value("${spring.kafka.consumer.group-id}") | |
| private String groupId; | |
| @Value("${spring.kafka.consumer.auto-offset-reset}") | |
| private String autoOffsetReset; | |
| @Override | |
| @Bean | |
| public Map<String, Object> consumerConfigs() { | |
| Map<String, Object> props = new HashMap<>(); | |
| props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); | |
| props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); | |
| props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class); | |
| props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); | |
| props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset); | |
| return props; | |
| } | |
| @Override | |
| @Bean | |
| public ConsumerFactory<String, FulfillmentRequestEvent> consumerFactory() { | |
| return new DefaultKafkaConsumerFactory<>(consumerConfigs(), | |
| new StringDeserializer(), | |
| new JsonDeserializer<>(FulfillmentRequestEvent.class)); | |
| } | |
| @Override | |
| @Bean | |
| public ConcurrentKafkaListenerContainerFactory<String, FulfillmentRequestEvent> kafkaListenerContainerFactory() { | |
| ConcurrentKafkaListenerContainerFactory<String, FulfillmentRequestEvent> factory = | |
| new ConcurrentKafkaListenerContainerFactory<>(); | |
| factory.setConsumerFactory(consumerFactory()); | |
| return factory; | |
| } | |
| @Override | |
| @Bean | |
| public Receiver receiver() { | |
| return new Receiver(); | |
| } | |
| } |
Fulfillment Order Status State Change
When the status of the Order in a Fulfillment entity is changed to anything other than ‘Approved’, an OrderStatusChangeEvent message is produced by the Fulfillment service and sent to the fulfillment.order.change Kafka topic. This message is retrieved and consumed by the Orders service. This is how the Orders service tracks all CustomerOrder lifecycle events from the initial ‘Created’ status to the final happy path ‘Received’ status.

The Fulfillment service exposes several endpoints through the FulfillmentController class, which are simulate a change the status of an order. They allow an order status to be changed from ‘Approved’ to ‘Processing’, to ‘Shipped’, to ‘In Transit’, and to ‘Received’. This change is applied to all orders that meet the criteria.
Each of these state changes triggers a change to the Fulfillment document in MongoDB. Each change also generates an Kafka message, containing the OrderStatusChangeEvent in the message payload. This is handled by the Fulfillment service’s Sender class.
Note in this example, these two events are not handled in an atomic transaction. Either the updating the database or the sending of the message could fail independently, which would cause a loss of data consistency. In the real world, we must ensure both these disparate actions succeed or fail as a single transaction, to ensure data consistency (gist).
| @Slf4j | |
| public class Sender { | |
| @Autowired | |
| private KafkaTemplate<String, OrderStatusChangeEvent> kafkaTemplate; | |
| public void send(String topic, OrderStatusChangeEvent payload) { | |
| log.info("sending payload='{}' to topic='{}'", payload, topic); | |
| kafkaTemplate.send(topic, payload); | |
| } | |
| } |
The configuration of the Sender class is handled by the SenderConfig class. This Spring Kafka producer configuration class uses the Spring Kafka’s JsonSerializer class to serialize the OrderStatusChangeEvent object into a JSON message payload. This class is almost identical to the SenderConfig class in the Orders and Accounts services (gist).
| @Configuration | |
| @EnableKafka | |
| public class SenderConfig { | |
| @Value("${spring.kafka.bootstrap-servers}") | |
| private String bootstrapServers; | |
| @Bean | |
| public Map<String, Object> producerConfigs() { | |
| Map<String, Object> props = new HashMap<>(); | |
| props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); | |
| props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); | |
| props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); | |
| return props; | |
| } | |
| @Bean | |
| public ProducerFactory<String, OrderStatusChangeEvent> producerFactory() { | |
| return new DefaultKafkaProducerFactory<>(producerConfigs()); | |
| } | |
| @Bean | |
| public KafkaTemplate<String, OrderStatusChangeEvent> kafkaTemplate() { | |
| return new KafkaTemplate<>(producerFactory()); | |
| } | |
| @Bean | |
| public Sender sender() { | |
| return new Sender(); | |
| } | |
| } |
The Sender class uses a KafkaTemplate to send the message to the Kafka topic, as shown below. Message order is not critical since a timestamp is recorded, which ensures the proper sequence of order status events can be maintained. Messages could be sent to a topic with multiple partitions if the volume of messages required it.

The Orders service’s Receiver class is responsible for consuming the OrderStatusChangeEvent message, produced by the Fulfillment service (gist).
| @Slf4j | |
| @Component | |
| public class Receiver { | |
| @Autowired | |
| private CustomerOrdersRepository customerOrdersRepository; | |
| @Autowired | |
| private MongoTemplate mongoTemplate; | |
| private CountDownLatch latch = new CountDownLatch(1); | |
| public CountDownLatch getLatch() { | |
| return latch; | |
| } | |
| @KafkaListener(topics = "${spring.kafka.topic.accounts-customer}") | |
| public void receiveCustomerOrder(CustomerOrders customerOrders) { | |
| log.info("received payload='{}'", customerOrders); | |
| latch.countDown(); | |
| customerOrdersRepository.save(customerOrders); | |
| } | |
| @KafkaListener(topics = "${spring.kafka.topic.fulfillment-order}") | |
| public void receiveOrderStatusChangeEvents(OrderStatusChangeEvent orderStatusChangeEvent) { | |
| log.info("received payload='{}'", orderStatusChangeEvent); | |
| latch.countDown(); | |
| Criteria criteria = Criteria.where("orders.guid") | |
| .is(orderStatusChangeEvent.getGuid()); | |
| Query query = Query.query(criteria); | |
| Update update = new Update(); | |
| update.addToSet("orders.$.orderStatusEvents", orderStatusChangeEvent.getOrderStatusEvent()); | |
| mongoTemplate.updateFirst(query, update, "customer.orders"); | |
| } | |
| } |
As explained above, the Orders service is configured differently compared to the Fulfillment service, to receive messages from Kafka. The Orders service needs to receive messages from more than one topic. The ReceiverConfig class deserializes all message using the StringDeserializer. The Orders service’s ReceiverConfig class references the Spring Kafka AbstractKafkaListenerContainerFactory classes setMessageConverter method, which allows for dynamic object type matching (gist).
| @Configuration | |
| @EnableKafka | |
| public class ReceiverConfigNotConfluent implements ReceiverConfig { | |
| @Value("${spring.kafka.bootstrap-servers}") | |
| private String bootstrapServers; | |
| @Value("${spring.kafka.consumer.group-id}") | |
| private String groupId; | |
| @Value("${spring.kafka.consumer.auto-offset-reset}") | |
| private String autoOffsetReset; | |
| @Override | |
| @Bean | |
| public Map<String, Object> consumerConfigs() { | |
| Map<String, Object> props = new HashMap<>(); | |
| props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); | |
| props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); | |
| props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); | |
| props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); | |
| props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset); | |
| return props; | |
| } | |
| @Override | |
| @Bean | |
| public ConsumerFactory<String, String> consumerFactory() { | |
| return new DefaultKafkaConsumerFactory<>(consumerConfigs(), | |
| new StringDeserializer(), | |
| new StringDeserializer() | |
| ); | |
| } | |
| @Bean | |
| ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() { | |
| ConcurrentKafkaListenerContainerFactory<String, String> factory = | |
| new ConcurrentKafkaListenerContainerFactory<>(); | |
| factory.setConsumerFactory(consumerFactory()); | |
| factory.setMessageConverter(new StringJsonMessageConverter()); | |
| return factory; | |
| } | |
| @Override | |
| @Bean | |
| public Receiver receiver() { | |
| return new Receiver(); | |
| } | |
| } |
Each Kafka topic the Orders service consumes messages from is associated with a method in the Receiver class (shown above). This method accepts a specific object type as an input parameter, denoting the object type the message payload needs to be deserialized into. In the case of an OrderStatusChangeEvent message, the receiveOrderStatusChangeEvents method is called to consume a message from the fulfillment.order.change Kafka topic.
Part Two
In Part Two of this post, I will briefly cover how to deploy and run a local development version of the storefront components, using Docker. The storefront’s microservices will be exposed through an API Gateway, Netflix’s Zuul. Service discovery and load balancing will be handled by Netflix’s Eureka. Both Zuul and Eureka are part of the Spring Cloud Netflix project. To provide operational visibility, we will add Yahoo’s Kafka Manager and Mongo Express to our system.
All opinions expressed in this post are my own and not necessarily the views of my current or past employers or their clients.
Deploying Spring Boot Apps to AWS with Netflix Nebula and Spinnaker: Part 2 of 2
Posted by Gary A. Stafford in AWS, Build Automation, Cloud, Continuous Delivery, DevOps, Enterprise Software Development, Java Development, Software Development on May 12, 2018
In Part One of this post, we examined enterprise deployment tools and introduced two of Netflix’s open-source deployment tools, the Nebula Gradle plugins, and Spinnaker. In Part Two, we will deploy a production-ready Spring Boot application, the Election microservice, to multiple Amazon EC2 instances, behind an Elastic Load Balancer (ELB). We will use a fully automated DevOps workflow. The build, test, package, bake, deploy process will be handled by the Netflix Nebula Gradle Linux Packaging Plugin, Jenkins, and Spinnaker. The high-level process will involve the following steps:
- Configure Gradle to build a production-ready fully executable application for Unix systems (executable JAR)
- Using deb-s3 and GPG Suite, create a secure, signed APT (Debian) repository on Amazon S3
- Using Jenkins and the Netflix Nebula plugin, build a Debian package, containing the executable JAR and configuration files
- Using Jenkins and deb-s3, publish the package to the S3-based APT repository
- Using Spinnaker (HashiCorp Packer under the covers), bake an Ubuntu Amazon Machine Image (AMI), replete with the executable JAR installed from the Debian package
- Deploy an auto-scaling set of Amazon EC2 instances from the baked AMI, behind an ELB, running the Spring Boot application using both the Red/Black and Highlander deployment strategies
- Be able to repeat the entire automated build, test, package, bake, deploy process, triggered by a new code push to GitHub
The overall build, test, package, bake, deploy process will look as follows.
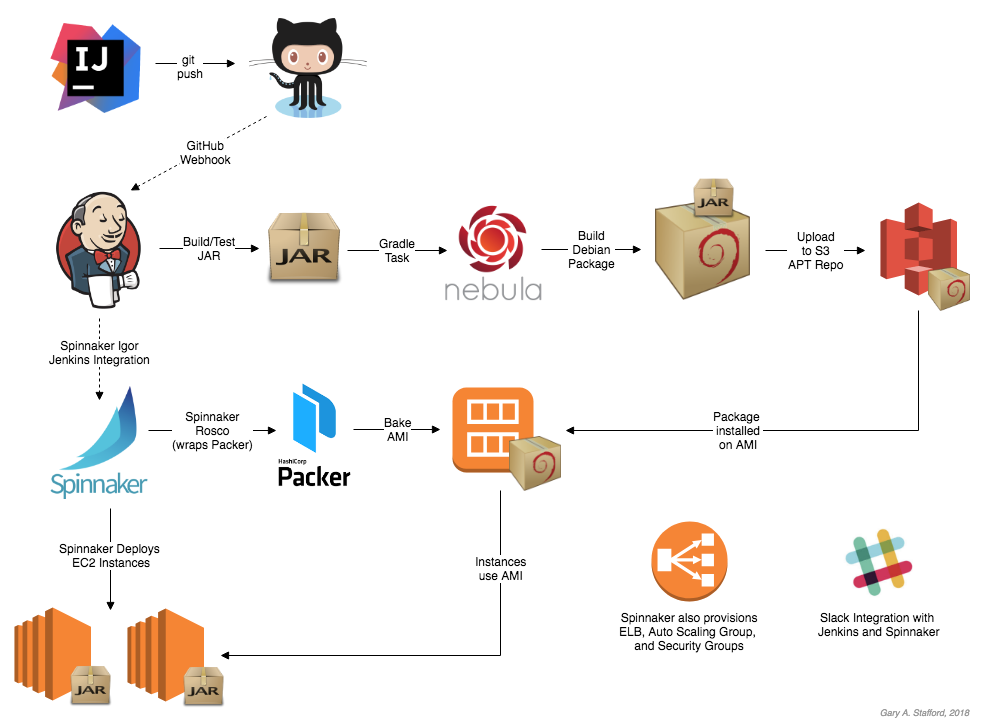
DevOps Architecture
Spinnaker’s modern architecture is comprised of several independent microservices. The codebase is written in Java and Groovy. It leverages the Spring Boot framework¹. Spinnaker’s configuration, startup, updates, and rollbacks are centrally managed by Halyard. Halyard provides a single point of contact for command line interaction with Spinnaker’s microservices.
Spinnaker can be installed on most private or public infrastructure, either containerized or virtualized. Spinnaker has links to a number of Quickstart installations on their website. For this demonstration, I deployed and configured Spinnaker on Azure, starting with one of the Azure Spinnaker quick-start ARM templates. The template provisions all the necessary Azure resources. For better performance, I chose upgraded the default VM to a larger Standard D4 v3, which contains 4 vCPUs and 16 GB of memory. I would recommend at least 2 vCPUs and 8 GB of memory at a minimum for Spinnaker.
Another Azure VM, in the same virtual network as the Spinnaker VM, already hosts Jenkins, SonarQube, and Nexus Repository OSS.
From Spinnaker on Azure, Debian Packages are uploaded to the APT package repository on AWS S3. Spinnaker also bakes Amazon Machine Images (AMI) on AWS. Spinnaker provisions the AWS resources, including EC2 instances, Load Balancers, Auto Scaling Groups, Launch Configurations, and Security Groups. The only resources you need on AWS to get started with Spinnaker are a VPC and Subnets. There are some minor, yet critical prerequisites for naming your VPC and Subnets.
Other external tools include GitHub for source control and Slack for notifications. I have built and managed everything from a Mac, however, all tools are platform agnostic. The Spring Boot application was developed in JetBrains IntelliJ.

Source Code
All source code for this post can be found on GitHub. The project’s README file contains a list of the Election service’s endpoints.
Code samples in this post are displayed as Gists, which may not display correctly on some mobile and social media browsers. Links to gists are also provided.
APT Repository
After setting up Spinnaker on Azure, I created an APT repository on Amazon S3, using the instructions provided by Netflix, in their Code Lab, An Introduction to Spinnaker: Hello Deployment. The setup involves creating an Amazon S3 bucket to serve as an APT (Debian) repository, creating a GPG key for signing, and using deb-s3 to manage the repository. The Code Lab also uses Aptly, a great tool, which I skipped for brevity.

GPG Key
On the Mac, I used GPG Suite to create a GPG (GNU Privacy Guard or GnuPG) automatic signing key for my APT repository. The key is required by Spinnaker to verify the Debian packages in the repository, before installation.
The Ruby Gem, deb-s3, makes management of the Debian packages easy and automatable with Jenkins. Jenkins uploads the Debian packages, using a deb-s3 command, such as the following (gist). In this post, Jenkins calls the command from the shell script, upload-deb-package.sh, which is included in the GitHub project.
| deb-s3 upload \ | |
| --bucket garystafford-spinnaker-repo \ | |
| --access-key-id=$AWS_ACCESS_KEY_ID \ | |
| --secret-access-key=$AWS_SECRET_ACCESS_KEY \ | |
| --arch=amd64 \ | |
| --codename=trusty \ | |
| --component=main \ | |
| --visibility=public \ | |
| --sign=$GPG_KEY_ID \ | |
| build/distributions/*.deb |
The Jenkins user requires access to the signing key, to build and upload the Debian packages. I created my GPG key on my Mac, securely copied the key to my Ubuntu-based Jenkins VM, and then imported the key for the Jenkins user. You could also create your key on Ubuntu, directly. Make sure you backup your private key in a secure location!
Nebula Packaging Plugin
Next, I set up a Gradle task in my build.gradle file to build my Debian packages using the Netflix Nebula Gradle Linux Packaging Plugin. Although Debian packaging tasks could become complex for larger application installations, this task for this post is pretty simple. I used many of the best-practices suggested by Spring for Production-grade deployments. The best-practices guide recommends file location, file modes, and file user and group ownership. I create the JAR as a fully executable JAR, meaning it is started like any other executable and does not have to be started with the standard java -jar command.
In the task, shown below (gist), the JAR and the external configuration file (optional) are copied to specific locations during the deployment and symlinked, as required. I used the older SysVInit system (init.d) to enable the application to automatically starts on boot. You should probably use systemctl for your services with Ubuntu 16.04.
| task packDeb(type: Deb) { | |
| description 'Creates .deb package.' | |
| into '/opt/' + project.name // root directory | |
| from(jar.outputs.files) { // copy *.jar | |
| into 'lib' | |
| fileMode 0500 | |
| user 'springapp' | |
| permissionGroup 'springapp' | |
| } | |
| from('build/resources/main/' + project.name + '.conf') { // copy .conf | |
| into 'conf' | |
| fileMode 0400 | |
| user 'root' | |
| permissionGroup 'root' | |
| } | |
| // symlinks jar to init.d | |
| link('/etc/init.d/election', | |
| '/opt/' + project.name + '/lib/' + jar.archiveName) | |
| // link init.d to rc2.d | |
| link('/opt/' + project.name + '/lib/' + project.name + '-' + project.version + '.conf', | |
| '/opt/' + project.name + '/conf/' + project.name + '.conf') | |
| // link conf to jar location | |
| link('/etc/rc2.d/S02election', '/etc/init.d/election') | |
| postInstall 'chattr +i ' + '/opt/' + project.name + '/lib/' + jar.archiveName | |
| } |
You can use the ar (archive) command (i.e., ar -x spring-postgresql-demo_4.5.0_all.deb), to extract and inspect the structure of a Debian package. The data.tar.gz file, displayed below in Atom, shows the final package structure.

Base AMI
Next, I baked a base AMI for Spinnaker to use. This base AMI is used by Spinnaker to bake (re-bake) the final AMI(s) used for provisioning the EC2 instances, containing the Spring Boot Application. The Spinnaker base AMI is built from another base AMI, the official Ubuntu 16.04 LTS image. I installed the OpenJDK 8 package on the AMI, which is required to run the Java-based Election service. Lastly and critically, I added information about the location of my S3-based APT Debian package repository to the list of configured APT data sources, and the GPG key required for package verification. This information and key will be used later by Spinnaker to bake AMIʼs, using this base AMI. The set-up script, base_ubuntu_ami_setup.sh, which is included in the GitHub project.
| #!/usr/bin/env sh | |
| # based on ami-6dfe5010 | |
| # Canonical, Ubuntu, 16.04 LTS, amd64 xenial image build on 2018-04-05 | |
| # References: | |
| # https://docs.spring.io/spring-boot/docs/current/reference/html/deployment-install.html | |
| # https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/building-shared-amis.html | |
| # https://gist.github.com/justindowning/5921369 | |
| set +x | |
| # update and install java | |
| sudo apt-get update -y \ | |
| && sudo apt-get upgrade -y \ | |
| && sudo apt-get install \ | |
| openjdk-8-jre-headless -y | |
| # a few optional ops tools | |
| sudo apt-get install \ | |
| tree htop glances -y | |
| # user:group application will run as | |
| sudo useradd springapp | |
| sudo usermod -a -G springapp springapp | |
| sudo usermod -s /usr/sbin/nologin springapp | |
| # add s3 deb repo | |
| echo "deb http://garystafford-spinnaker-repo.s3-website-us-east-1.amazonaws.com trusty main" | \ | |
| sudo tee -a /etc/apt/sources.list.d/gary-stafford.list | |
| curl -s https://s3.amazonaws.com/garystafford-spinnaker-repo/apt/doc/apt-key.gpg | \ | |
| sudo apt-key add - | |
| # clean up and secure | |
| sudo passwd -l root | |
| sudo shred -u /etc/ssh/*_key /etc/ssh/*_key.pub | |
| [ -f /home/ubuntu/.ssh/authorized_keys ] && rm /home/ubuntu/.ssh/authorized_keys | |
| sudo rm -rf /tmp/* | |
| cat /dev/null > ~/.bash_history | |
| shred -u ~/.*history | |
| history -c | |
| exit |
Jenkins
This post uses a single Jenkins CI/CD pipeline. Using a Webhook, the pipeline is automatically triggered by every git push to the GitHub project. The pipeline pulls the source code, builds the application, and performs unit-tests and static code analysis with SonarQube. If the build succeeds and the tests pass, the build artifact (JAR file) is bundled into a Debian package using the Nebula Packaging plugin, uploaded to the S3 APT repository using s3-deb, and archived locally for Spinnaker to reference. Once the pipeline is completed, on success or on failure, a Slack notification is sent. The Jenkinsfile, used for this post is available in the project on Github.
| #!/usr/bin/env groovy | |
| def ACCOUNT = "garystafford" | |
| def PROJECT_NAME = "spring-postgresql-demo" | |
| pipeline { | |
| agent any | |
| tools { | |
| gradle 'gradle' | |
| } | |
| stages { | |
| stage('Checkout GitHub') { | |
| steps { | |
| git changelog: true, poll: false, | |
| branch: 'master', | |
| url: "https://github.com/${ACCOUNT}/${PROJECT_NAME}" | |
| } | |
| } | |
| stage('Build') { | |
| steps { | |
| sh 'gradle wrapper' | |
| sh 'LOGGING_LEVEL_ROOT=INFO ./gradlew clean build -x test --info' | |
| } | |
| } | |
| stage('Unit Test') { // unit test against in-memory h2 | |
| steps { | |
| withEnv(['SPRING_DATASOURCE_URL=jdbc:h2:mem:elections']) { | |
| sh 'LOGGING_LEVEL_ROOT=INFO ./gradlew cleanTest test --info' | |
| } | |
| junit '**/build/test-results/test/*.xml' | |
| } | |
| } | |
| stage('SonarQube Analysis') { | |
| steps { | |
| withSonarQubeEnv('sonarqube') { | |
| sh "LOGGING_LEVEL_ROOT=INFO ./gradlew sonarqube -Dsonar.projectName=${PROJECT_NAME} --info" | |
| } | |
| } | |
| } | |
| stage('Build Debian Package') { | |
| steps { | |
| sh "LOGGING_LEVEL_ROOT=INFO ./gradlew packDeb --info" | |
| } | |
| } | |
| stage('Upload Debian Package') { | |
| steps { | |
| withCredentials([ | |
| string(credentialsId: 'GPG_KEY_ID', variable: 'GPG_KEY_ID'), | |
| string(credentialsId: 'AWS_ACCESS_KEY_ID', variable: 'AWS_ACCESS_KEY_ID'), | |
| string(credentialsId: 'AWS_SECRET_ACCESS_KEY', variable: 'AWS_SECRET_ACCESS_KEY')]) { | |
| sh "sh ./scripts/upload-deb-package.sh ${GPG_KEY_ID}" | |
| } | |
| } | |
| } | |
| stage('Archive Debian Package') { | |
| steps { | |
| archiveArtifacts 'build/distributions/*.deb' | |
| } | |
| } | |
| } | |
| post { | |
| success { | |
| slackSend(color: '#79B12B', | |
| message: "SUCCESS: Job '${env.JOB_NAME} [${env.BUILD_NUMBER}]' (${env.BUILD_URL})") | |
| } | |
| failure { | |
| slackSend(color: '#FF0000', | |
| message: "FAILURE: Job '${env.JOB_NAME} [${env.BUILD_NUMBER}]' (${env.BUILD_URL})") | |
| } | |
| } | |
| } |
Below is a traditional Jenkins view of the CI/CD pipeline, with links to unit test reports, SonarQube results, build artifacts, and GitHub source code.

Below is the same pipeline viewed using the Jenkins Blue Ocean plugin.

It is important to perform sufficient testing before building the Debian package. You donʼt want to bake an AMI and deploy EC2 instances, at a cost, before finding out the application has bugs.

Spinnaker Setup
First, I set up a new Spinnaker Slack channel and a custom bot user. Spinnaker details the Slack set up in their Notifications and Events Guide. You can configure what type of Spinnaker events trigger Slack notifications.

AWS Spinnaker User
Next, I added the required Spinnaker User, Policy, and Roles to AWS. Spinnaker uses this access to query and provision infrastructure on your behalf. The Spinnaker User requires Power User level access to perform all their necessary tasks. AWS IAM set up is detailed by Spinnaker in their Cloud Providers Setup for AWS. They also describe the setup of other cloud providers. You need to be reasonably familiar with AWS IAM, including the PassRole permission to set up this part. As part of the setup, you enable AWS for Spinnaker and add your AWS account using the Halyard interface.

Spinnaker Security Groups
Next, I set up two Spinnaker Security Groups, corresponding to two AWS Security Groups, one for the load balancer and one for the Election service. The load balancer security group exposes port 80, and the Election service security group exposes port 8080.

Spinnaker Load Balancer
Next, I created a Spinnaker Load Balancer, corresponding to an Amazon Classic Load Balancer. The Load Balancer will load-balance the Election service EC2 instances. Below you see a Load Balancer, balancing a pair of active EC2 instances, the result of a Red/Black deployment.

Spinnaker can currently create both AWS Classic Load Balancers as well as Application Load Balancers (ALB).

Spinnaker Pipeline
This post uses a single, basic Spinnaker Pipeline. The pipeline bakes a new AMI from the Debian package generated by the Jenkins pipeline. After a manual approval stage, Spinnaker deploys a set of EC2 instances, behind the Load Balancer, which contains the latest version of the Election service. Spinnaker finishes the pipeline by sending a Slack notification.

Jenkins Integration
The pipeline is triggered by the successful completion of the Jenkins pipeline. This is set in the Configuration stage of the pipeline. The integration with Jenkins is managed through Spinnaker’s Igor service.

Bake Stage
Next, in the Bake stage, Spinnaker bakes a new AMI, containing the Debian package generated by the Jenkins pipeline. The stageʼs configuration contains the package name to reference.

The stageʼs configuration also includes a reference to which Base AMI to use, to bake the new AMIs. Here I have used the AMI ID of the base Spinnaker AMI, I created previously.

Deploy Stage
Next, the Deploy stage deploys the Election service, running on EC2 instances, provisioned from the new AMI, which was baked in the last stage. To configure the Deploy stage, you define a Spinnaker Server Group. According to Spinnaker, the Server Group identifies the deployable artifact, VM image type, the number of instances, autoscaling policies, metadata, Load Balancer, and a Security Group.

The Server Group also defines the Deployment Strategy. Below, I chose the Red/Black Deployment Strategy (also referred to as Blue/Green). This strategy will disable, not terminate the active Server Group. If the new deployment fails, we can manually or automatically perform a Rollback to the previous, currently disabled Server Group.

Letʼs Start Baking!
With set up complete, letʼs kick off a git push, trigger and complete the Jenkins pipeline, and finally trigger the Spinnaker pipeline. Below we see the pipelineʼs Bake stage has been started. Spinnakerʼs UI lets us view the Bakery Details. The Bakery, provided by Spinnakerʼs Rosco service, bakes the AMIs. Rosco uses HashiCorp Packer to bake the AMIs, using standard Packer templates.
Below we see Spinnaker (Rosco/Packer) locating the Base Spinnaker AMI we configured in the Pipelineʼs Bake stage. Next, we see Spinnaker sshʼing into a new EC2 instance with a temporary keypair and Security Group and starting the Election service Debian package installation.

Continuing, we see the latest Debian package, derived from the Jenkins pipelineʼs archive, being pulled from the S3-based APT repo. The package is verified using the GPG key and then installed. Lastly, we see a new AMI is created, containing the deployed Election service, which was initially built and packaged by Jenkins. Note the AWS Resource Tags created by Spinnaker, as shown in the Bakery output.

The base Spinnaker AMI and the AMIs baked by Spinnaker are visible in the AWS Console. Note the naming conventions used by Spinnaker for the AMIs, the Source AMI used to build the new APIs, and the addition of the Tags, which we saw being applied in the Bakery output above. The use of Tags indirectly allows full traceability from the deployed EC2 instance all the way back to the original code commit to git by the Developer.

Red/Black Deployments
With the new AMI baked successfully, and a required manual approval, using a Manual Judgement type pipeline stage, we can now begin a Red/Black deployment to AWS.

Using the Server Group configuration in the Deploy stage, Spinnaker deploys two EC2 instances, behind the ELB.

Below, we see the successful results of the Red/Black deployment. The single Spinnaker Cluster contains two deployed Server Groups. One group, the previously active Server Group (RED), comprised of two EC2 instances, is disabled. The ‘RED’ EC2 instances are unregistered with the load balancer but still running. The new Server Group (BLACK), also comprised of two EC2 instances, is now active and registered with the Load Balancer. Spinnaker will spread EC2 instances evenly across all Availability Zones in the US East (N. Virginia) Region.

From the AWS Console, we can observe four running instances, though only two are registered with the load-balancer.

Here we see each deployed Server Group has a different Auto Scaling Group and Launch Configuration. Note the continued use of naming conventions by Spinnaker.

There can be only one, Highlander!
Now, in the Deploy stage of the pipeline, we will switch the Server Groupʼs Strategy to Highlander. The Highlander strategy will, as you probably guessed by the name, destroy all other Server Groups in the Cluster. This is more typically used for lower environments, like Development or Test, where you are only interested in the next version of the application for testing. The Red/Black strategy is more applicable to Production, where you want the opportunity to quickly rollback to the previous deployment, if necessary.

Following a successful deployment, below, we now see the first two Server Groups have been terminated, and a third Server Group in the Cluster is active.

In the AWS Console, we can confirm the four previous EC2 instances have been successfully terminated as a result of the Highlander deployment strategy, and two new instances are running.

As well, the previous Auto Scaling Groups and Launch Configurations have been deleted from AWS by Spinnaker.

As expected, the Classic Load Balancer only contains the two most recent EC2 instances from the last Server Group deployed.

Confirming the Deployment
Using the DNS address of the load balancer, we can hit the Election service endpoints, on either of the EC2 instances. All API endpoints are listed in the Projectʼs README file. Below, from a web browser, we see the candidates resource returning candidate information, retrieved from the Electionʼs PostgreSQL RDS database Test instance.

Similarly, from Postman, we can hit the load balancer and get back election information from the elections resource, using an HTTP GET.

I intentionally left out a discussion of the service’s RDS database and how configuration management was handled with Spring Profiles and Spring Cloud Config. Both topics were out of scope for this post.
Conclusion
Although this was a brief, whirlwind overview of deployment tools, it shows the power of delivery tools like Spinnaker, when seamlessly combined with other tools, like Jenkins and the Nebula plugins. Together, these tools are capable of efficiently, repeatably, and securely deploying large numbers of containerized and non-containerized applications to a variety of private, public, and hybrid cloud infrastructure.
All opinions expressed in this post are my own and not necessarily the views of my current or past employers or their clients.
Deploying Spring Boot Apps to AWS with Netflix Nebula and Spinnaker: Part 1 of 2
Posted by Gary A. Stafford in AWS, Build Automation, Continuous Delivery, Enterprise Software Development, Java Development, Software Development on May 10, 2018
Listening to DevOps industry pundits, you might be convinced everyone is running containers in Production (or by now, serverless). Although containerization is growing at a phenomenal rate, several recent surveys¹ indicate less than 50% of enterprises are deploying containers in Production. Filter those results further with the fact, of those enterprises, only a small percentage of their total application portfolios are containerized, let alone in Production.
As a DevOps Consultant, I regularly work with corporations whose global portfolios are in the thousands of applications. Indeed, some percentage of their applications are containerized, with less running in Production. However, a majority of those applications, even those built on modern, light-weight, distributed architectures, are still being deployed to bare-metal and virtualized public cloud and private data center infrastructure, for a variety of reasons.
Enterprise Deployment
Due to the scale and complexity of application portfolios, many organizations have invested in enterprise deployment tools, either commercially available or developed in-house. The enterprise deployment tool’s primary objective is to standardize the process of securely, reliably, and repeatably packaging, publishing, and deploying both containerized and non-containerized applications to large fleets of virtual machines and bare-metal servers, across multiple, geographically dispersed data centers and cloud providers. Enterprise deployment tools are particularly common in tightly regulated and compliance-driven organizations, as well as organizations that have undertaken large amounts of M&A, resulting in vastly different application technology stacks.

Better-known examples of commercially available enterprise deployment tools include IBM UrbanCode Deploy (aka uDeploy), XebiaLabs XL Deploy, CA Automic Release Automation, Octopus Deploy, and Electric Cloud ElectricFlow. While commercial tools continue to gain market share³, many organizations are tightly coupled to their in-house solutions through years of use and fear of widespread process disruption, given current economic, security, compliance, and skills-gap sensitivities.
Deployment Tool Anatomy
Most Enterprise deployment tools are compatible with standard binary package types, including Debian (.deb) and Red Hat (RPM) Package Manager (.rpm) packages for Linux, NuGet (.nupkg) packages for Windows, and Node Package Manager (.npm) and Bower for JavaScript. There are equivalent package types for other popular languages and formats, such as Go, Python, Ruby, SQL, Android, Objective-C, Swift, and Docker. Packages usually contain application metadata, a signature to ensure the integrity and/or authenticity², and a compressed payload.
Enterprise deployment tools are normally integrated with open-source packaging and publishing tools, such as Apache Maven, Apache Ivy/Ant, Gradle, NPM, NuGet, Bundler, PIP, and Docker.
Binary packages (and images), built with enterprise deployment tools, are typically stored in private, open-source or commercial binary (artifact) repositories, such as Spacewalk, JFrog Artifactory, and Sonatype Nexus Repository. The latter two, Artifactory and Nexus, support a multitude of modern package types and repository structures, including Maven, NuGet, PyPI, NPM, Bower, Ruby Gems, CocoaPods, Puppet, Chef, and Docker.
Mature binary repositories provide many features in addition to package management, including role-based access control, vulnerability scanning, rich APIs, DevOps integration, and fault-tolerant, high-availability architectures.
Lastly, enterprise deployment tools generally rely on standard package management systems to retrieve and install cryptographically verifiable packages and images. These include YUM (Yellowdog Updater, Modified), APT (aptitude), APK (Alpine Linux), NuGet, Chocolatey, NPM, PIP, Bundler, and Docker. Packages are deployed directly to running infrastructure, or indirectly to intermediate deployable components as Amazon Machine Images (AMI), Google Compute Engine machine images, VMware machines, Docker Images, or CoreOS rkt.
Open-Source Alternative
One such enterprise with an extensive portfolio of both containerized and non-containerized applications is Netflix. To standardize their deployments to multiple types of cloud infrastructure, Netflix has developed several well-known open-source software (OSS) tools, including the Nebula Gradle plugins and Spinnaker. I discussed Spinnaker in my previous post, Managing Applications Across Multiple Kubernetes Environments with Istio, as an alternative to Jenkins for deploying container workloads to Kubernetes on Google (GKE).
As a leader in OSS, Netflix has documented their deployment process in several articles and presentations, including a post from 2016, ‘How We Build Code at Netflix.’ According to the article, the high-level process for deployment to Amazon EC2 instances involves the following steps:
- Code is built and tested locally using Nebula
- Changes are committed to a central git repository
- Jenkins job executes Nebula, which builds, tests, and packages the application for deployment
- Builds are “baked” into Amazon Machine Images (using Spinnaker)
- Spinnaker pipelines are used to deploy and promote the code change
The Nebula plugins and Spinnaker leverage many underlying, open-source technologies, including Pivotal Spring, Java, Groovy, Gradle, Maven, Apache Commons, Redline RPM, HashiCorp Packer, Redis, HashiCorp Consul, Cassandra, and Apache Thrift.
Both the Nebula plugins and Spinnaker have been battle tested in Production by Netflix, as well as by many other industry leaders after Netflix open-sourced the tools in 2014 (Nebula) and 2015 (Spinnaker). Currently, there are approximately 20 Nebula Gradle plugins available on GitHub. Notable core-contributors in the development of Spinnaker include Google, Microsoft, Pivotal, Target, Veritas, and Oracle, to name a few. A sign of its success, Spinnaker currently has over 4,600 Stars on GitHub!
Part Two: Demonstration
In Part Two, we will deploy a production-ready Spring Boot application, the Election microservice, to multiple Amazon EC2 instances, behind an Elastic Load Balancer (ELB). We will use a fully automated DevOps workflow. The build, test, package, bake, deploy process will be handled by the Netflix Nebula Gradle Linux Packaging Plugin, Jenkins, and Spinnaker. The high-level process will involve the following steps:
- Configure Gradle to build a production-ready fully executable application for Unix systems (executable JAR)
- Using deb-s3 and GPG Suite, create a secure, signed APT (Debian) repository on Amazon S3
- Using Jenkins and the Netflix Nebula plugin, build a Debian package, containing the executable JAR and configuration files
- Using Jenkins and deb-s3, publish the package to the S3-based APT repository
- Using Spinnaker (HashiCorp Packer under the covers), bake an Ubuntu Amazon Machine Image (AMI), replete with the executable JAR installed from the Debian package
- Deploy an auto-scaling set of Amazon EC2 instances from the baked AMI, behind an ELB, running the Spring Boot application using both the Red/Black and Highlander deployment strategies
- Be able to repeat the entire automated build, test, package, bake, deploy process, triggered by a new code push to GitHub
The overall build, test, package, bake, deploy process will look as follows.
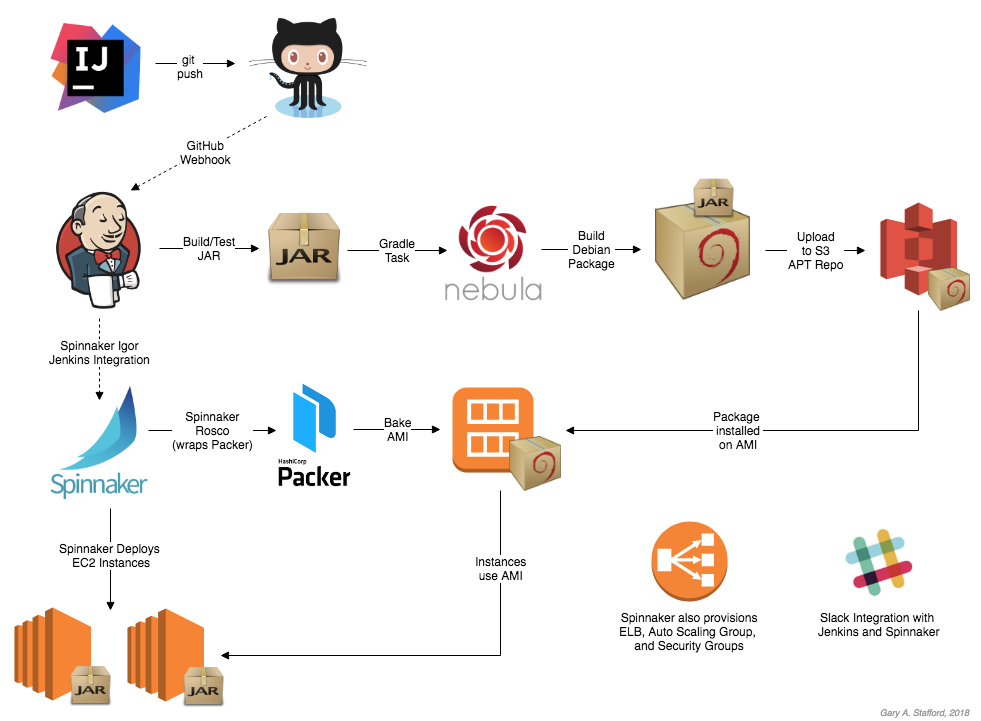
References
- How We Build Code at Netflix
- Debian Packages (Armory)
- An Introduction to Spinnaker: Hello Deployment
- Spinnaker: CD from first principles to production (Google Cloud Next ’17) (YouTube)
- Nebula Plugin Overview
- Installing Spring Boot Applications
- Debian Binary Package Building HOWTO
All opinions expressed in this post are my own and not necessarily the views of my current or past employers or their clients.
¹ Recent Surveys: Forrester, Portworx, Cloud Foundry Survey
² Courtesy Wikipedia – rpm
³ XebiaLabs Kicks Off 2017 with Triple-Digit Growth in Enterprise DevOps
Updating and Maintaining Gradle Project Dependencies
Posted by Gary A. Stafford in Build Automation, Enterprise Software Development, Java Development, Software Development, Technology Consulting on May 5, 2018
As a DevOps Consultant, I often encounter codebases that have not been properly kept up-to-date. Likewise, I’ve authored many open-source projects on GitHub, which I use for training, presentations, and articles. Those projects often sit dormant for months at a time, #myabandonware.
Poorly maintained and dormant projects often become brittle or break, as their dependencies and indirect dependencies continue to be updated. However, blindly updating project dependencies is often the quickest way to break, or further break an application. Ask me, I’ve given in to temptation and broken my fair share of applications as a result. Nonetheless, it is helpful to be able to quickly analyze a project’s dependencies and discover available updates. Defects, performance issues, and most importantly, security vulnerabilities, are often fixed with dependency updates.
For Node.js projects, I prefer David to discover dependency updates. I have other favorites for Ruby, .NET, and Python, including OWASP Dependency-Check, great for vulnerabilities. In a similar vein, for Gradle-based Java Spring projects, I recently discovered Ben Manes’ Gradle Versions Plugin, gradle-versions-plugin. The plugin is described as a ‘Gradle plugin to discover dependency updates’. The plugin’s GitHub project has over 1,350 stars! According to the plugin project’s README file, this plugin is similar to the Versions Maven Plugin. The project further indicates there are similar Gradle plugins available, including gradle-use-latest-versions, gradle-libraries-plugin, and gradle-update-notifier.
To try the Gradle Versions Plugin, I chose a recent Gradle-based Java Spring Boot API project. I added the plugin to the gradle.build file with a single line of code.
plugins {
id 'com.github.ben-manes.versions' version '0.17.0'
}
By executing the single Gradle task, dependencyUpdates, the plugin generates a report detailing the status of all project’s dependencies, including plugins. The plugin includes a revision task property, which controls the resolution strategy of determining what constitutes the latest version of a dependency. The property supports three strategies: release, milestone (default), and integration (i.e. SNAPSHOT), which are detailed in the plugin project’s README file.
As expected, the plugin will properly resolve any variables. Using a variable is an efficient practice for setting the Spring Boot versions for multiple dependencies (i.e. springBootVersion).
ext {
springBootVersion = '2.0.1.RELEASE'
}
dependencies {
compile('com.h2database:h2:1.4.197')
compile("io.springfox:springfox-swagger-ui:2.8.0")
compile("io.springfox:springfox-swagger2:2.8.0")
compile("org.liquibase:liquibase-core:3.5.5")
compile("org.sonarsource.scanner.gradle:sonarqube-gradle-plugin:2.6.2")
compile("org.springframework.boot:spring-boot-starter-actuator:${springBootVersion}")
compile("org.springframework.boot:spring-boot-starter-data-jpa:${springBootVersion}")
compile("org.springframework.boot:spring-boot-starter-data-rest:${springBootVersion}")
compile("org.springframework.boot:spring-boot-starter-hateoas:${springBootVersion}")
compile("org.springframework.boot:spring-boot-starter-web:${springBootVersion}")
compileOnly('org.projectlombok:lombok:1.16.20')
runtime("org.postgresql:postgresql:42.2.2")
testCompile("org.springframework.boot:spring-boot-starter-test:${springBootVersion}")
}
My first run, using the default revision level, resulted in the following output. The report indicated three of my project’s dependencies were slightly out of date:
> Configure project : Inferred project: spring-postgresql-demo, version: 4.3.0-dev.2.uncommitted+929c56e > Task :dependencyUpdates Failed to resolve ::apiElements Failed to resolve ::implementation Failed to resolve ::runtimeElements Failed to resolve ::runtimeOnly Failed to resolve ::testImplementation Failed to resolve ::testRuntimeOnly ------------------------------------------------------------ : Project Dependency Updates (report to plain text file) ------------------------------------------------------------ The following dependencies are using the latest milestone version: - com.github.ben-manes.versions:com.github.ben-manes.versions.gradle.plugin:0.17.0 - com.netflix.nebula:gradle-ospackage-plugin:4.9.0-rc.1 - com.h2database:h2:1.4.197 - io.spring.dependency-management:io.spring.dependency-management.gradle.plugin:1.0.5.RELEASE - org.projectlombok:lombok:1.16.20 - com.netflix.nebula:nebula-release-plugin:6.3.3 - org.sonarqube:org.sonarqube.gradle.plugin:2.6.2 - org.springframework.boot:org.springframework.boot.gradle.plugin:2.0.1.RELEASE - org.postgresql:postgresql:42.2.2 - org.sonarsource.scanner.gradle:sonarqube-gradle-plugin:2.6.2 - org.springframework.boot:spring-boot-starter-actuator:2.0.1.RELEASE - org.springframework.boot:spring-boot-starter-data-jpa:2.0.1.RELEASE - org.springframework.boot:spring-boot-starter-data-rest:2.0.1.RELEASE - org.springframework.boot:spring-boot-starter-hateoas:2.0.1.RELEASE - org.springframework.boot:spring-boot-starter-test:2.0.1.RELEASE - org.springframework.boot:spring-boot-starter-web:2.0.1.RELEASE The following dependencies have later milestone versions: - org.liquibase:liquibase-core [3.5.5 -> 3.6.1] - io.springfox:springfox-swagger-ui [2.8.0 -> 2.9.0] - io.springfox:springfox-swagger2 [2.8.0 -> 2.9.0] Generated report file build/dependencyUpdates/report.txt
After reading the release notes for the three available updates, and confident I had sufficient unit, smoke, and integration tests to validate any project changes, I manually updated the dependencies. Re-running the Gradle task generated the following abridged output.
------------------------------------------------------------ : Project Dependency Updates (report to plain text file) ------------------------------------------------------------ The following dependencies are using the latest milestone version: - com.github.ben-manes.versions:com.github.ben-manes.versions.gradle.plugin:0.17.0 - com.netflix.nebula:gradle-ospackage-plugin:4.9.0-rc.1 - com.h2database:h2:1.4.197 - io.spring.dependency-management:io.spring.dependency-management.gradle.plugin:1.0.5.RELEASE - org.liquibase:liquibase-core:3.6.1 - org.projectlombok:lombok:1.16.20 - com.netflix.nebula:nebula-release-plugin:6.3.3 - org.sonarqube:org.sonarqube.gradle.plugin:2.6.2 - org.springframework.boot:org.springframework.boot.gradle.plugin:2.0.1.RELEASE - org.postgresql:postgresql:42.2.2 - org.sonarsource.scanner.gradle:sonarqube-gradle-plugin:2.6.2 - org.springframework.boot:spring-boot-starter-actuator:2.0.1.RELEASE - org.springframework.boot:spring-boot-starter-data-jpa:2.0.1.RELEASE - org.springframework.boot:spring-boot-starter-data-rest:2.0.1.RELEASE - org.springframework.boot:spring-boot-starter-hateoas:2.0.1.RELEASE - org.springframework.boot:spring-boot-starter-test:2.0.1.RELEASE - org.springframework.boot:spring-boot-starter-web:2.0.1.RELEASE - io.springfox:springfox-swagger-ui:2.9.0 - io.springfox:springfox-swagger2:2.9.0 Generated report file build/dependencyUpdates/report.txt BUILD SUCCESSFUL in 3s 1 actionable task: 1 executed
After running a series of automated unit, smoke, and integration tests, to confirm no conflicts with the updates, I committed my changes to GitHub. The Gradle Versions Plugin is a simple and effective solution to Gradle dependency management.
All opinions expressed in this post are my own, and not necessarily the views of my current or past employers, or their clients.
Gradle logo courtesy Gradle.org, © Gradle Inc.
Developing Cloud-Native Data-Centric Spring Boot Applications for Pivotal Cloud Foundry
Posted by Gary A. Stafford in AWS, Cloud, Continuous Delivery, DevOps, Java Development, PCF, Software Development on March 23, 2018
In this post, we will explore the development of a cloud-native, data-centric Spring Boot 2.0 application, and its deployment to Pivotal Software’s hosted Pivotal Cloud Foundry service, Pivotal Web Services. We will add a few additional features, such as Spring Data, Lombok, and Swagger, to enhance our application.
According to Pivotal, Spring Boot makes it easy to create stand-alone, production-grade Spring-based Applications. Spring Boot takes an opinionated view of the Spring platform and third-party libraries. Spring Boot 2.0 just went GA on March 1, 2018. This is the first major revision of Spring Boot since 1.0 was released almost 4 years ago. It is also the first GA version of Spring Boot that provides support for Spring Framework 5.0.
Pivotal Web Services’ tagline is ‘The Agile Platform for the Agile Team Powered by Cloud Foundry’. According to Pivotal, Pivotal Web Services (PWS) is a hosted environment of Pivotal Cloud Foundry (PCF). PWS is hosted on AWS in the US-East region. PWS utilizes two availability zones for redundancy. PWS provides developers a Spring-centric PaaS alternative to AWS Elastic Beanstalk, Elastic Container Service (Amazon ECS), and OpsWorks. With PWS, you get the reliability and security of AWS, combined with the rich-functionality and ease-of-use of PCF.
To demonstrate the feature-rich capabilities of the Spring ecosystem, the Spring Boot application shown in this post incorporates the following complimentary technologies:
- Spring Boot Actuator: Sub-project of Spring Boot, adds several production grade services to Spring Boot applications with little developer effort
- Spring Data JPA: Sub-project of Spring Data, easily implement JPA based repositories and data access layers
- Spring Data REST: Sub-project of Spring Data, easily build hypermedia-driven REST web services on top of Spring Data repositories
- Spring HATEOAS: Create REST representations that follow the HATEOAS principle from Spring-based applications
- Springfox Swagger 2: We are using the Springfox implementation of the Swagger 2 specification, an automated JSON API documentation for API’s built with Spring
- Lombok: The
@Dataannotation generates boilerplate code that is typically associated with simple POJOs (Plain Old Java Objects) and beans:@ToString,@EqualsAndHashCode,@Getter,@Setter, and@RequiredArgsConstructor
Source Code
All source code for this post can be found on GitHub. To get started quickly, use one of the two following commands (gist).
| # clone the official v2.1.1 release for this post | |
| git clone --depth 1 --branch v2.1.1 \ | |
| https://github.com/garystafford/spring-postgresql-demo.git \ | |
| && cd spring-postgresql-demo \ | |
| && git checkout -b v2.1.1 | |
| # clone the latest version of code (newer than article) | |
| git clone --depth 1 --branch master \ | |
| https://github.com/garystafford/spring-postgresql-demo.git \ | |
| && cd spring-postgresql-demo |
For this post, I have used JetBrains IntelliJ IDEA and Git Bash on Windows for development. However, all code should be compatible with most popular IDEs and development platforms. The project assumes you have Docker and the Cloud Foundry Command Line Interface (cf CLI) installed locally.
Code samples in this post are displayed as Gists, which may not display correctly on some mobile and social media browsers. Links to gists are also provided.
Demo Application
The Spring Boot application demonstrated in this post is a simple election-themed RESTful API. The app allows API consumers to create, read, update, and delete, candidates, elections, and votes, via its exposed RESTful HTTP-based resources.
The Spring Boot application consists of (7) JPA Entities that mirror the tables and views in the database, (7) corresponding Spring Data Repositories, (2) Spring REST Controller, (4) Liquibase change sets, and associated Spring, Liquibase, Swagger, and PCF configuration files. I have intentionally chosen to avoid the complexities of using Data Transfer Objects (DTOs) for brevity, albeit a security concern, and directly expose the entities as resources.

Controller Resources
This application is a simple CRUD application. The application contains a few simple HTTP GET resources in each of the two controller classes, as an introduction to Spring REST controllers. For example, the CandidateController contains the /candidates/summary and /candidates/summary/{election} resources (shown below in Postman). Typically, you would expose your data to the end-user as controller resources, as opposed to exposing the entities directly. The ease of defining controller resources is one of the many powers of Spring Boot.

Paging and Sorting
As an introduction to Spring Data’s paging and sorting features, both the VoteRepository and VotesElectionsViewRepository Repository Interfaces extend Spring Data’s PagingAndSortingRepository<T,ID> interface, instead of the default CrudRepository<T,ID> interface. With paging and sorting enabled, you may both sort and limit the amount of data returned in the response payload. For example, to reduce the size of your response payload, you might choose to page through the votes in blocks of 25 votes at a time. In that case, as shown below in Postman, if you needed to return just votes 26-50, you would append the /votes resource with ?page=1&size=25. Since paging starts on page 0 (zero), votes 26-50 will on page 1.

Swagger
This project also includes the Springfox implementation of the Swagger 2 specification. Along with the Swagger 2 dependency, the project takes a dependency on io.springfox:springfox-swagger-ui. The Springfox Swagger UI dependency allows us to view and interactively test our controller resources through Swagger’s browser-based UI, as shown below.

All Swagger configuration can be found in the project’s SwaggerConfig Spring Configuration class.
Gradle
This post’s Spring Boot application is built with Gradle, although it could easily be converted to Maven if desired. According to Gradle, Gradle is the modern tool used to build, automate and deliver everything from mobile apps to microservices.
Data
In real life, most applications interact with one or more data sources. The Spring Boot application demonstrated in this post interacts with data from a PostgreSQL database. PostgreSQL, or simply Postgres, is the powerful, open-source object-relational database system, which has supported production-grade applications for 15 years. The application’s single elections database consists of (6) tables, (3) views, and (2) function, which are both used to generate random votes for this demonstration.

Spring Data makes interacting with PostgreSQL easy. In addition to the features of Spring Data, we will use Liquibase. Liquibase is known as the source control for your database. With Liquibase, your database development lifecycle can mirror your Spring development lifecycle. Both DDL (Data Definition Language) and DML (Data Manipulation Language) changes are versioned controlled, alongside the Spring Boot application source code.
Locally, we will take advantage of Docker to host our development PostgreSQL database, using the official PostgreSQL Docker image. With Docker, there is no messy database installation and configuration of your local development environment. Recreating and deleting your PostgreSQL database is simple.
To support the data-tier in our hosted PWS environment, we will implement ElephantSQL, an offering from the Pivotal Services Marketplace. ElephantSQL is a hosted version of PostgreSQL, running on AWS. ElephantSQL is referred to as PostgreSQL as a Service, or more generally, a Database as a Service or DBaaS. As a Pivotal Marketplace service, we will get easy integration with our PWS-hosted Spring Boot application, with near-zero configuration.
Docker
First, set up your local PostgreSQL database using Docker and the official PostgreSQL Docker image. Since this is only a local database instance, we will not worry about securing our database credentials (gist).
| # create container | |
| docker run --name postgres \ | |
| -e POSTGRES_USERNAME=postgres \ | |
| -e POSTGRES_PASSWORD=postgres1234 \ | |
| -e POSTGRES_DB=elections \ | |
| -p 5432:5432 \ | |
| -d postgres | |
| # view container | |
| docker container ls | |
| # trail container logs | |
| docker logs postgres --follow |
Your running PostgreSQL container should resemble the output shown below.

Data Source
Most IDEs allow you to create and save data sources. Although this is not a requirement, it makes it easier to view the database’s resources and table data. Below, I have created a data source in IntelliJ from the running PostgreSQL container instance. The port, username, password, and database name were all taken from the above Docker command.

Liquibase
There are multiple strategies when it comes to managing changes to your database. With Liquibase, each set of changes are handled as change sets. Liquibase describes a change set as an atomic change that you want to apply to your database. Liquibase offers multiple formats for change set files, including XML, JSON, YAML, and SQL. For this post, I have chosen SQL, specifically PostgreSQL SQL dialect, which can be designated in the IntelliJ IDE. Below is an example of the first changeset, which creates four tables and two indexes.

As shown below, change sets are stored in the db/changelog/changes sub-directory, as configured in the master change log file (db.changelog-master.yaml). Change set files follow an incremental naming convention.

The empty PostgreSQL database, before any Liquibase changes, should resemble the screengrab shown below.

To automatically run Liquibase database migrations on startup, the org.liquibase:liquibase-core dependency must be added to the project’s build.gradle file. To apply the change sets to your local, empty PostgreSQL database, simply start the service locally with the gradle bootRun command. As the app starts after being compiled, any new Liquibase change sets will be applied.

You might ask how does Liquibase know the change sets are new. During the initial startup of the Spring Boot application, in addition to any initial change sets, Liquibase creates two database tables to track changes, the databasechangelog and databasechangeloglock tables. Shown below are the two tables, along with the results of the four change sets included in the project, and applied by Liquibase to the local PostgreSQL elections database.

Below we see the contents of the databasechangelog table, indicating that all four change sets were successfully applied to the database. Liquibase checks this table before applying change sets.

ElephantSQL
Before we can deploy our Spring Boot application to PWS, we need an accessible PostgreSQL instance in the Cloud; I have chosen ElephantSQL. Available through the Pivotal Services Marketplace, ElephantSQL currently offers one free and three paid service plans for their PostgreSQL as a Service. I purchased the Panda service plan as opposed to the free Turtle service plan. I found the free service plan was too limited in the maximum number of database connections for multiple service instances.
Previewing and purchasing an ElephantSQL service plan from the Pivotal Services Marketplace, assuming you have an existing PWS account, literally takes a single command (gist).
| # view elephantsql service plans | |
| cf marketplace -s elephantsql | |
| # purchase elephantsql service plan | |
| cf create-service elephantsql panda elections | |
| # display details of running service | |
| cf service elections |
The output of the command should resemble the screengrab below. Note the total concurrent connections and total storage for each plan.

To get details about the running ElephantSQL service, use the cf service elections command.

From the ElephantSQL Console, we can obtain the connection information required to access our PostgreSQL elections database. You will need the default database name, username, password, and URL.

Service Binding
Once you have created the PostgreSQL database service, you need to bind the database service to the application. We will bind our application and the database, using the PCF deployment manifest file (manifest.yml), found in the project’s root directory. Binding is done using the services section (shown below).
The key/value pairs in the env section of the deployment manifest will become environment variables, local to the deployed Spring Boot service. These key/value pairs in the manifest will also override any configuration set in Spring’s external application properties file (application.yml). This file is located in the resources sub-directory. Note the SPRING_PROFILES_ACTIVE: test environment variable in the manifest.yml file. This variable designates which Spring Profile will be active from the multiple profiles defined in the application.yml file.

Deployment to PWS
Next, we run gradle build followed by cf push to deploy one instance of the Spring Boot service to PWS and associate it with our ElephantSQL database instance. Below is the expected output from the cf push command.

Note the route highlighted below. This is the URL where your Spring Boot service will be available.

To confirm your ElephantSQL database was populated by Liquibase when PWS started the deployed Spring application instance, we can check the ElephantSQL Console’s Stats tab. Note the database tables and rows in each table, signifying Liquibase ran successfully. Alternately, you could create another data source in your IDE, connected to ElephantSQL; this can be helpful for troubleshooting.

To access the running service and check that data is being returned, point your browser (or Postman) to the URL returned from the cf push command output (see second screengrab above) and hit the /candidates resource. Obviously, your URL, referred to as a route by PWS, will be different and unique. In the response payload, you should observe a JSON array of eight candidate objects. Each candidate was inserted into the Candidate table of the database, by Liquibase, when Liquibase executed the second of the four change sets on start-up.

With Spring Boot Actuator and Spring Data REST, our simple Spring Boot application has dozens of resources exposed automatically, without extensive coding of resource controllers. Actuator exposes resources to help manage and troubleshoot the application, such as info, health, mappings (shown below), metrics, env, and configprops, among others. All Actuator resources are exposed explicitly, thus they can be disabled for Production deployments. With Spring Boot 2.0, all Actuator resources are now preceded with /actuator/ .

According to Pivotal, Spring Data REST builds on top of Spring Data repositories, analyzes an application’s domain model and exposes hypermedia-driven HTTP resources for aggregates contained in the model, such as our /candidates resource. A partial list of the application’s exposed resources are listed in the GitHub project’s README file.
In Spring’s approach to building RESTful web services, HTTP requests are handled by a controller. Spring Data REST automatically exposes CRUD resources for our entities. With Spring Data JPA, POJOs like our Candidate class are annotated with @Entity, indicating that it is a JPA entity. Lacking a @Table annotation, it is assumed that this entity will be mapped to a table named Candidate.
With Spring’s Data REST’s RESTful HTTP-based API, traditional database Create, Read, Update, and Delete commands for each PostgreSQL database table are automatically mapped to equivalent HTTP methods, including POST, GET, PUT, PATCH, and DELETE.
Below is an example, using Postman, to create a new Candidate using an HTTP POST method.

Below is an example, using Postman, to update a new Candidate using an HTTP PUT method.

With Spring Data REST, we can even retrieve data from read-only database Views, as shown below. This particular JSON response payload was returned from the candidates_by_elections database View, using the /election-candidates resource.

Scaling Up
Once your application is deployed and you have tested its functionality, you can easily scale out or scale in the number instances, memory, and disk, with the cf scale command (gist).
| # scale up to 2 instances | |
| cf scale cf-spring -i 2 | |
| # review status of both instances | |
| cf app pcf-postgresql-demo |
Below is sample output from scaling up the Spring Boot application to two instances.

Optionally, you can activate auto-scaling, which will allow the application to scale based on load.

Following the PCF architectural model, auto-scaling is actually another service from the Pivotal Services Marketplace, PCF App Autoscaler, as seen below, running alongside our ElephantSQL service.

With PCF App Autoscaler, you set auto-scaling minimum and maximum instance limits and define scaling rules. Below, I have configured auto-scaling to scale out the number of application instances when the average CPU Utilization of all instances hits 80%. Conversely, the application will scale in when the average CPU Utilization recedes below 40%. In addition to CPU Utilization, PCF App Autoscaler also allows you to set scaling rules based on HTTP Throughput, HTTP Latency, RabbitMQ Depth (queue depth), and Memory Utilization.
Furthermore, I set the auto-scaling minimum number of instances to two and the maximum number of instances to four. No matter how much load is placed on the application, PWS will not scale above four instances. Conversely, PWS will maintain a minimum of two running instances at all times.

Conclusion
This brief post demonstrates both the power and simplicity of Spring Boot to quickly develop highly-functional, data-centric RESTful API applications with minimal coding. Further, when coupled with Pivotal Cloud Foundry, Spring developers have a highly scalable, resilient cloud-native application hosting platform.
Spring Music Revisited: Java-Spring-MongoDB Web App with Docker 1.12
Posted by Gary A. Stafford in Build Automation, Continuous Delivery, DevOps, Enterprise Software Development, Java Development, Software Development on August 7, 2016
Build, test, deploy, and monitor a multi-container, MongoDB-backed, Java Spring web application, using the new Docker 1.12.
Introduction
This post and the post’s example project represent an update to a previous post, Build and Deploy a Java-Spring-MongoDB Application using Docker. This new post incorporates many improvements made in Docker 1.12, including the use of the new Docker Compose v2 YAML format. The post’s project was also updated to use Filebeat with ELK, as opposed to Logspout, which was used previously.
In this post, we will demonstrate how to build, test, deploy, and manage a Java Spring web application, hosted on Apache Tomcat, load-balanced by NGINX, monitored by ELK with Filebeat, and all containerized with Docker.
We will use a sample Java Spring application, Spring Music, available on GitHub from Cloud Foundry. The Spring Music sample record album collection application was originally designed to demonstrate the use of database services on Cloud Foundry, using the Spring Framework. Instead of Cloud Foundry, we will host the Spring Music application locally, using Docker on VirtualBox, and optionally on AWS.
All files necessary to build this project are stored on the docker_v2 branch of the garystafford/spring-music-docker repository on GitHub. The Spring Music source code is stored on the springmusic_v2 branch of the garystafford/spring-music repository, also on GitHub.

Application Architecture
The Java Spring Music application stack contains the following technologies: Java, Spring Framework, AngularJS, Bootstrap, jQuery, NGINX, Apache Tomcat, MongoDB, the ELK Stack, and Filebeat. Testing frameworks include the Spring MVC Test Framework, Mockito, Hamcrest, and JUnit.
A few changes were made to the original Spring Music application to make it work for this demonstration, including:
- Move from Java 1.7 to 1.8 (including newer Tomcat version)
- Add unit tests for Continuous Integration demonstration purposes
- Modify MongoDB configuration class to work with non-local, containerized MongoDB instances
- Add Gradle
warNoStatictask to build WAR without static assets - Add Gradle
zipStatictask to ZIP up the application’s static assets for deployment to NGINX - Add Gradle
zipGetVersiontask with a versioning scheme for build artifacts - Add
context.xmlfile andMANIFEST.MFfile to the WAR file - Add Log4j
RollingFileAppenderappender to send log entries to Filebeat - Update versions of several dependencies, including Gradle, Spring, and Tomcat
We will use the following technologies to build, publish, deploy, and host the Java Spring Music application: Gradle, git, GitHub, Travis CI, Oracle VirtualBox, Docker, Docker Compose, Docker Machine, Docker Hub, and optionally, Amazon Web Services (AWS).
NGINX
To increase performance, the Spring Music web application’s static content will be hosted by NGINX. The application’s WAR file will be hosted by Apache Tomcat 8.5.4. Requests for non-static content will be proxied through NGINX on the front-end, to a set of three load-balanced Tomcat instances on the back-end. To further increase application performance, NGINX will also be configured for browser caching of the static content. In many enterprise environments, the use of a Java EE application server, like Tomcat, is still not uncommon.
Reverse proxying and caching are configured thought NGINX’s default.conf file, in the server configuration section:
| server { | |
| listen 80; | |
| server_name proxy; | |
| location ~* \/assets\/(css|images|js|template)\/* { | |
| root /usr/share/nginx/; | |
| expires max; | |
| add_header Pragma public; | |
| add_header Cache-Control "public, must-revalidate, proxy-revalidate"; | |
| add_header Vary Accept-Encoding; | |
| access_log off; | |
| } |
The three Tomcat instances will be manually configured for load-balancing using NGINX’s default round-robin load-balancing algorithm. This is configured through the default.conf file, in the upstream configuration section:
| upstream backend { | |
| server music_app_1:8080; | |
| server music_app_2:8080; | |
| server music_app_3:8080; | |
| } |
Client requests are received through port 80 on the NGINX server. NGINX redirects requests, which are not for non-static assets, to one of the three Tomcat instances on port 8080.
MongoDB
The Spring Music application was designed to work with a number of data stores, including MySQL, Postgres, Oracle, MongoDB, Redis, and H2, an in-memory Java SQL database. Given the choice of both SQL and NoSQL databases, we will select MongoDB.
The Spring Music application, hosted by Tomcat, will store and modify record album data in a single instance of MongoDB. MongoDB will be populated with a collection of album data from a JSON file, when the Spring Music application first creates the MongoDB database instance.
ELK
Lastly, the ELK Stack with Filebeat, will aggregate NGINX, Tomcat, and Java Log4j log entries, providing debugging and analytics to our demonstration. A similar method for aggregating logs, using Logspout instead of Filebeat, can be found in this previous post.
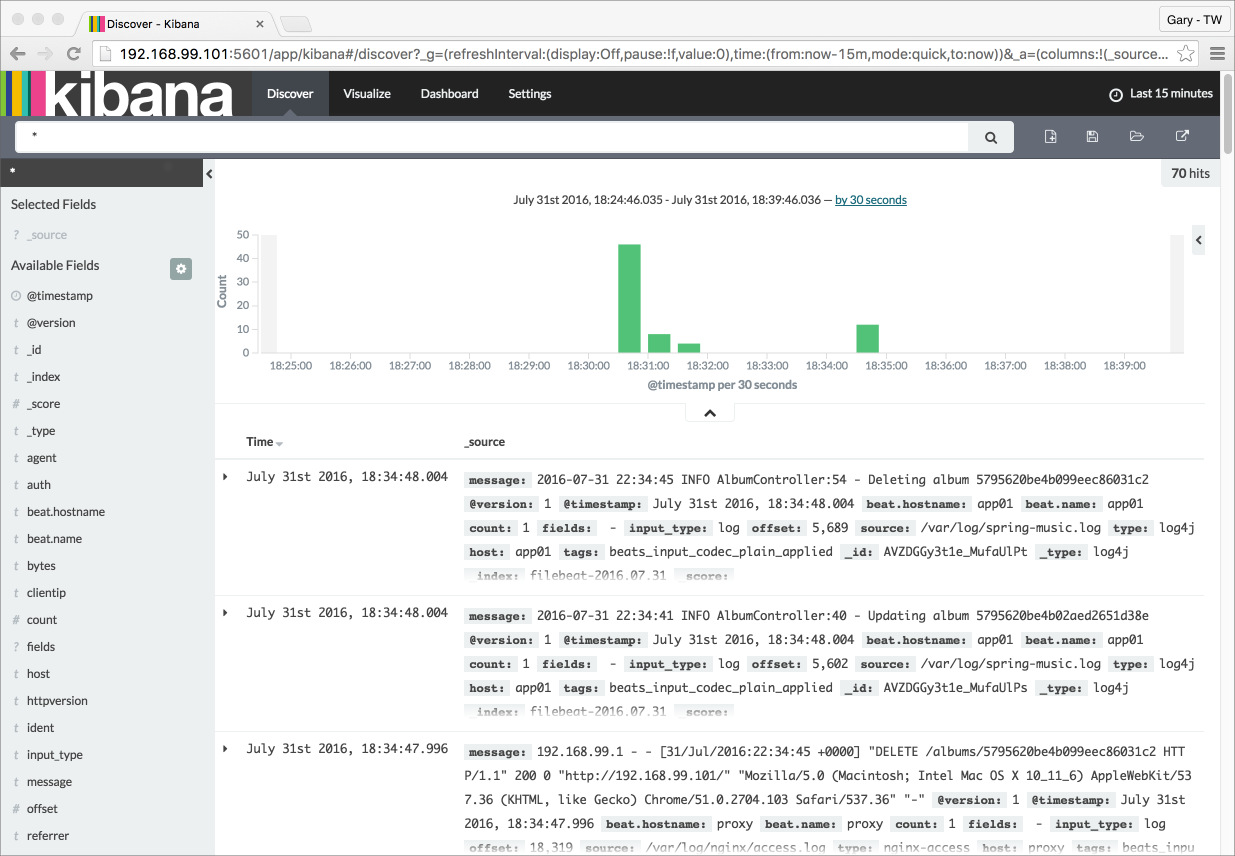
Continuous Integration
In this post’s example, two build artifacts, a WAR file for the application and ZIP file for the static web content, are built automatically by Travis CI, whenever source code changes are pushed to the springmusic_v2 branch of the garystafford/spring-music repository on GitHub.

Following a successful build and a small number of unit tests, Travis CI pushes the build artifacts to the build-artifacts branch on the same GitHub project. The build-artifacts branch acts as a pseudo binary repository for the project, much like JFrog’s Artifactory. These artifacts are used later by Docker to build the project’s immutable Docker images and containers.
Build Notifications
Travis CI pushes build notifications to a Slack channel, which eliminates the need to actively monitor Travis CI.
Automation Scripting
The .travis.yaml file, custom gradle.build Gradle tasks, and the deploy_travisci.sh script handles the Travis CI automation described, above.
Travis CI .travis.yaml file:
| language: java | |
| jdk: oraclejdk8 | |
| before_install: | |
| - chmod +x gradlew | |
| before_deploy: | |
| - chmod ugo+x deploy_travisci.sh | |
| script: | |
| - "./gradlew clean build" | |
| - "./gradlew warNoStatic warCopy zipGetVersion zipStatic" | |
| - sh ./deploy_travisci.sh | |
| env: | |
| global: | |
| - GH_REF: github.com/garystafford/spring-music.git | |
| - secure: <GH_TOKEN_secure_hash_here> | |
| - secure: <COMMIT_AUTHOR_EMAIL_secure_hash_here> | |
| notifications: | |
| slack: | |
| - secure: <SLACK_secure_hash_here> |
Custom gradle.build tasks:
| // new Gradle build tasks | |
| task warNoStatic(type: War) { | |
| // omit the version from the war file name | |
| version = '' | |
| exclude '**/assets/**' | |
| manifest { | |
| attributes | |
| 'Manifest-Version': '1.0', | |
| 'Created-By': currentJvm, | |
| 'Gradle-Version': GradleVersion.current().getVersion(), | |
| 'Implementation-Title': archivesBaseName + '.war', | |
| 'Implementation-Version': artifact_version, | |
| 'Implementation-Vendor': 'Gary A. Stafford' | |
| } | |
| } | |
| task warCopy(type: Copy) { | |
| from 'build/libs' | |
| into 'build/distributions' | |
| include '**/*.war' | |
| } | |
| task zipGetVersion (type: Task) { | |
| ext.versionfile = | |
| new File("${projectDir}/src/main/webapp/assets/buildinfo.properties") | |
| versionfile.text = 'build.version=' + artifact_version | |
| } | |
| task zipStatic(type: Zip) { | |
| from 'src/main/webapp/assets' | |
| appendix = 'static' | |
| version = '' | |
| } |
The deploy.sh file:
| #!/bin/bash | |
| set -e | |
| cd build/distributions | |
| git init | |
| git config user.name "travis-ci" | |
| git config user.email "${COMMIT_AUTHOR_EMAIL}" | |
| git add . | |
| git commit -m "Deploy Travis CI Build #${TRAVIS_BUILD_NUMBER} artifacts to GitHub" | |
| git push --force --quiet "https://${GH_TOKEN}@${GH_REF}" master:build-artifacts > /dev/null 2>&1 |
You can easily replicate the project’s continuous integration automation using your choice of toolchains. GitHub or BitBucket are good choices for distributed version control. For continuous integration and deployment, I recommend Travis CI, Semaphore, Codeship, or Jenkins. Couple those with a good persistent chat application, such as Glider Labs’ Slack or Atlassian’s HipChat.
Building the Docker Environment
Make sure VirtualBox, Docker, Docker Compose, and Docker Machine, are installed and running. At the time of this post, I have the following versions of software installed on my Mac:
- Mac OS X 10.11.6
- VirtualBox 5.0.26
- Docker 1.12.1
- Docker Compose 1.8.0
- Docker Machine 0.8.1
To build the project’s VirtualBox VM, Docker images, and Docker containers, execute the build script, using the following command: sh ./build_project.sh. A build script is useful when working with CI/CD automation tools, such as Jenkins CI or ThoughtWorks go. However, to understand the build process, I suggest first running the individual commands, locally.
| #!/bin/sh | |
| set -ex | |
| # clone project | |
| git clone -b docker_v2 --single-branch \ | |
| https://github.com/garystafford/spring-music-docker.git music \ | |
| && cd "$_" | |
| # provision VirtualBox VM | |
| docker-machine create --driver virtualbox springmusic | |
| # set new environment | |
| docker-machine env springmusic \ | |
| && eval "$(docker-machine env springmusic)" | |
| # mount a named volume on host to store mongo and elk data | |
| # ** assumes your project folder is 'music' ** | |
| docker volume create --name music_data | |
| docker volume create --name music_elk | |
| # create bridge network for project | |
| # ** assumes your project folder is 'music' ** | |
| docker network create -d bridge music_net | |
| # build images and orchestrate start-up of containers (in this order) | |
| docker-compose -p music up -d elk && sleep 15 \ | |
| && docker-compose -p music up -d mongodb && sleep 15 \ | |
| && docker-compose -p music up -d app \ | |
| && docker-compose scale app=3 && sleep 15 \ | |
| && docker-compose -p music up -d proxy && sleep 15 | |
| # optional: configure local DNS resolution for application URL | |
| #echo "$(docker-machine ip springmusic) springmusic.com" | sudo tee --append /etc/hosts | |
| # run a simple connectivity test of application | |
| for i in {1..9}; do curl -I $(docker-machine ip springmusic); done |
Deploying to AWS
By simply changing the Docker Machine driver to AWS EC2 from VirtualBox, and providing your AWS credentials, the springmusic environment may also be built on AWS.
Build Process
Docker Machine provisions a single VirtualBox springmusic VM on which host the project’s containers. VirtualBox provides a quick and easy solution that can be run locally for initial development and testing of the application.
Next, the script creates a Docker data volume and project-specific Docker bridge network.
Next, using the project’s individual Dockerfiles, Docker Compose pulls base Docker images from Docker Hub for NGINX, Tomcat, ELK, and MongoDB. Project-specific immutable Docker images are then built for NGINX, Tomcat, and MongoDB. While constructing the project-specific Docker images for NGINX and Tomcat, the latest Spring Music build artifacts are pulled and installed into the corresponding Docker images.
Docker Compose builds and deploys (6) containers onto the VirtualBox VM: (1) NGINX, (3) Tomcat, (1) MongoDB, and (1) ELK.
The NGINX Dockerfile:
| # NGINX image with build artifact | |
| FROM nginx:latest | |
| MAINTAINER Gary A. Stafford <garystafford@rochester.rr.com> | |
| ENV REFRESHED_AT 2016-09-17 | |
| ENV GITHUB_REPO https://github.com/garystafford/spring-music/raw/build-artifacts | |
| ENV STATIC_FILE spring-music-static.zip | |
| RUN apt-get update -qq \ | |
| && apt-get install -qqy curl wget unzip nano \ | |
| && apt-get clean \ | |
| \ | |
| && wget -O /tmp/${STATIC_FILE} ${GITHUB_REPO}/${STATIC_FILE} \ | |
| && unzip /tmp/${STATIC_FILE} -d /usr/share/nginx/assets/ | |
| COPY default.conf /etc/nginx/conf.d/default.conf | |
| # tweak nginx image set-up, remove log symlinks | |
| RUN rm /var/log/nginx/access.log /var/log/nginx/error.log | |
| # install Filebeat | |
| ENV FILEBEAT_VERSION=filebeat_1.2.3_amd64.deb | |
| RUN curl -L -O https://download.elastic.co/beats/filebeat/${FILEBEAT_VERSION} \ | |
| && dpkg -i ${FILEBEAT_VERSION} \ | |
| && rm ${FILEBEAT_VERSION} | |
| # configure Filebeat | |
| ADD filebeat.yml /etc/filebeat/filebeat.yml | |
| # CA cert | |
| RUN mkdir -p /etc/pki/tls/certs | |
| ADD logstash-beats.crt /etc/pki/tls/certs/logstash-beats.crt | |
| # start Filebeat | |
| ADD ./start.sh /usr/local/bin/start.sh | |
| RUN chmod +x /usr/local/bin/start.sh | |
| CMD [ "/usr/local/bin/start.sh" ] |
The Tomcat Dockerfile:
| # Apache Tomcat image with build artifact | |
| FROM tomcat:8.5.4-jre8 | |
| MAINTAINER Gary A. Stafford <garystafford@rochester.rr.com> | |
| ENV REFRESHED_AT 2016-09-17 | |
| ENV GITHUB_REPO https://github.com/garystafford/spring-music/raw/build-artifacts | |
| ENV APP_FILE spring-music.war | |
| ENV TERM xterm | |
| ENV JAVA_OPTS -Djava.security.egd=file:/dev/./urandom | |
| RUN apt-get update -qq \ | |
| && apt-get install -qqy curl wget \ | |
| && apt-get clean \ | |
| \ | |
| && touch /var/log/spring-music.log \ | |
| && chmod 666 /var/log/spring-music.log \ | |
| \ | |
| && wget -q -O /usr/local/tomcat/webapps/ROOT.war ${GITHUB_REPO}/${APP_FILE} \ | |
| && mv /usr/local/tomcat/webapps/ROOT /usr/local/tomcat/webapps/_ROOT | |
| COPY tomcat-users.xml /usr/local/tomcat/conf/tomcat-users.xml | |
| # install Filebeat | |
| ENV FILEBEAT_VERSION=filebeat_1.2.3_amd64.deb | |
| RUN curl -L -O https://download.elastic.co/beats/filebeat/${FILEBEAT_VERSION} \ | |
| && dpkg -i ${FILEBEAT_VERSION} \ | |
| && rm ${FILEBEAT_VERSION} | |
| # configure Filebeat | |
| ADD filebeat.yml /etc/filebeat/filebeat.yml | |
| # CA cert | |
| RUN mkdir -p /etc/pki/tls/certs | |
| ADD logstash-beats.crt /etc/pki/tls/certs/logstash-beats.crt | |
| # start Filebeat | |
| ADD ./start.sh /usr/local/bin/start.sh | |
| RUN chmod +x /usr/local/bin/start.sh | |
| CMD [ "/usr/local/bin/start.sh" ] |
Docker Compose v2 YAML
This post was recently updated for Docker 1.12, and to use Docker Compose v2 YAML file format. The post’s docker-compose.yml takes advantage of improvements in Docker 1.12 and Docker Compose v2 YAML. Improvements to the YAML file include eliminating the need to link containers and expose ports, and the addition of named networks and volumes.
| version: '2' | |
| services: | |
| proxy: | |
| build: nginx/ | |
| ports: | |
| - 80:80 | |
| networks: | |
| - net | |
| depends_on: | |
| - app | |
| hostname: proxy | |
| container_name: proxy | |
| app: | |
| build: tomcat/ | |
| ports: | |
| - 8080 | |
| networks: | |
| - net | |
| depends_on: | |
| - mongodb | |
| hostname: app | |
| mongodb: | |
| build: mongodb/ | |
| ports: | |
| - 27017:27017 | |
| networks: | |
| - net | |
| depends_on: | |
| - elk | |
| hostname: mongodb | |
| container_name: mongodb | |
| volumes: | |
| - music_data:/data/db | |
| - music_data:/data/configdb | |
| elk: | |
| image: sebp/elk:latest | |
| ports: | |
| - 5601:5601 | |
| - 9200:9200 | |
| - 5044:5044 | |
| - 5000:5000 | |
| networks: | |
| - net | |
| volumes: | |
| - music_elk:/var/lib/elasticsearch | |
| hostname: elk | |
| container_name: elk | |
| volumes: | |
| music_data: | |
| external: true | |
| music_elk: | |
| external: true | |
| networks: | |
| net: | |
| driver: bridge |
The Results
Below are the results of building the project.
| # Resulting Docker Machine VirtualBox VM: | |
| $ docker-machine ls | |
| NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS | |
| springmusic * virtualbox Running tcp://192.168.99.100:2376 v1.12.1 | |
| # Resulting external volume: | |
| $ docker volume ls | |
| DRIVER VOLUME NAME | |
| local music_data | |
| local music_elk | |
| # Resulting bridge network: | |
| $ docker network ls | |
| NETWORK ID NAME DRIVER SCOPE | |
| f564dfa1b440 music_net bridge local | |
| # Resulting Docker images - (4) base images and (3) project images: | |
| $ docker images | |
| REPOSITORY TAG IMAGE ID CREATED SIZE | |
| music_proxy latest 7a8dd90bcf32 About an hour ago 250.2 MB | |
| music_app latest c93c713d03b8 About an hour ago 393 MB | |
| music_mongodb latest fbcbbe9d4485 25 hours ago 366.4 MB | |
| tomcat 8.5.4-jre8 98cc750770ba 2 days ago 334.5 MB | |
| mongo latest 48b8b08dca4d 2 days ago 366.4 MB | |
| nginx latest 4efb2fcdb1ab 10 days ago 183.4 MB | |
| sebp/elk latest 07a3e78b01f5 13 days ago 884.5 MB | |
| # Resulting (6) Docker containers | |
| $ docker ps | |
| CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES | |
| b33922767517 music_proxy "/usr/local/bin/start" 3 hours ago Up 13 minutes 0.0.0.0:80->80/tcp, 443/tcp proxy | |
| e16d2372f2df music_app "/usr/local/bin/start" 3 hours ago Up About an hour 0.0.0.0:32770->8080/tcp music_app_3 | |
| 6b7accea7156 music_app "/usr/local/bin/start" 3 hours ago Up About an hour 0.0.0.0:32769->8080/tcp music_app_2 | |
| 2e94f766df1b music_app "/usr/local/bin/start" 3 hours ago Up About an hour 0.0.0.0:32768->8080/tcp music_app_1 | |
| 71f8dc574148 sebp/elk:latest "/usr/local/bin/start" 3 hours ago Up About an hour 0.0.0.0:5000->5000/tcp, 0.0.0.0:5044->5044/tcp, 0.0.0.0:5601->5601/tcp, 0.0.0.0:9200->9200/tcp, 9300/tcp elk | |
| f7e7d1af7cca music_mongodb "/entrypoint.sh mongo" 20 hours ago Up About an hour 0.0.0.0:27017->27017/tcp mongodb |
Testing the Application
Below are partial results of the curl test, hitting the NGINX endpoint. Note the different IP addresses in the Upstream-Address field between requests. This test proves NGINX’s round-robin load-balancing is working across the three Tomcat application instances: music_app_1, music_app_2, and music_app_3.
Also, note the sharp decrease in the Request-Time between the first three requests and subsequent three requests. The Upstream-Response-Time to the Tomcat instances doesn’t change, yet the total Request-Time is much shorter, due to caching of the application’s static assets by NGINX.
| for i in {1..6}; do curl -I $(docker-machine ip springmusic);done | |
| HTTP/1.1 200 | |
| Server: nginx/1.11.4 | |
| Date: Sat, 17 Sep 2016 18:33:50 GMT | |
| Content-Type: text/html;charset=ISO-8859-1 | |
| Content-Length: 2094 | |
| Connection: keep-alive | |
| Accept-Ranges: bytes | |
| ETag: W/"2094-1473924940000" | |
| Last-Modified: Thu, 15 Sep 2016 07:35:40 GMT | |
| Content-Language: en | |
| Request-Time: 0.575 | |
| Upstream-Address: 172.18.0.4:8080 | |
| Upstream-Response-Time: 1474137230.048 | |
| HTTP/1.1 200 | |
| Server: nginx/1.11.4 | |
| Date: Sat, 17 Sep 2016 18:33:51 GMT | |
| Content-Type: text/html;charset=ISO-8859-1 | |
| Content-Length: 2094 | |
| Connection: keep-alive | |
| Accept-Ranges: bytes | |
| ETag: W/"2094-1473924940000" | |
| Last-Modified: Thu, 15 Sep 2016 07:35:40 GMT | |
| Content-Language: en | |
| Request-Time: 0.711 | |
| Upstream-Address: 172.18.0.5:8080 | |
| Upstream-Response-Time: 1474137230.865 | |
| HTTP/1.1 200 | |
| Server: nginx/1.11.4 | |
| Date: Sat, 17 Sep 2016 18:33:52 GMT | |
| Content-Type: text/html;charset=ISO-8859-1 | |
| Content-Length: 2094 | |
| Connection: keep-alive | |
| Accept-Ranges: bytes | |
| ETag: W/"2094-1473924940000" | |
| Last-Modified: Thu, 15 Sep 2016 07:35:40 GMT | |
| Content-Language: en | |
| Request-Time: 0.326 | |
| Upstream-Address: 172.18.0.6:8080 | |
| Upstream-Response-Time: 1474137231.812 | |
| # assets now cached... | |
| HTTP/1.1 200 | |
| Server: nginx/1.11.4 | |
| Date: Sat, 17 Sep 2016 18:33:53 GMT | |
| Content-Type: text/html;charset=ISO-8859-1 | |
| Content-Length: 2094 | |
| Connection: keep-alive | |
| Accept-Ranges: bytes | |
| ETag: W/"2094-1473924940000" | |
| Last-Modified: Thu, 15 Sep 2016 07:35:40 GMT | |
| Content-Language: en | |
| Request-Time: 0.012 | |
| Upstream-Address: 172.18.0.4:8080 | |
| Upstream-Response-Time: 1474137233.111 | |
| HTTP/1.1 200 | |
| Server: nginx/1.11.4 | |
| Date: Sat, 17 Sep 2016 18:33:53 GMT | |
| Content-Type: text/html;charset=ISO-8859-1 | |
| Content-Length: 2094 | |
| Connection: keep-alive | |
| Accept-Ranges: bytes | |
| ETag: W/"2094-1473924940000" | |
| Last-Modified: Thu, 15 Sep 2016 07:35:40 GMT | |
| Content-Language: en | |
| Request-Time: 0.017 | |
| Upstream-Address: 172.18.0.5:8080 | |
| Upstream-Response-Time: 1474137233.350 | |
| HTTP/1.1 200 | |
| Server: nginx/1.11.4 | |
| Date: Sat, 17 Sep 2016 18:33:53 GMT | |
| Content-Type: text/html;charset=ISO-8859-1 | |
| Content-Length: 2094 | |
| Connection: keep-alive | |
| Accept-Ranges: bytes | |
| ETag: W/"2094-1473924940000" | |
| Last-Modified: Thu, 15 Sep 2016 07:35:40 GMT | |
| Content-Language: en | |
| Request-Time: 0.013 | |
| Upstream-Address: 172.18.0.6:8080 | |
| Upstream-Response-Time: 1474137233.594 |
Spring Music Application Links
Assuming the springmusic VM is running at 192.168.99.100, the following links can be used to access various project endpoints. Note the (3) Tomcat instances each map to randomly exposed ports. These ports are not required by NGINX, which maps to port 8080 for each instance. The port is only required if you want access to the Tomcat Web Console. The port, shown below, 32771, is merely used as an example.
- Spring Music Application: 192.168.99.100
- NGINX Status: 192.168.99.100/nginx_status
- Tomcat Web Console – music_app_1*: 192.168.99.100:32771/manager
- Environment Variables – music_app_1: 192.168.99.100:32771/env
- Album List (RESTful endpoint) – music_app_1: 192.168.99.100:32771/albums
- Elasticsearch Info: 192.168.99.100:9200
- Elasticsearch Status: 192.168.99.100:9200/_status?pretty
- Kibana Web Console: 192.168.99.100:5601
* The Tomcat user name is admin and the password is t0mcat53rv3r.
Helpful Links
- Cloud Foundry’s Spring Music Example
- Getting Started with Gradle for Java
- Introduction to Gradle
- Spring Framework
- Understanding Nginx HTTP Proxying, Load Balancing, Buffering, and Caching
- Common conversion patterns for log4j’s PatternLayout
- Spring @PropertySource example
- Java log4j logging
TODOs
- Automate the Docker image build and publish processes
- Automate the Docker container build and deploy processes
- Automate post-deployment verification testing of project infrastructure
- Add Docker Swarm multi-host capabilities with overlay networking
- Update Spring Music with latest CF project revisions
- Include scripting example to stand-up project on AWS
- Add Consul and Consul Template for NGINX configuration
Diving Deeper into ‘Getting Started with Spring Cloud’
Posted by Gary A. Stafford in DevOps, Enterprise Software Development, Java Development, Software Development on February 15, 2016

Explore the integration of Spring Cloud and Spring Cloud Netflix tooling, through a deep dive into Pivotal’s ‘Getting Started with Spring Cloud’ presentation.
Introduction
Keeping current with software development and DevOps trends can often make us feel we are, as the overused analogy describes, drinking from a firehose, often several hoses at once. Recently joining a large client engagement, I found it necessary to supplement my knowledge of cloud-native solutions, built with the support of Spring Cloud and Spring Cloud Netflix technologies. One of my favorite sources of information on these subjects is presentations by people like Josh Long, Dr. Dave Syer, and Cornelia Davis of Pivotal Labs, and Jon Schneider and Taylor Wicksell of Netflix.
One presentation, in particular, Getting Started with Spring Cloud, by Long and Syer, provides an excellent end-to-end technical overview of the latest Spring and Netflix technologies. Josh Long’s fast-paced, eighty-minute presentation, available on YouTube, was given at SpringOne2GX 2015 with co-presenter, Dr. Dave Syer, founder of Spring Cloud, Spring Boot, and Spring Batch.
As the presenters of Getting Started with Spring Cloud admit, the purpose of the presentation was to get people excited about Spring Cloud and Netflix technologies, not to provide a deep dive into each technology. However, I believe the presentation’s Reservation Service example provides an excellent learning opportunity. In the following post, we will examine the technologies, components, code, and configuration presented in Getting Started with Spring Cloud. The goal of the post is to provide a greater understanding of the Spring Cloud and Spring Cloud Netflix technologies.
System Overview
Technologies
The presentation’s example introduces a dizzying array of technologies, which include:
Spring Boot
Stand-alone, production-grade Spring-based applications
Spring Data REST / Spring HATEOAS
Spring-based applications following HATEOAS principles
Spring Cloud Config
Centralized external configuration management, backed by Git
Netflix Eureka
REST-based service discovery and registration for failover and load-balancing
Netflix Ribbon
IPC library with built-in client-side software load-balancers
Netflix Zuul
Dynamic routing, monitoring, resiliency, security, and more
Netflix Hystrix
Latency and fault tolerance for distributed system
Netflix Hystrix Dashboard
Web-based UI for monitoring Hystrix
Spring Cloud Stream
Messaging microservices, backed by Redis
Spring Data Redis
Configuration and access to Redis from a Spring app, using Jedis
Spring Cloud Sleuth
Distributed tracing solution for Spring Cloud, sends traces via Thrift to the Zipkin collector service
Twitter Zipkin
Distributed tracing system, backed by Apache Cassandra
H2
In-memory Java SQL database, embedded and server modes
Docker
Package applications with dependencies into standardized Linux containers
System Components
Several components and component sub-systems comprise the presentation’s overall Reservation Service example. Each component implements a combination of the technologies mentioned above. Below is a high-level architectural diagram of the presentation’s example. It includes a few additional features, added as part of this post.

Individual system components include:
Spring Cloud Config Server
Stand-alone Spring Boot application provides centralized external configuration to multiple Reservation system components
Spring Cloud Config Git Repo
Git repository containing multiple Reservation system components configuration files, served by Spring Cloud Config Server
H2 Java SQL Database Server (New)
This post substitutes the original example’s use of H2’s embedded version with a TCP Server instance, shared by Reservation Service instances
Reservation Service
Multi load-balanced instances of stand-alone Spring Boot application, backed by H2 database
Reservation Client
Stand-alone Spring Boot application (aka edge service or client-side proxy), forwards client-side load-balanced requests to the Reservation Service, using Eureka, Zuul, and Ribbon
Reservation Data Seeder (New)
Stand-alone Spring Boot application, seeds H2 with initial data, instead of the Reservation Service
Eureka Service
Stand-alone Spring Boot application provides service discovery and registration for failover and load-balancing
Hystrix Dashboard
Stand-alone Spring Boot application provides web-based Hystrix UI for monitoring system performance and Hystrix circuit-breakers
Zipkin
Zipkin Collector, Query, and Web, and Cassandra database, receives, correlates, and displays traces from Spring Cloud Sleuth
Redis
In-memory data structure store, acting as message broker/transport for Spring Cloud Stream
Github
All the code for this post is available on Github, split between two repositories. The first repository, spring-cloud-demo, contains the source code for all of the components listed above, except the Spring Cloud Config Git Repo. To function correctly, the configuration files, consumed by the Spring Cloud Config Server, needs to be placed into a separate repository, spring-cloud-demo-config-repo.
The first repository contains a git submodule , docker-zipkin. If you are not familiar with submodules, you may want to take a moment to read the git documentation. The submodule contains a dockerized version of Twitter’s OpenZipkin, docker-zipkin. To clone the two repositories, use the following commands. The --recursive option is required to include the docker-zipkin submodule in the project.
| git clone https://github.com/garystafford/spring-cloud-demo-config-repo.git | |
| git clone --recursive https://github.com/garystafford/spring-cloud-demo.git |
Configuration
To try out the post’s Reservation system example, you need to configure at least one property. The Spring Cloud Config Server needs to know the location of the Spring Cloud Config Repository, which is the second GitHub repository you cloned, spring-cloud-demo-config-repo. From the root of the spring-cloud-demo repo, edit the Spring Cloud Config Server application.properties file, located in config-server/src/main/resources/application.properties. Change the following property’s value to your local path to the spring-cloud-demo-config-repo repository:
| spring.cloud.config.server.git.uri=file:<YOUR_PATH_GOES_HERE>/spring-cloud-demo-config-repo |
Startup
There are a few ways you could run the multiple components that make up the post’s example. I suggest running one component per terminal window, in the foreground. In this way, you can monitor the output from the bootstrap and startup processes of the system’s components. Furthermore, you can continue to monitor the system’s components once they are up and running, and receiving traffic. Yes, that is twelve terminal windows…

There is a required startup order for the components. For example, Spring Cloud Config Server needs to start before the other components that rely on it for configuration. Netflix’s Eureka needs to start before the Reservation Client and ReservationServices, so they can register with Eureka on startup. Similarly, Zipkin needs to be started in its Docker container before the Reservation Client and Services, so Spring Cloud Sleuth can start sending traces. Redis needs to be started in its Docker container before Spring Cloud Stream tries to create the message queue. All instances of the Reservation Service needs to start before the Reservation Client. Once every component is started, the Reservation Data Seeder needs to be run once to create initial data in H2. For best results, follow the instructions below. Let each component start completely, before starting the next component.
| # IMPORTANT: set this to the spring-cloud-demo repo directory | |
| export SPRING_DEMO=<YOUR_PATH_GOES_HERE>/spring-cloud-demo | |
| # Redis - on Mac, in Docker Quickstart Terminal | |
| cd ${SPRING_DEMO}/docker-redis/ | |
| docker-compose up | |
| # Zipkin - on Mac, in Docker Quickstart Terminal | |
| cd ${SPRING_DEMO}/docker-zipkin/ | |
| docker-compose up | |
| # *** MAKE SURE ZIPKIN STARTS SUCCESSFULLY! *** | |
| # *** I HAVE TO RESTART >50% OF TIME... *** | |
| # H2 Database Server - in new terminal window | |
| cd ${SPRING_DEMO}/h2-server | |
| java -cp h2*.jar org.h2.tools.Server -webPort 6889 | |
| # Spring Cloud Config Server - in new terminal window | |
| cd ${SPRING_DEMO}/config-server | |
| mvn clean package spring-boot:run | |
| # Eureka Service - in new terminal window | |
| cd ${SPRING_DEMO}/eureka-server | |
| mvn clean package spring-boot:run | |
| # Hystrix Dashboard - in new terminal window | |
| cd ${SPRING_DEMO}/hystrix-dashboard | |
| mvn clean package spring-boot:run | |
| # Reservation Service - instance 1 - in new terminal window | |
| cd ${SPRING_DEMO}/reservation-service | |
| mvn clean package | |
| mvn spring-boot:run -Drun.jvmArguments='-Dserver.port=8000' | |
| # Reservation Service - instance 2 - in new terminal window | |
| cd ${SPRING_DEMO}/reservation-service | |
| mvn spring-boot:run -Drun.jvmArguments='-Dserver.port=8001' | |
| # Reservation Service - instance 3 - in new terminal window | |
| cd ${SPRING_DEMO}/reservation-service | |
| mvn spring-boot:run -Drun.jvmArguments='-Dserver.port=8002' | |
| # Reservation Client - in new terminal window | |
| cd ${SPRING_DEMO}/reservation-client | |
| mvn clean package spring-boot:run | |
| # Load seed data into H2 - in new terminal window | |
| cd ${SPRING_DEMO}/reservation-data-seeder | |
| mvn clean package spring-boot:run | |
| # Redis redis-cli monitor - on Mac, in new Docker Quickstart Terminal | |
| docker exec -it dockerredis_redis_1 redis-cli | |
| 127.0.0.1:6379> monitor |
Docker
Both Zipkin and Redis run in Docker containers. Redis runs in a single container. Zipkin’s four separate components run in four separate containers. Be advised, Zipkin seems to have trouble successfully starting all four of its components on a consistent basis. I believe it’s a race condition caused by Docker Compose simultaneously starting the four Docker containers, ignoring a proper startup order. More than half of the time, I have to stop Zipkin and rerun the docker command to get Zipkin to start without any errors.
If you’ve followed the instructions above, you should see the following Docker images and Docker containers installed and running in your local environment.
| docker is configured to use the default machine with IP 192.168.99.100 | |
| gstafford@nagstaffo:~$ docker images | |
| REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE | |
| redis latest 8bccd73928d9 5 weeks ago 151.3 MB | |
| openzipkin/zipkin-cassandra 1.30.0 8bbc92bceff0 5 weeks ago 221.9 MB | |
| openzipkin/zipkin-web 1.30.0 c854ecbcef86 5 weeks ago 155.1 MB | |
| openzipkin/zipkin-query 1.30.0 f0c45a26988a 5 weeks ago 180.3 MB | |
| openzipkin/zipkin-collector 1.30.0 5fcf0ba455a0 5 weeks ago 183.8 MB | |
| gstafford@nagstaffo:~$ docker ps -a | |
| CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES | |
| 1fde6bb2dc99 openzipkin/zipkin-web:1.30.0 "/usr/local/bin/run" 3 weeks ago Up 11 days 0.0.0.0:8080->8080/tcp, 0.0.0.0:9990->9990/tcp dockerzipkin_web_1 | |
| 16e65180296e openzipkin/zipkin-query:1.30.0 "/usr/local/bin/run.s" 3 weeks ago Up 11 days 0.0.0.0:9411->9411/tcp, 0.0.0.0:9901->9901/tcp dockerzipkin_query_1 | |
| b1ca16408274 openzipkin/zipkin-collector:1.30.0 "/usr/local/bin/run.s" 3 weeks ago Up 11 days 0.0.0.0:9410->9410/tcp, 0.0.0.0:9900->9900/tcp dockerzipkin_collector_1 | |
| c7195ee9c4ff openzipkin/zipkin-cassandra:1.30.0 "/bin/sh -c /usr/loca" 3 weeks ago Up 11 days 7000-7001/tcp, 7199/tcp, 9160/tcp, 0.0.0.0:9042->9042/tcp dockerzipkin_cassandra_1 | |
| fe0396908e29 redis "/entrypoint.sh redis" 3 weeks ago Up 11 days 0.0.0.0:6379->6379/tcp dockerredis_redis_1 |
Components
Spring Cloud Config Server
At the center of the Reservation system is Spring Cloud Config. Configuration, typically found in the application.properties file, for the Reservation Services, Reservation Client, Reservation Data Seeder, Eureka Service, and Hystix Dashboard, has been externalized with Spring Cloud Config.
Each component has a bootstrap.properties file, which modifies its startup behavior during the bootstrap phase of an application context. Each bootstrap.properties file contains the component’s name and the address of the Spring Cloud Config Server. Components retrieve their configuration from the Spring Cloud Config Server at runtime. Below, is an example of the Reservation Client’s bootstrap.properties file.
| # reservation client bootstrap props | |
| spring.application.name=reservation-client | |
| spring.cloud.config.uri=http://localhost:8888 |
Spring Cloud Config Git Repo
In the presentation, as in this post, the Spring Cloud Config Server is backed by a locally cloned Git repository, the Spring Cloud Config Git Repo. The Spring Cloud Config Server’s application.properties file contains the address of the Git repository. Each properties file within the Git repository corresponds to a system component. Below, is an example of the reservation-client.properties file, from the Spring Cloud Config Git Repo.
| # reservation client app props | |
| server.port=8050 | |
| message=Spring Cloud Config: Reservation Client | |
| # spring cloud stream / redis | |
| spring.cloud.stream.bindings.output=reservations | |
| spring.redis.host=192.168.99.100 | |
| spring.redis.port=6379 | |
| # zipkin / spring cloud sleuth | |
| spring.zipkin.host=192.168.99.100 | |
| spring.zipkin.port=9410 |
As shown in the original presentation, the configuration files can be viewed using HTTP endpoints of the Spring Cloud Config Server. To view the Reservation Service’s configuration stored in the Spring Cloud Config Git Repo, issue an HTTP GET request to http://localhost:8888/reservation-service/master. The master URI refers to the Git repo branch in which the configuration resides. This will return the configuration, in the response body, as JSON:

In a real Production environment, the Spring Cloud Config Server would be backed by a highly-available Git Server or GitHub repository.
Reservation Service
The Reservation Service is the core component in the presentation’s example. The Reservation Service is a stand-alone Spring Boot application. By implementing Spring Data REST and Spring HATEOAS, Spring automatically creates REST representations from the Reservation JPA Entity class of the Reservation Service. There is no need to write a Spring Rest Controller and explicitly code each endpoint.

Spring HATEOAS allows us to interact with the Reservation Entity, using HTTP methods, such as GET and POST. These endpoints, along with all addressable endpoints, are displayed in the terminal output when a Spring Boot application starts. For example, we can use an HTTP GET request to call the reservations/{id} endpoint, such as:
| curl -X GET -H "Content-Type: application/json" \ | |
| --url 'http://localhost:8000/reservations' | |
| curl -X GET -H "Content-Type: application/json" \ | |
| --url 'http://localhost:8000/reservations/2' |
The Reservation Service also makes use of the Spring RepositoryRestResource annotation. By annotating the RepositoryReservation Interface, which extends JpaRepository, we can customize export mapping and relative paths of the Reservation JPA Entity class. As shown below, the RepositoryReservation Interface contains the findByReservationName method signature, annotated with /by-name endpoint, which accepts the rn input parameter.
| @RepositoryRestResource | |
| interface ReservationRepository extends JpaRepository<Reservation, Long> { | |
| @RestResource(path = "by-name") | |
| Collection<Reservation> findByReservationName(@Param("rn") String rn); | |
| } |
Calling the findByReservationName method, we can search for a particular reservation by using an HTTP GET request to call the reservations/search/by-name?rn={reservationName} endpoint.
| curl -X GET -H "Content-Type: application/json" \ | |
| --url 'http://localhost:8000/reservations/search/by-name?rn=Amit' |

Reservation Client
Querying the Reservation Service directly is possible, however, is not the recommended. Instead, the presentation suggests using the Reservation Client as a proxy to the Reservation Service. The presentation offers three examples of using the Reservation Client as a proxy.
The first demonstration of the Reservation Client uses the /message endpoint on the Reservation Client to return a string from the Reservation Service. The message example has been modified to include two new endpoints on the Reservation Client. The first endpoint, /reservations/client-message, returns a message directly from the Reservation Client. The second endpoint, /reservations/service-message, returns a message indirectly from the Reservation Service. To retrieve the message from the Reservation Service, the Reservation Client sends a request to the endpoint Reservation Service’s /message endpoint.
| @RequestMapping(path = "/client-message", method = RequestMethod.GET) | |
| public String getMessage() { | |
| return this.message; | |
| } | |
| @RequestMapping(path = "/service-message", method = RequestMethod.GET) | |
| public String getReservationServiceMessage() { | |
| return this.restTemplate.getForObject( | |
| "http://reservation-service/message", | |
| String.class); | |
| } |
To retrieve both messages, send separate HTTP GET requests to each endpoint:
| curl 'http://localhost:8050/reservations/client-message' | |
| curl 'http://localhost:8050/reservations/service-message' |

The second demonstration of the Reservation Client uses a Data Transfer Object (DTO). Calling the Reservation Client’s reservations/names endpoint, invokes the getReservationNames method. This method, in turn, calls the Reservation Service’s /reservations endpoint. The response object returned from the Reservation Service, a JSON array of reservation records, is deserialized and mapped to the Reservation Client’s Reservation DTO. Finally, the method returns a collection of strings, representing just the names from the reservations.
| @RequestMapping(path = "/names", method = RequestMethod.GET) | |
| public Collection<String> getReservationNames() { | |
| ParameterizedTypeReference<Resources<Reservation>> ptr = | |
| new ParameterizedTypeReference<Resources<Reservation>>() {}; | |
| return this.restTemplate.exchange("http://reservation-service/reservations", GET, null, ptr) | |
| .getBody() | |
| .getContent() | |
| .stream() | |
| .map(Reservation::getReservationName) | |
| .collect(toList()); | |
| } |
To retrieve the collection of reservation names, an HTTP GET request is sent to the /reservations/names endpoint:
| curl 'http://localhost:8050/reservations/names' |

Spring Cloud Stream
One of the more interesting technologies in the presentation is Spring’s Spring Cloud Stream. The Spring website describes Spring Cloud Stream as a project that allows users to develop and run messaging microservices using Spring Integration. In other words, it provides native Spring messaging capabilities, backed by a choice of message buses, including Redis, RabbitMQ, and Apache Kafka, to Spring Boot applications.
A detailed explanation of Spring Cloud Stream would take an entire post. The best technical demonstration I have found is the presentation, Message Driven Microservices in the Cloud, by speakers Dr. David Syer and Dr. Mark Pollack, given in January 2016, also at SpringOne2GX 2015.

In the presentation, a new reservation is submitted via an HTTP POST to the acceptNewReservations method of the Reservation Client. The method, in turn, builds (aka produces) a message, containing the new reservation, and publishes that message to the queue.reservation queue.
| @Autowired | |
| @Output(OUTPUT) | |
| private MessageChannel messageChannel; | |
| @Value("${message}") | |
| private String message; | |
| @Description("Post new reservations using Spring Cloud Stream") | |
| @RequestMapping(method = POST) | |
| public void acceptNewReservations(@RequestBody Reservation r) { | |
| Message<String> build = withPayload(r.getReservationName()).build(); | |
| this.messageChannel.send(build); | |
| } |
The queue.reservation queue is located in Redis, which is running inside a Docker container. To view the messages being published to the queue in real-time, use the redis-cli, with the monitor command, from within the Redis Docker container. Below is an example of tests messages pushed (LPUSH) to the reservations queue from the Reservation Client.
| gstafford@nagstaffo:~$ docker exec -it dockerredis_redis_1 redis-cli | |
| 127.0.0.1:6379> monitor | |
| OK | |
| 1455332771.709412 [0 192.168.99.1:62177] "BRPOP" "queue.reservations" "1" | |
| 1455332772.110386 [0 192.168.99.1:59782] "BRPOP" "queue.reservations" "1" | |
| 1455332773.689777 [0 192.168.99.1:62183] "LPUSH" "queue.reservations" "\xff\x04\x0bcontentType\x00\x00\x00\x0c\"text/plain\"\tX-Span-Id\x00\x00\x00&\"49a5b1d1-e7e9-46de-9d9f-647d5b19a77b\"\nX-Trace-Id\x00\x00\x00&\"49a5b1d1-e7e9-46de-9d9f-647d5b19a77b\"\x0bX-Span-Name\x00\x00\x00\x13\"http/reservations\"Test-Name-01" | |
| 1455332777.124788 [0 192.168.99.1:59782] "BRPOP" "queue.reservations" "1" | |
| 1455332777.425655 [0 192.168.99.1:59776] "BRPOP" "queue.reservations" "1" | |
| 1455332777.581693 [0 192.168.99.1:62183] "LPUSH" "queue.reservations" "\xff\x04\x0bcontentType\x00\x00\x00\x0c\"text/plain\"\tX-Span-Id\x00\x00\x00&\"32db0e25-982a-422f-88bb-2e7c2e4ce393\"\nX-Trace-Id\x00\x00\x00&\"32db0e25-982a-422f-88bb-2e7c2e4ce393\"\x0bX-Span-Name\x00\x00\x00\x13\"http/reservations\"Test-Name-02" | |
| 1455332781.442398 [0 192.168.99.1:59776] "BRPOP" "queue.reservations" "1" | |
| 1455332781.643077 [0 192.168.99.1:62177] "BRPOP" "queue.reservations" "1" | |
| 1455332781.669264 [0 192.168.99.1:62183] "LPUSH" "queue.reservations" "\xff\x04\x0bcontentType\x00\x00\x00\x0c\"text/plain\"\tX-Span-Id\x00\x00\x00&\"85ebf225-3324-434e-ba38-17411db745ac\"\nX-Trace-Id\x00\x00\x00&\"85ebf225-3324-434e-ba38-17411db745ac\"\x0bX-Span-Name\x00\x00\x00\x13\"http/reservations\"Test-Name-03" | |
| 1455332785.452291 [0 192.168.99.1:59776] "BRPOP" "queue.reservations" "1" | |
| 1455332785.652809 [0 192.168.99.1:62177] "BRPOP" "queue.reservations" "1" | |
| 1455332785.706438 [0 192.168.99.1:62183] "LPUSH" "queue.reservations" "\xff\x04\x0bcontentType\x00\x00\x00\x0c\"text/plain\"\tX-Span-Id\x00\x00\x00&\"aaad3210-cfda-49b9-ba34-a1e8c1b2995c\"\nX-Trace-Id\x00\x00\x00&\"aaad3210-cfda-49b9-ba34-a1e8c1b2995c\"\x0bX-Span-Name\x00\x00\x00\x13\"http/reservations\"Test-Name-04" | |
| 1455332789.665349 [0 192.168.99.1:62177] "BRPOP" "queue.reservations" "1" | |
| 1455332789.764794 [0 192.168.99.1:59782] "BRPOP" "queue.reservations" "1" | |
| 1455332790.064547 [0 192.168.99.1:62183] "LPUSH" "queue.reservations" "\xff\x04\x0bcontentType\x00\x00\x00\x0c\"text/plain\"\tX-Span-Id\x00\x00\x00&\"545ce7b9-7ba4-42ae-8d2a-374ec7914240\"\nX-Trace-Id\x00\x00\x00&\"545ce7b9-7ba4-42ae-8d2a-374ec7914240\"\x0bX-Span-Name\x00\x00\x00\x13\"http/reservations\"Test-Name-05" | |
| 1455332790.070190 [0 192.168.99.1:59776] "BRPOP" "queue.reservations" "1" | |
| 1455332790.669056 [0 192.168.99.1:62177] "BRPOP" "queue.reservations" "1" |
The published messages are consumed by subscribers to the reservation queue. In this example, the consumer is the Reservation Service. The Reservation Service’s acceptNewReservation method processes the message and saves the new reservation to the H2 database. In Spring Cloud Stream terms, the Reservation Client is the Sink.
| @MessageEndpoint | |
| class ReservationProcessor { | |
| @Autowired | |
| private ReservationRepository reservationRepository; | |
| @ServiceActivator(inputChannel = INPUT) | |
| public void acceptNewReservation(String rn) { | |
| this.reservationRepository.save(new Reservation(rn)); | |
| } | |
| } |
Netflix Eureka
Netflix’s Eureka, in combination with Netflix’s Zuul and Ribbon, provide the ability to scale the Reservation Service horizontally, and to load balance those instances. By using the @EnableEurekaClient annotation on the Reservation Client and Reservation Services, each instance will automatically register with Eureka on startup, as shown in the Eureka Web UI, below.

The names of the registered instances are in three parts: the address of the host on which the instance is running, followed by the value of the spring.application.name property of the instance’s bootstrap.properties file, and finally, the port number the instance is running on. Eureka displays each instance’s status, along with additional AWS information, if you are running on AWS, as Netflix does.

According to Spring in their informative post, Spring Cloud, service discovery is one of the key tenets of a microservice based architecture. Trying to hand-configure each client, or to rely on convention over configuration, can be difficult to do and is brittle. Eureka is the Netflix Service Discovery Server and Client. A client (Spring Boot application), registers with Eureka, providing metadata about itself. Eureka then receives heartbeat messages from each instance. If the heartbeat fails over a configurable timetable, the instance is normally removed from the registry.
The Reservation Client application is also annotated with @EnableZuulProxy. Adding this annotation pulls in Spring Cloud’s embedded Zuul proxy. Again, according to Spring, the proxy is used by front-end applications to proxy calls to one or more back-end services, avoiding the need to manage CORS and authentication concerns independently for all the backends. In the presentation and this post, the front end is the Reservation Client and the back end is the Reservation Service.
In the code snippet below from the ReservationApiGatewayRestController, note the URL of the endpoint requested in the getReservationNames method. Instead of directly calling http://localhost:8000/reservations, the method calls http://reservation-service/reservations. The reservation-service segment of the URL is the registered name of the service in Eureka and contained in the Reservation Service’s bootstrap.properties file.
| @RequestMapping(path = "/names", method = RequestMethod.GET) | |
| public Collection<String> getReservationNames() { | |
| ParameterizedTypeReference<Resources<Reservation>> ptr = | |
| new ParameterizedTypeReference<Resources<Reservation>>() {}; | |
| return this.restTemplate.exchange("http://reservation-service/reservations", GET, null, ptr) | |
| .getBody() | |
| .getContent() | |
| .stream() | |
| .map(Reservation::getReservationName) | |
| .collect(toList()); | |
| } |
In the following abridged output from the Reservation Client, you can clearly see the interaction of Zuul, Ribbon, Eureka, and Spring Cloud Config. Note the Client application has successfully registering itself with Eureka, along with the Reservation Client’s status. Also, note Zuul mapping the Reservation Service’s URL path.
| 2016-01-28 00:00:03.667 INFO 17223 --- [ main] com.netflix.discovery.DiscoveryClient : Getting all instance registry info from the eureka server | |
| 2016-01-28 00:00:03.813 INFO 17223 --- [ main] com.netflix.discovery.DiscoveryClient : The response status is 200 | |
| 2016-01-28 00:00:03.814 INFO 17223 --- [ main] com.netflix.discovery.DiscoveryClient : Starting heartbeat executor: renew interval is: 30 | |
| 2016-01-28 00:00:03.817 INFO 17223 --- [ main] c.n.discovery.InstanceInfoReplicator : InstanceInfoReplicator onDemand update allowed rate per min is 4 | |
| 2016-01-28 00:00:03.935 INFO 17223 --- [ main] c.n.e.EurekaDiscoveryClientConfiguration : Registering application reservation-client with eureka with status UP | |
| 2016-01-28 00:00:03.936 INFO 17223 --- [ main] com.netflix.discovery.DiscoveryClient : Saw local status change event StatusChangeEvent [current=UP, previous=STARTING] | |
| 2016-01-28 00:00:03.941 INFO 17223 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_RESERVATION-CLIENT/192.168.99.1:reservation-client:8050: registering service... | |
| 2016-01-28 00:00:03.942 INFO 17223 --- [ main] o.s.c.n.zuul.web.ZuulHandlerMapping : Mapped URL path [/reservation-service/**] onto handler of type [class org.springframework.cloud.netflix.zuul.web.ZuulController] | |
| 2016-01-28 00:00:03.981 INFO 17223 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_RESERVATION-CLIENT/192.168.99.1:reservation-client:8050 - registration status: 204 | |
| 2016-01-28 00:00:04.075 INFO 17223 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8050 (http) | |
| 2016-01-28 00:00:04.076 INFO 17223 --- [ main] c.n.e.EurekaDiscoveryClientConfiguration : Updating port to 8050 | |
| 2016-01-28 00:00:04.080 INFO 17223 --- [ main] c.example.ReservationClientApplication : Started ReservationClientApplication in 9.172 seconds (JVM running for 12.536) |
Load Balancing
One shortcoming of the original presentation was true load balancing. With only a single instance of the Reservation Service in the original presentation, there is nothing to load balance; it’s more of a reverse proxy example. To demonstrate load balancing, we need to spin up additional instances of the Reservation Service. Following the post’s component start-up instructions, we should have three instances of the Reservation Service running, on ports 8000, 8001, and 8002, each in separate terminal windows.
To confirm the three instances of the Reservation Service were successfully registered with Eureka, review the output from the Eureka Server terminal window. The output should show three instances of the Reservation Service registering on startup, in addition to the Reservation Client.
| 2016-01-27 23:34:40.496 INFO 16668 --- [nio-8761-exec-9] c.n.e.registry.AbstractInstanceRegistry : Registered instance RESERVATION-SERVICE/192.168.99.1:reservation-service:8000 with status UP (replication=false) | |
| 2016-01-27 23:34:53.167 INFO 16668 --- [nio-8761-exec-7] c.n.e.registry.AbstractInstanceRegistry : Registered instance RESERVATION-SERVICE/192.168.99.1:reservation-service:8001 with status UP (replication=false) | |
| 2016-01-27 23:34:55.924 INFO 16668 --- [nio-8761-exec-1] c.n.e.registry.AbstractInstanceRegistry : Registered instance RESERVATION-SERVICE/192.168.99.1:reservation-service:8002 with status UP (replication=false) | |
| 2016-01-27 23:40:35.963 INFO 16668 --- [nio-8761-exec-5] c.n.e.registry.AbstractInstanceRegistry : Registered instance RESERVATION-CLIENT/192.168.99.1:reservation-client:8050 with status UP (replication=false) |
Viewing Eureka’s web console, we should observe three members in the pool of Reservation Services.

Lastly, looking at the terminal output of the Reservation Client, we should see three instances of the Reservation Service being returned by Ribbon (aka the DynamicServerListLoadBalancer).
| 2016-01-27 23:41:01.357 INFO 17125 --- [estController-1] c.netflix.config.ChainedDynamicProperty : Flipping property: reservation-service.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647 | |
| 2016-01-27 23:41:01.359 INFO 17125 --- [estController-1] c.n.l.DynamicServerListLoadBalancer : DynamicServerListLoadBalancer for client reservation-service initialized: DynamicServerListLoadBalancer:{NFLoadBalancer:name=reservation-service,current list of Servers=[192.168.99.1:8000, 192.168.99.1:8002, 192.168.99.1:8001],Load balancer stats=Zone stats: {defaultzone=[Zone:defaultzone; Instance count:3; Active connections count: 0; Circuit breaker tripped count: 0; Active connections per server: 0.0;] | |
| },Server stats: [[Server:192.168.99.1:8000; Zone:defaultZone; Total Requests:0; Successive connection failure:0; Total blackout seconds:0; Last connection made:Wed Dec 31 19:00:00 EST 1969; First connection made: Wed Dec 31 19:00:00 EST 1969; Active Connections:0; total failure count in last (1000) msecs:0; average resp time:0.0; 90 percentile resp time:0.0; 95 percentile resp time:0.0; min resp time:0.0; max resp time:0.0; stddev resp time:0.0] | |
| , [Server:192.168.99.1:8001; Zone:defaultZone; Total Requests:0; Successive connection failure:0; Total blackout seconds:0; Last connection made:Wed Dec 31 19:00:00 EST 1969; First connection made: Wed Dec 31 19:00:00 EST 1969; Active Connections:0; total failure count in last (1000) msecs:0; average resp time:0.0; 90 percentile resp time:0.0; 95 percentile resp time:0.0; min resp time:0.0; max resp time:0.0; stddev resp time:0.0] | |
| , [Server:192.168.99.1:8002; Zone:defaultZone; Total Requests:0; Successive connection failure:0; Total blackout seconds:0; Last connection made:Wed Dec 31 19:00:00 EST 1969; First connection made: Wed Dec 31 19:00:00 EST 1969; Active Connections:0; total failure count in last (1000) msecs:0; average resp time:0.0; 90 percentile resp time:0.0; 95 percentile resp time:0.0; min resp time:0.0; max resp time:0.0; stddev resp time:0.0] | |
| ]}ServerList:org.springframework.cloud.netflix.ribbon.eureka.DomainExtractingServerList@6e7a0f39 | |
| 2016-01-27 23:41:01.391 INFO 17125 --- [estController-1] com.netflix.http4.ConnectionPoolCleaner : Initializing ConnectionPoolCleaner for NFHttpClient:reservation-service | |
| 2016-01-27 23:41:01.828 INFO 17125 --- [nio-8050-exec-1] o.s.cloud.sleuth.log.Slf4jSpanListener : Stopped span: MilliSpan(begin=1453956061003, end=1453956061818, name=http/reservations/names, traceId=1f06b3ce-a5b9-4689-b1e7-22fb1f3ee10d, parents=[], spanId=1f06b3ce-a5b9-4689-b1e7-22fb1f3ee10d, remote=false, exportable=true, annotations={/http/request/uri=http://localhost:8050/reservations/names, /http/request/endpoint=/reservations/names, /http/request/method=GET, /http/request/headers/host=localhost:8050, /http/request/headers/connection=keep-alive, /http/request/headers/user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36, /http/request/headers/cache-control=no-cache, /http/request/headers/postman-token=0ee95302-3af6-b08a-a784-43490d74925b, /http/request/headers/content-type=application/json, /http/request/headers/accept=*/*, /http/request/headers/accept-encoding=gzip, deflate, sdch, /http/request/headers/accept-language=en-US,en;q=0.8, /http/response/status_code=200, /http/response/headers/x-trace-id=1f06b3ce-a5b9-4689-b1e7-22fb1f3ee10d, /http/response/headers/x-span-id=1f06b3ce-a5b9-4689-b1e7-22fb1f3ee10d, /http/response/headers/x-application-context=reservation-client:8050, /http/response/headers/content-type=application/json;charset=UTF-8, /http/response/headers/transfer-encoding=chunked, /http/response/headers/date=Thu, 28 Jan 2016 04:41:01 GMT}, processId=null, timelineAnnotations=[TimelineAnnotation(time=1453956061004, msg=acquire), TimelineAnnotation(time=1453956061818, msg=release)]) | |
| 2016-01-27 23:41:02.345 INFO 17125 --- [ool-14-thread-1] c.netflix.config.ChainedDynamicProperty : Flipping property: reservation-service.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647 |
Requesting http://localhost:8050/reservations/names, Ribbon forwards the request to one of the three Reservation Service instances registered with Eureka. By default, Ribbon uses a round-robin load-balancing strategy to select an instance from the pool of available Reservation Services.
H2 Server
The original presentation’s Reservation Service used an embedded instance of H2. To scale out the Reservation Service, we need a common database for multiple instances to share. Otherwise, queries would return different results, specific to the particular instance of Reservation Service chosen by the load-balancer. To solve this, the original presentation’s embedded version of H2 has been replaced with the TCP Server client/server version of H2.

Thanks to more Spring magic, the only change we need to make to the original presentation’s code is a few additional properties added to the Reservation Service’s reservation-service.properties file. This changes H2 from the embedded version to the TCP Server version.
| # reservation service app props | |
| message=Spring Cloud Config: Reservation Service\n | |
| # h2 database server | |
| spring.datasource.url=jdbc:h2:tcp://localhost/~/reservationdb | |
| spring.datasource.username=dbuser | |
| spring.datasource.password=dbpass | |
| spring.datasource.driver-class-name=org.h2.Driver | |
| spring.jpa.hibernate.ddl-auto=validate | |
| # spring cloud stream / redis | |
| spring.cloud.stream.bindings.input=reservations | |
| spring.redis.host=192.168.99.100 | |
| spring.redis.port=6379 | |
| # zipkin / spring cloud sleuth | |
| spring.zipkin.host=192.168.99.100 | |
| spring.zipkin.port=9410 |
Reservation Data Seeder
In the original presentation, the Reservation Service created several sample reservation records in its embedded H2 database on startup. Since we now have multiple instances of the Reservation Service running, the sample data creation task has been moved from the Reservation Service to the new Reservation Data Seeder. The Reservation Service only now validates the H2 database schema on startup. The Reservation Data Seeder now updates the schema based on its entities. This also means the seed data will be persisted across restarts of the Reservation Service, unlike in the original configuration.
| # reservation data seeder app props | |
| # h2 database server | |
| spring.datasource.url=jdbc:h2:tcp://localhost/~/reservationdb | |
| spring.datasource.username=dbuser | |
| spring.datasource.password=dbpass | |
| spring.datasource.driver-class-name=org.h2.Driver | |
| spring.h2.console.enabled=true | |
| spring.jpa.hibernate.ddl-auto=update |
Running the Reservation Data Seeder once will create several reservation records into the H2 database. To confirm the H2 Server is running and the initial reservation records were created by the Reservation Data Seeder, point your web browser to the H2 login page at http://192.168.99.1:6889. and log in using the credentials in the reservation-service.properties file.
The H2 Console should contain the RESERVATION table, which holds the reservation sample records.
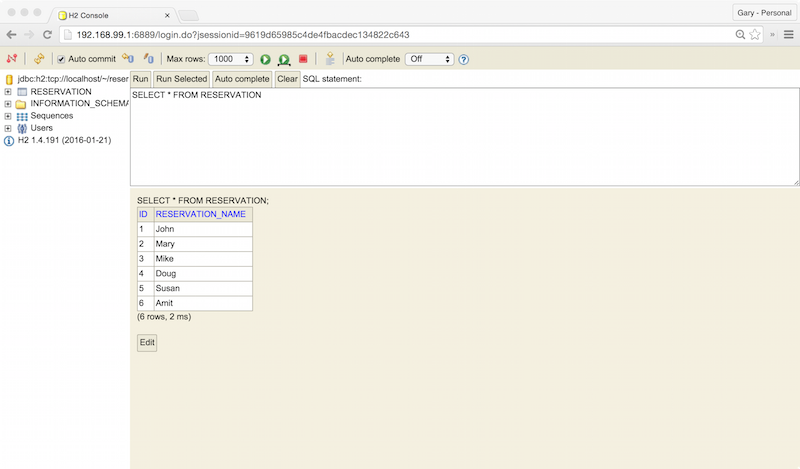
Spring Cloud Sleuth and Twitter’s Zipkin
According to the project description, “Spring Cloud Sleuth implements a distributed tracing solution for Spring Cloud. All your interactions with external systems should be instrumented automatically. You can capture data simply in logs, or by sending it to a remote collector service.” In our case, that remote collector service is Zipkin.
Zipkin describes itself as, “a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems in microservice architectures. It manages both the collection and lookup of this data through a Collector and a Query service.” Zipkin provides critical insights into how microservices perform in a distributed system.

In the presentation, as in this post, the Reservation Client’s main ReservationClientApplication class contains the alwaysSampler bean, which returns a new instance of org.springframework.cloud.sleuth.sampler.AlwaysSampler. As long as Spring Cloud Sleuth is on the classpath and you have added alwaysSampler bean, the Reservation Client will automatically generate trace data.
| @Bean | |
| AlwaysSampler alwaysSampler() { | |
| return new AlwaysSampler(); | |
| } |
Sending a request to the Reservation Client’s service/message endpoint (http://localhost:8050/reservations/service-message,), will generate a trace, composed of spans. in this case, the spans are individual segments of the HTTP request/response lifecycle. Traces are sent by Sleuth to Zipkin, to be collected. According to Spring, if spring-cloud-sleuth-zipkin is available, then the application will generate and collect Zipkin-compatible traces using Brave). By default, it sends them via Apache Thrift to a Zipkin collector service on port 9410.
Zipkin’s web-browser interface, running on port 8080, allows us to view traces and drill down into individual spans.

Zipkin contains fine-grain details about each span within a trace, as shown below.

Correlation IDs
Note the x-trace-id and x-span-id in the request header, shown below. Sleuth injects the trace and span IDs to the SLF4J MDC (Simple Logging Facade for Java – Mapped Diagnostic Context). According to Spring, IDs provides the ability to extract all the logs from a given trace or span in a log aggregator. The use of correlation IDs and log aggregation are essential for monitoring and supporting a microservice architecture.

Hystix and Hystrix Dashboard
The last major technology highlighted in the presentation is Netflix’s Hystrix. According to Netflix, “Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems, services, and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.” Hystrix is essential, it protects applications from cascading dependency failures, an issue common to complex distributed architectures, with multiple dependency chains. According to Netflix, Hystrix uses multiple isolation techniques, such as bulkhead, swimlane, and circuit breaker patterns, to limit the impact of any one dependency on the entire system.
The presentation demonstrates one of the simpler capabilities of Hystrix, fallback. The getReservationNames method is decorated with the @HystrixCommand annotation. This annotation contains the fallbackMethod. According to Netflix, a graceful degradation of a method is provided by adding a fallback method. Hystrix will call to obtain a default value or values, in case the main command fails. In the presentation’s example, the Reservation Service, a direct dependency of the Reservation Client, has failed. The Reservation Service failure causes the failure of the Reservation Client.
In the presentation’s example, the Reservation Service, a direct dependency of the Reservation Client, has failed. The Reservation Service failure causes the failure of the Reservation Client’s getReservationNames method to return a collection of reservation names. Hystrix redirects the application to the getReservationNameFallback method. Instead of returning a collection of reservation names, the getReservationNameFallback returns an empty collection, as opposed to an error message to the client.
| public Collection<String> getReservationNameFallback() { | |
| return emptyList(); | |
| } | |
| @HystrixCommand(fallbackMethod = "getReservationNameFallback", commandProperties = { | |
| @HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "3000") | |
| }) | |
| @RequestMapping(path = "/names", method = RequestMethod.GET) | |
| public Collection<String> getReservationNames() { | |
| ParameterizedTypeReference<Resources<Reservation>> ptr = | |
| new ParameterizedTypeReference<Resources<Reservation>>() { | |
| }; | |
| return this.restTemplate.exchange( | |
| "http://reservation-service/reservations", GET, null, ptr) | |
| .getBody() | |
| .getContent() | |
| .stream() | |
| .map(Reservation::getReservationName) | |
| .collect(toList()); | |
| } |
A more relevant example involves Netflix movie recommendation service. In the event a failure of the recommendation service’s method to return a collection of personalized list of movie recommendations to a customer, Hystrix fallbacks to a method that returns a generic list of the most popular movies to the customer. Netflix has determined that, in the event of a failure of their recommendation service, falling back to a generic list of movies is better than returning no movies at all.
The Hystrix Dashboard is a tool, available with Hystrix, to visualize the current state of Hystrix instrumented methods. Although visually simplistic, the dashboard effectively presents the health of calls to external systems, which are wrapped in a HystrixCommand or HystrixObservableCommand.

The Hystrix dashboard is a visual representation of the Hystrix Stream. This stream is a live feed of data sent by the Hystrix instrumented application, in this case, the Reservation Client. For a single Hystrix application, such as the Reservation Client, the feed requested from the application’s hystrix.stream endpoint is http://localhost:8050/hystrix.stream. The dashboard consumes the stream resource’s response and visualizes it in the browser using JavaScript, jQuery, and d3.
In the post, as in the presentation, hitting the Reservation Client with a volume of requests, we observe normal activity in Hystrix Dashboard. All three instances of the Reservation Service are running and returning the collection of reservations from H2, to the Reservation Client.

If all three instances of the Reservation Service fail or the maximum latency is exceeded, the Reservation Client falls back to returning an empty collection in the response body. In the example below, 15 requests, representing 100% of the current traffic, to the getReservationNames method failed and subsequently fell back to return an empty collection. Hystrix succeeded in helping the application gracefully fall back to an alternate response.

Conclusion
It’s easy to see how Spring Cloud and Netflix’s technologies are easily combined to create a performant, horizontally scalable, reliable system. With the addition of a few missing components, such metrics monitoring and log aggregation, this example could easily be scaled up to support a production-grade microservices-based, enterprise software platform.
Build and Deploy a Java-Spring-MongoDB Application using Docker
Posted by Gary A. Stafford in Bash Scripting, Build Automation, Continuous Delivery, DevOps, Enterprise Software Development, Software Development on September 7, 2015
Build a multi-container, MongoDB-backed, Java Spring web application, and deploy to a test environment using Docker.
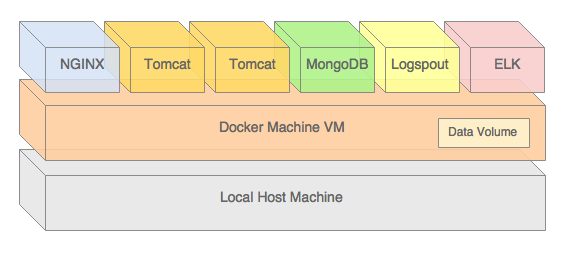
Introduction
Application Architecture
Spring Music Environment
Building the Environment
Spring Music Application Links
Helpful Links
Introduction
In this post, we will demonstrate how to build, deploy, and host a multi-tier Java application using Docker. For the demonstration, we will use a sample Java Spring application, available on GitHub from Cloud Foundry. Cloud Foundry’s Spring Music sample record album collection application was originally designed to demonstrate the use of database services on Cloud Foundry and Spring Framework. Instead of Cloud Foundry, we will host the Spring Music application using Docker with VirtualBox and optionally, AWS.
All files required to build this post’s demonstration are located in the master branch of this GitHub repository. Instructions to clone the repository are below. The Java Spring Music application’s source code, used in this post’s demonstration, is located in the master branch of this GitHub repository.

A few changes were necessary to the original Spring Music application to make it work for the this demonstration. At a high-level, the changes included:
- Modify MongoDB configuration class to work with non-local MongoDB instances
- Add Gradle
warNoStatictask to build WAR file without the static assets, which will be host separately in NGINX - Create new Gradle task,
zipStatic, to ZIP up the application’s static assets for deployment to NGINX - Add versioning scheme for build artifacts
- Add
context.xmlfile andMANIFEST.MFfile to the WAR file - Add log4j
syslogappender to send log entries to Logstash - Update versions of several dependencies, including Gradle to 2.6
Application Architecture
The Java Spring Music application stack contains the following technologies:
The Spring Music web application’s static content will be hosted by NGINX for increased performance. The application’s WAR file will be hosted by Apache Tomcat. Requests for non-static content will be proxied through a single instance of NGINX on the front-end, to one of two load-balanced Tomcat instances on the back-end. NGINX will also be configured to allow for browser caching of the static content, to further increase application performance. Reverse proxying and caching are configured thought NGINX’s default.conf file’s server configuration section:
server {
listen 80;
server_name localhost;
location ~* \/assets\/(css|images|js|template)\/* {
root /usr/share/nginx/;
expires max;
add_header Pragma public;
add_header Cache-Control "public, must-revalidate, proxy-revalidate";
add_header Vary Accept-Encoding;
access_log off;
}
The two Tomcat instances will be configured on NGINX, in a load-balancing pool, using NGINX’s default round-robin load-balancing algorithm. This is configured through NGINX’s default.conf file’s upstream configuration section:
upstream backend {
server app01:8080;
server app02:8080;
}
The Spring Music application can be run with MySQL, Postgres, Oracle, MongoDB, Redis, or H2, an in-memory Java SQL database. Given the choice of both SQL and NoSQL databases available for use with the Spring Music application, we will select MongoDB.
The Spring Music application, hosted by Tomcat, will store and modify record album data in a single instance of MongoDB. MongoDB will be populated with a collection of album data when the Spring Music application first creates the MongoDB database instance.
Lastly, the ELK Stack with Logspout, will aggregate both Docker and Java Log4j log entries, providing debugging and analytics to our demonstration. I’ve used the same method for Docker and Java Log4j log entries, as detailed in this previous post.

Spring Music Environment
To build, deploy, and host the Java Spring Music application, we will use the following technologies:
- Gradle
- GitHub
- Travis CI
- git
- Oracle VirtualBox
- Docker
- Docker Compose
- Docker Machine
- Docker Hub
- optional: Amazon Web Services (AWS)
All files necessary to build this project are stored in the garystafford/spring-music-docker repository on GitHub. The Spring Music source code and build artifacts are stored in a seperate garystafford/spring-music repository, also on GitHub.
Build artifacts are automatically built by Travis CI when changes are checked into the garystafford/spring-music repository on GitHub. Travis CI then overwrites the build artifacts back to a build artifact branch of that same project. The build artifact branch acts as a pseudo binary repository for the project. The .travis.yaml file, gradle.build file, and deploy.sh script handles these functions.
.travis.yaml file:
language: java jdk: oraclejdk7 before_install: - chmod +x gradlew before_deploy: - chmod ugo+x deploy.sh script: - bash ./gradlew clean warNoStatic warCopy zipGetVersion zipStatic - bash ./deploy.sh env: global: - GH_REF: github.com/garystafford/spring-music.git - secure: <secure hash here>
gradle.build file snippet:
// new Gradle build tasks
task warNoStatic(type: War) {
// omit the version from the war file name
version = ''
exclude '**/assets/**'
manifest {
attributes
'Manifest-Version': '1.0',
'Created-By': currentJvm,
'Gradle-Version': GradleVersion.current().getVersion(),
'Implementation-Title': archivesBaseName + '.war',
'Implementation-Version': artifact_version,
'Implementation-Vendor': 'Gary A. Stafford'
}
}
task warCopy(type: Copy) {
from 'build/libs'
into 'build/distributions'
include '**/*.war'
}
task zipGetVersion (type: Task) {
ext.versionfile =
new File("${projectDir}/src/main/webapp/assets/buildinfo.properties")
versionfile.text = 'build.version=' + artifact_version
}
task zipStatic(type: Zip) {
from 'src/main/webapp/assets'
appendix = 'static'
version = ''
}
deploy.sh file:
#!/bin/bash
# reference: https://gist.github.com/domenic/ec8b0fc8ab45f39403dd
set -e # exit with nonzero exit code if anything fails
# go to the distributions directory and create a *new* Git repo
cd build/distributions && git init
# inside this git repo we'll pretend to be a new user
git config user.name "travis-ci"
git config user.email "auto-deploy@travis-ci.com"
# The first and only commit to this new Git repo contains all the
# files present with the commit message.
git add .
git commit -m "Deploy Travis CI build #${TRAVIS_BUILD_NUMBER} artifacts to GitHub"
# Force push from the current repo's master branch to the remote
# repo's build-artifacts branch. (All previous history on the gh-pages branch
# will be lost, since we are overwriting it.) We redirect any output to
# /dev/null to hide any sensitive credential data that might otherwise be exposed. Environment variables pre-configured on Travis CI.
git push --force --quiet "https://${GH_TOKEN}@${GH_REF}" master:build-artifacts > /dev/null 2>&1
Base Docker images, such as NGINX, Tomcat, and MongoDB, used to build the project’s images and subsequently the containers, are all pulled from Docker Hub.
This NGINX and Tomcat Dockerfiles pull the latest build artifacts down to build the project-specific versions of the NGINX and Tomcat Docker images used for this project. For example, the NGINX Dockerfile looks like:
# NGINX image with build artifact
FROM nginx:latest
MAINTAINER Gary A. Stafford <garystafford@rochester.rr.com>
ENV REFRESHED_AT 2015-09-20
ENV GITHUB_REPO https://github.com/garystafford/spring-music/raw/build-artifacts
ENV STATIC_FILE spring-music-static.zip
RUN apt-get update -y &&
apt-get install wget unzip nano -y &&
wget -O /tmp/${STATIC_FILE} ${GITHUB_REPO}/${STATIC_FILE} &&
unzip /tmp/${STATIC_FILE} -d /usr/share/nginx/assets/
COPY default.conf /etc/nginx/conf.d/default.conf
Docker Machine builds a single VirtualBox VM. After building the VM, Docker Compose then builds and deploys (1) NGINX container, (2) load-balanced Tomcat containers, (1) MongoDB container, (1) ELK container, and (1) Logspout container, onto the VM. Docker Machine’s VirtualBox driver provides a basic solution that can be run locally for testing and development. The docker-compose.yml for the project is as follows:
proxy: build: nginx/ ports: "80:80" links: - app01 - app02 hostname: "proxy" app01: build: tomcat/ expose: "8080" ports: "8180:8080" links: - nosqldb - elk hostname: "app01" app02: build: tomcat/ expose: "8080" ports: "8280:8080" links: - nosqldb - elk hostname: "app01" nosqldb: build: mongo/ hostname: "nosqldb" volumes: "/opt/mongodb:/data/db" elk: build: elk/ ports: - "8081:80" - "8082:9200" expose: "5000/upd" logspout: build: logspout/ volumes: "/var/run/docker.sock:/tmp/docker.sock" links: elk ports: "8083:80" environment: ROUTE_URIS=logstash://elk:5000
Building the Environment
Before continuing, ensure you have nothing running on ports 80, 8080, 8081, 8082, and 8083. Also, make sure VirtualBox, Docker, Docker Compose, Docker Machine, VirtualBox, cURL, and git are all pre-installed and running.
docker --version && docker-compose --version && docker-machine --version && echo "VirtualBox $(vboxmanage --version)" && curl --version && git --version
All of the below commands may be executed with the following single command (sh ./build_project.sh). This is useful for working with Jenkins CI, ThoughtWorks go, or similar CI tools. However, I suggest building the project step-by-step, as shown below, to better understand the process.
# clone project
git clone -b master
--single-branch https://github.com/garystafford/spring-music-docker.git &&
cd spring-music-docker
# build VM
docker-machine create --driver virtualbox springmusic --debug
# create directory to store mongo data on host
docker-machine ssh springmusic mkdir /opt/mongodb
# set new environment
docker-machine env springmusic &&
eval "$(docker-machine env springmusic)"
# build images and containers
docker-compose -f docker-compose.yml -p music up -d
# wait for container apps to start
sleep 15
# run quick test of project
for i in {1..10}
do
curl -I --url $(docker-machine ip springmusic)
done
By simply changing the driver to AWS EC2 and providing your AWS credentials, the same environment can be built on AWS within a single EC2 instance. The ‘springmusic’ environment has been fully tested both locally with VirtualBox, as well as on AWS.
Results
Resulting Docker images and containers:
gstafford@gstafford-X555LA:$ docker images REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE music_proxy latest 46af4c1ffee0 52 seconds ago 144.5 MB music_logspout latest fe64597ab0c4 About a minute ago 24.36 MB music_app02 latest d935211139f6 2 minutes ago 370.1 MB music_app01 latest d935211139f6 2 minutes ago 370.1 MB music_elk latest b03731595114 2 minutes ago 1.05 GB gliderlabs/logspout master 40a52d6ca462 14 hours ago 14.75 MB willdurand/elk latest 04cd7334eb5d 9 days ago 1.05 GB tomcat latest 6fe1972e6b08 10 days ago 347.7 MB mongo latest 5c9464760d54 10 days ago 260.8 MB nginx latest cd3cf76a61ee 10 days ago 132.9 MB gstafford@gstafford-X555LA:$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES facb6eddfb96 music_proxy "nginx -g 'daemon off" 46 seconds ago Up 46 seconds 0.0.0.0:80->80/tcp, 443/tcp music_proxy_1 abf9bb0821e8 music_app01 "catalina.sh run" About a minute ago Up About a minute 0.0.0.0:8180->8080/tcp music_app01_1 e4c43ed84bed music_logspout "/bin/logspout" About a minute ago Up About a minute 8000/tcp, 0.0.0.0:8083->80/tcp music_logspout_1 eca9a3cec52f music_app02 "catalina.sh run" 2 minutes ago Up 2 minutes 0.0.0.0:8280->8080/tcp music_app02_1 b7a7fd54575f mongo:latest "/entrypoint.sh mongo" 2 minutes ago Up 2 minutes 27017/tcp music_nosqldb_1 cbfe43800f3e music_elk "/usr/bin/supervisord" 2 minutes ago Up 2 minutes 5000/0, 0.0.0.0:8081->80/tcp, 0.0.0.0:8082->9200/tcp music_elk_1
Partial result of the curl test, calling NGINX. Note the two different upstream addresses for Tomcat. Also, note the sharp decrease in request times, due to caching.
HTTP/1.1 200 OK Server: nginx/1.9.4 Date: Mon, 07 Sep 2015 17:56:11 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 2090 Connection: keep-alive Accept-Ranges: bytes ETag: W/"2090-1441648256000" Last-Modified: Mon, 07 Sep 2015 17:50:56 GMT Content-Language: en Request-Time: 0.521 Upstream-Address: 172.17.0.121:8080 Upstream-Response-Time: 1441648570.774 HTTP/1.1 200 OK Server: nginx/1.9.4 Date: Mon, 07 Sep 2015 17:56:11 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 2090 Connection: keep-alive Accept-Ranges: bytes ETag: W/"2090-1441648256000" Last-Modified: Mon, 07 Sep 2015 17:50:56 GMT Content-Language: en Request-Time: 0.326 Upstream-Address: 172.17.0.123:8080 Upstream-Response-Time: 1441648571.506 HTTP/1.1 200 OK Server: nginx/1.9.4 Date: Mon, 07 Sep 2015 17:56:12 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 2090 Connection: keep-alive Accept-Ranges: bytes ETag: W/"2090-1441648256000" Last-Modified: Mon, 07 Sep 2015 17:50:56 GMT Content-Language: en Request-Time: 0.006 Upstream-Address: 172.17.0.121:8080 Upstream-Response-Time: 1441648572.050 HTTP/1.1 200 OK Server: nginx/1.9.4 Date: Mon, 07 Sep 2015 17:56:12 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 2090 Connection: keep-alive Accept-Ranges: bytes ETag: W/"2090-1441648256000" Last-Modified: Mon, 07 Sep 2015 17:50:56 GMT Content-Language: en Request-Time: 0.006 Upstream-Address: 172.17.0.123:8080 Upstream-Response-Time: 1441648572.266
Spring Music Application Links
Assuming springmusic VM is running at 192.168.99.100:
- Spring Music: 192.168.99.100
- NGINX: 192.168.99.100/nginx_status
- Tomcat Node 1*: 192.168.99.100:8180/manager
- Tomcat Node 2*: 192.168.99.100:8280/manager
- Kibana: 192.168.99.100:8081
- Elasticsearch: 192.168.99.100:8082
- Elasticsearch: 192.168.99.100:8082/_status?pretty
- Logspout: 192.168.99.100:8083/logs
* The Tomcat user name is admin and the password is t0mcat53rv3r.
Helpful Links
Gary Stafford
AWS Area Principal Solutions Architect | 10x AWS Certified Pro | DevOps | Data/ML | Serverless | Polyglot Developer | Former ThoughtWorks and Accenture
