Archive for category Software Development
Streaming Data on AWS: Amazon Kinesis Data Streams or Amazon MSK?
Posted by Gary A. Stafford in Analytics, AWS, Big Data, Serverless on April 23, 2023
Given similar functionality, what differences make one AWS-managed streaming service a better choice over the other?

Data streaming has emerged as a powerful tool in the last few years thanks to its ability to quickly and efficiently process large volumes of data, provide real-time insights, and scale and adapt to meet changing needs. As IoT, social media, and mobile devices continue to generate vast amounts of data, it has become imperative to have platforms that can handle the real-time ingestion, processing, and analysis of this data.
Key Differentiators
Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK) are two managed streaming services offered by AWS. While both platforms offer similar features, choosing the right service largely depends on your specific use cases and business requirements.
Amazon Kinesis Data Streams
- Simplicity: Kinesis Data Streams is generally considered a less complicated service than Amazon MSK, which requires you to manage more of the underlying infrastructure. This can make setting up and managing your streaming data pipeline easier, especially if you have limited experience with Apache Kafka. Amazon MSK Serverless, which went GA in April 2022, is a cluster type for Amazon MSK that allows you to run Apache Kafka without managing and scaling cluster capacity. Unlike Amazon MSK provisioned, Amazon MSK Serverless greatly reduces the effort required to use Amazon MSK, making ‘Simplicity’ less of a Kinesis differentiator.
- Integration with AWS services: Kinesis Data Streams integrates well with other AWS services, such as AWS Lambda, Amazon S3, and Amazon OpenSearch. This can make building end-to-end data processing pipelines easier using these services.
- Low latency: Kinesis Data Streams is designed to deliver low-latency processing of streaming data, which can be important for applications that require near real-time processing.
- Predictable pricing: Kinesis Data Streams is generally considered to have a more predictable pricing model than Amazon MSK, based on instance sizes and hourly usage. With Kinesis Data Streams, you pay for the data you process, making estimating and managing fees easier (additional fees may apply).

Amazon MSK
- Compatibility with Apache Kafka: Amazon MSK may be a better choice if you have an existing Apache Kafka deployment or are already familiar with Kafka. Amazon MSK is a fully managed version of Apache Kafka, which you can use with existing Kafka applications and tools.
- Customization: With Amazon MSK, you have more control over the underlying cluster infrastructure, configuration, deployment, and version of Kafka, which means you can customize the cluster to meet your needs. This can be important if you have specialized requirements or want to optimize performance (e.g., high-volume financial trading, real-time gaming).
- Larger ecosystem: Apache Kafka has a large ecosystem of tools and integrations compared to Kinesis Data Streams. This can provide flexibility and choice when building and managing your streaming data pipeline. Some common tools include MirrorMaker, Kafka Connect, LinkedIn’s Cruise Control, kcat (fka kafkacat), Lenses, Confluent Schema Registry, and Appicurio Registry.
- Preference for Open Source: You may prefer the flexibility, transparency, pace of innovation, and interoperability of employing open source software (OSS) over proprietary software and services for your streaming solution.

Ultimately, the choice between Amazon Kinesis Data Streams and Amazon MSK will depend on your specific needs and priorities. Kinesis Data Streams might be better if you prioritize simplicity, integration with other AWS services, and low latency. If you have an existing Kafka deployment, require more customization, or need access to a larger ecosystem of tools and integrations, Amazon MSK might be a better fit. In my opinion, the newer Amazon MSK Serverless option lessens several traditional differentiators between the two services.
Scaling Capabilities
Amazon Kinesis Data Streams and Amazon MSK are designed to be scalable streaming services that can handle large volumes of data. However, there are some differences in their scaling capabilities.
Amazon Kinesis Data Streams
- Scalability: Kinesis Data Streams has two capacity modes, on-demand and provisioned. With the on-demand mode, Kinesis Data Streams automatically manages the shards to provide the necessary throughput based on the amount of data you process. This means the service can automatically adjust the number of shards based on the incoming data volume, allowing you to handle increased traffic without manually adjusting the infrastructure.
- Limitations: Per the documentation, there is no upper quota on the number of streams with the provisioned mode you can have in an account. A shard can ingest up to 1 MB of data per second (including partition keys) or 1,000 records per second for writes. The maximum size of the data payload of a record before base64-encoding is up to 1 MB. GetRecords can retrieve up to 10 MB of data per call from a single shard and up to 10,000 records per call. Each call to GetRecords is counted as one read transaction. Each shard can support up to five read transactions per second. Each read transaction can provide up to 10,000 records with an upper quota of 10 MB per transaction. Each shard can support a maximum total data read rate of 2 MB per second via GetRecords. If a call to GetRecords returns 10 MB, subsequent calls made within the next 5 seconds throw an exception.
- Cost: Kinesis Data Streams has two capacity modes — on-demand and provisioned — with different pricing models. With on-demand capacity mode, you pay per GB of data written and read from your data streams. You do not need to specify how much read and write throughput you expect your application to perform. With provisioned capacity mode, you select the number of shards necessary for your application based on its write and read request rate. There are additional fees
PUTPayload Units, enhanced fan-out, extended data retention, and retrieval of long-term retention data.
Amazon MSK
- Scalability: Amazon MSK is designed to be highly scalable and can handle millions of messages per second. With Amazon MSK provisioned, you can scale your Kafka cluster by adding or removing instances (brokers) and storage as needed. Amazon MSK can automatically rebalance partitions across instances. Alternately, Amazon MSK Serverless automatically provisions and scales capacity while managing the partitions in your topic, so you can stream data without thinking about right-sizing or scaling clusters.
- Flexibility: With Amazon MSK, you have more control over the underlying infrastructure, which means you can customize the deployment to meet your needs. This can be important if you have specialized requirements or want to optimize performance.
- Amazon MSK also offers multiple authentication methods. You can use IAM to authenticate clients and to allow or deny Apache Kafka actions. Alternatively, with Amazon MSK provisioned, you can use TLS or SASL/SCRAM to authenticate clients and Apache Kafka ACLs to allow or deny actions.
- Cost: Scaling up or down with Amazon MSK can impact the cost based on instance sizes and hourly usage. Therefore, adding more instances can increase the overall cost of the service. Pricing models for Amazon MSK and Amazon MSK Serverless vary.
Amazon Kinesis Data Streams and Amazon MSK are highly scalable services. Kinesis Data Streams can scale automatically based on the amount of data you process. At the same time, Amazon MSK allows you to scale your Kafka cluster by adding or removing instances and adding storage as needed. However, adding more shards with Kinesis can lead to a more manual process that can take some time to propagate and impact cost, while scaling up or down with Amazon MSK is based on instance sizes and hourly usage. Ultimately, the choice between the two will depend on your specific use case and requirements.
Throughput
Throughput can be measured in the maximum MB/s of data and the maximum number of records per second. The maximum throughput of both Amazon Kinesis Data Streams and Amazon MSK are not hard limits. Depending on the service, you can exceed these limits by adding more resources, including shards or brokers. Total maximum system throughput is affected by the maximum throughput of both upstream and downstream producing and consuming components.
Amazon Kinesis Data Streams
The maximum throughput of Kinesis Data Streams depends on the number of shards and the size of the data being processed. Each shard in a Kinesis stream can handle up to 1 MB/s of data input and up to 2 MB/s of data output, or up to 1,000 records per second for writes and up to 10,000 records per second for reads. When a consumer uses enhanced fan-out, it gets its own 2 MB/s allotment of read throughput, allowing multiple consumers to read data from the same stream in parallel without contending for read throughput with other consumers.
The maximum throughput of a Kinesis stream is determined by the number of shards you have multiplied by the maximum throughput per shard. For example, if you have a stream with 10 shards, the maximum throughput of the stream would be 10 MB/s for data input and 20 MB/s for data output, or up to 10,000 records per second for writes and up to 100,000 records per second for reads.
The maximum throughput is not a hard limit, and you can exceed these limits by adding more shards to your stream. However, adding more shards can impact the cost of the service, and you should consider the optimal shard count for your use case to ensure efficient and cost-effective processing of your data.
Amazon MSK
As discussed in the Amazon MSK best practices documentation, the maximum throughput of Amazon MSK depends on the number of brokers and the instance type of those brokers. Amazon MSK allows you to scale the number of instances in a Kafka cluster up or down based on your needs.
The maximum throughput of an Amazon MSK cluster depends on the number of brokers and the performance characteristics of the instance types you are using. Each broker in an Amazon MSK cluster can handle tens of thousands of messages per second, depending on the instance type and configuration. The actual throughput you can achieve will depend on your specific use case and the message size. The AWS blog post, Best practices for right-sizing your Apache Kafka clusters to optimize performance and cost, is an excellent reference.
The maximum throughput is not a hard limit, and you can exceed these limits by adding more brokers or upgrading to more powerful instances. However, adding more instances or upgrading to more powerful instances can impact the service’s cost. Therefore, consider your use case’s optimal instance count and type to ensure efficient and cost-effective data processing.
Writing Messages
Compatibility with multiple producers and consumers is essential when choosing a streaming technology. There are multiple ways to write messages to Amazon Kinesis Data Streams and Amazon MSK.
Amazon Kinesis Data Streams
- AWS SDK: Use the AWS SDK for your preferred programming language.
- Kinesis Producer Library (KPL): KPL is a high-performance library that allows you to write data to Kinesis Data Streams at a high rate. KPL handles all heavy lifting, including batching, retrying failed records, and load balancing across shards.
- Amazon Kinesis Data Firehose: Kinesis Data Firehose is a fully managed service that can ingest and transform streaming data in real-time. It can be used to write data to Kinesis Data Streams, as well as to other AWS services such as S3, Redshift, and Elasticsearch.
- Amazon Kinesis Data Analytics: Kinesis Data Analytics is a fully managed service that allows you to process and analyze streaming data in real-time. It can read data from Kinesis Data Streams, perform real-time analytics and transformations, and write the results to another Kinesis stream or an external data store.
- Kinesis Agent: Kinesis Agent is a standalone Java application that collects and sends data to Kinesis Data Streams. It can monitor log files or other data sources and automatically send data to Kinesis Data Streams as it is generated.
- Third-party libraries and tools: There are many third-party libraries and tools available for writing data to Kinesis Data Streams, including Apache Kafka Connect, Apache Storm, and Fluentd. These tools can integrate Kinesis Data Streams with existing data processing pipelines or build custom streaming applications.

Amazon MSK
- Kafka command line tools: The Kafka command line tools (e.g.,
kafka-console-producer.sh) can be used to write messages to a Kafka topic in an Amazon MSK cluster. These tools are part of the Kafka distribution and are pre-installed on the Amazon MSK broker nodes. - Kafka client libraries: You can use Kafka client libraries in your preferred programming language (e.g., Java, Python, C#) to write messages to an Amazon MSK cluster. These libraries provide a more flexible and customizable way to produce messages to Kafka topics.
- AWS SDKs: You can use AWS SDKs (e.g., AWS SDK for Java, AWS SDK for Python) to interact with Amazon MSK and write messages to Kafka topics. These SDKs provide a higher-level abstraction over the Kafka client libraries, making integrating Amazon MSK into your AWS infrastructure easier.
- Third-party libraries and tools: There are many third-party tools and frameworks, including Apache NiFi, Apache Camel, and Apache Beam. They provide Kafka connectors and producers, which can be used to write messages to Kafka topics in Amazon MSK. These tools can simplify the process of writing messages and provide additional features such as data transformation and routing.
Schema Registry
You can use AWS Glue Schema Registry with Amazon Kinesis Data Streams and Amazon MSK. AWS Glue Schema Registry is a fully managed service that provides a central schema repository for organizing, validating, and tracking the evolution of your data schemas. It enables you to store, manage, and discover schemas for your data in a single, centralized location.
With AWS Glue Schema Registry, you can define and register schemas for your data in the registry. You can then use these schemas to validate the data being ingested into your streaming applications, ensuring that the data conforms to the expected structure and format.
Both Kinesis Data Streams and Amazon MSK support the use of AWS Glue Schema Registry through the use of Apache Avro schemas. Avro is a compact, fast, binary data format that can improve the performance of your streaming applications. You can configure your streaming applications to use the registry to validate incoming data, ensuring that it conforms to the schema before processing.
Using AWS Glue Schema Registry can help ensure the consistency and quality of your data across your streaming applications and provide a centralized location for managing and tracking schema changes. Amazon MSK is also compatible with popular alternative schema registries, such as Confluent Schema Registry and RedHat’s open-source Apicurio Registry.

Stream Processing
According to TechTarget, Stream processing is a data management technique that involves ingesting a continuous data stream to quickly analyze, filter, transform, or enhance the data in real-time. Several leading stream processing tools are available, compatible with Amazon Kinesis Data Streams and Amazon MSK. Each tool with its own strengths and use cases. Some of the more popular tools include:
- Apache Flink: Apache Flink is a distributed stream processing framework that provides fast, scalable, and fault-tolerant data processing for real-time and batch data streams. It supports a variety of data sources and sinks and provides a powerful stream processing API and SQL interface. In addition, Amazon offers its managed version of Apache Flink, Amazon Kinesis Data Analytics (KDA), which is compatible with both Amazon Kinesis Data Streams and Amazon MSK.
- Apache Spark Structured Streaming: Apache Spark Structured Streaming is a stream processing framework that allows developers to build real-time stream processing applications using the familiar Spark API. It provides high-level APIs for processing data streams and supports integration with various data sources and sinks. Apache Spark is compatible with both Amazon Kinesis Data Streams and Amazon MSK. Spark Streaming is available as a managed service on AWS via AWS Glue Studio and Amazon EMR.
- Apache NiFi: Apache NiFi is an open-source data integration and processing tool that provides a web-based UI for building data pipelines. It supports batch and stream processing and offers a variety of processors for data ingestion, transformation, and delivery. Apache NiFi is compatible with both Amazon Kinesis Data Streams and Amazon MSK.
- Amazon Kinesis Data Firehose (KDA): Kinesis Data Firehose is a fully managed service that can ingest and transform streaming data in real time. It can be used to write data to Kinesis Data Streams, as well as to other AWS services such as S3, Redshift, and Elasticsearch. Kinesis Data Firehose is compatible with Amazon Kinesis Data Streams and Amazon MSK.
- Apache Kafka Streams (aka KStream): Apache Kafka Streams is a lightweight stream processing library that allows developers to build scalable and fault-tolerant real-time applications and microservices. KStreams integrates seamlessly with Amazon MSK and provides a high-level DSL for stream processing.
- ksqlDB: ksqlDB is a database for building stream processing applications on top of Apache Kafka. It is distributed, scalable, reliable, and real-time. ksqlDB combines the power of real-time stream processing with the approachable feel of a relational database through a familiar, lightweight SQL syntax. ksqlDB is compatible with Amazon MSK.
Several stream-processing tools are detailed in my recent two-part blog post, Exploring Popular Open-source Stream Processing Technologies.
Conclusion
Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK) are managed streaming services. While they offer similar functionality, some differences might make one a better choice, depending on your use cases and experience. Ensure you understand your streaming requirements and each service’s capabilities before making a final architectural decision.
🔔 To keep up with future content, follow Gary Stafford on LinkedIn.
This blog represents my viewpoints and not those of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners.
Unlocking the Potential of Generative AI for Synthetic Data Generation
Posted by Gary A. Stafford in AI/ML, Cloud, Enterprise Software Development, Machine Learning, Python, Software Development, Technology Consulting on April 18, 2023
Explore the capabilities and applications of generative AI to create realistic synthetic data for software development, analytics, and machine learning

Introduction
Generative AI refers to a class of artificial intelligence algorithms capable of generating new data similar to a given dataset. These algorithms learn the underlying patterns and relationships in the data and use this knowledge to create new data consistent with the original dataset. Generative AI is a rapidly evolving field that has the potential to revolutionize the way we generate and use data.
Generative AI can generate synthetic data based on patterns and relationships learned from actual data. This ability to generate synthetic data has numerous applications, from creating realistic virtual environments for training and simulation to generating new data for machine learning models. In this article, we will explore the capabilities of generative AI and its potential to generate synthetic data, both directly and indirectly, for software development, data analytics, and machine learning.
Common Forms of Synthetic Data
According to AltexSoft, in their article Synthetic Data for Machine Learning: its Nature, Types, and Ways of Generation, common forms of synthetic data include:
- Tabular data: This type of synthetic data is often used to generate datasets that resemble real-world data in terms of structure and statistical properties.
- Time series data: This type of synthetic data generates datasets that resemble real-world time series data. It is commonly used when real-world time series data is unavailable or too expensive.
- Image and video data: This synthetic data is used to generate realistic images and videos for training machine learning models or simulations.
- Text data: This synthetic data generates realistic text for natural language processing tasks or for generating training data for machine learning models.
- Sound data: This synthetic data generates realistic sound for training machine learning models or simulations.
Synthetic Tabular Data Types
Synthetic tabular data refers to artificially generated datasets that resemble real-world tabular data in terms of structure and statistical properties. Tabular data is organized into rows and columns, like tables or spreadsheets. Some specific types of synthetic tabular data include:
- Financial data: Synthetic datasets that resemble real-world financial data such as bank transactions, stock prices, or credit card information.
- Customer data: Synthetic datasets that resemble real-world customer data, such as purchase history, demographic information, or customer behavior.
- Medical data: Synthetic datasets that resemble real-world medical data, such as patient records, medical test results, or treatment history.
- Sensor data: Synthetic datasets that resemble real-world sensor data such as temperature readings, humidity levels, or air quality measurements.
- Sales data: Synthetic datasets that resemble real-world sales data, such as sales transactions, product information, or customer behavior.
- Inventory data: Synthetic datasets that resemble real-world inventory data, such as stock levels, product information, or supplier information.
- Marketing data: Synthetic datasets that resemble real-world marketing data, such as campaign performance, customer behavior, or market trends.
- Human resources data: Synthetic datasets that resemble real-world human resources data, such as employee records, performance evaluations, or salary information.
Challenges with Creating Synthetic Data
According to sources including Towards Data Science, enov8, and J.P. Morgan, there are several challenges in creating synthetic data, including:
- Technical difficulty: Properly modeling complex real-world behaviors such as synthetic data is challenging, given available technologies.
- Biased behavior: The flexible nature of synthetic data makes it prone to potentially biased results.
- Privacy concerns: Care must be taken to ensure synthetic data does not reveal sensitive information.
- Quality of the data model: If the quality of the data model is not high, wrong conclusions can be reached.
- Time and effort: Synthetic data generation requires time and effort.
Difficult Patterns and Behaviors to Model
Many patterns and behaviors can be challenging to model in synthetic data, for example:
- Rare events: If certain events rarely occur in the real world, generating synthetic data that accurately reflects their distribution can be difficult.
- Complex relationships: Synthetic data generators may struggle to capture complex relationships between variables, such as non-linear interactions, feedback loops, or conditional dependencies.
- Contextual variability: Contextual factors, such as time, location, or individual differences, can have a significant impact on the distribution of data. Modeling this variability accurately can be challenging.
- Outliers and anomalies: Synthetic data generators may be unable to generate outliers or anomalies that are realistic and representative of the real world.
- Dynamic data: If the data is dynamic and changes over time, it can be challenging to generate synthetic data that captures these changes accurately.
- Unobserved variables: Sometimes, variables may be necessary for understanding the data distribution but are not directly observable. These variables can be challenging to model in synthetic data.
- Data bias: If the real-world data is biased in some way, such as over-representation of certain groups or under-representation of others, it can be challenging to generate synthetic data that is unbiased and representative of the population.
- Time-dependent patterns: If the data exhibits time-dependent patterns, such as seasonality or trends, it can be challenging to generate synthetic data that accurately reflects them.
- Spatial patterns: If the data has a spatial component, such as location data or images, it can be challenging to generate synthetic data that captures the spatial patterns realistically.
- Data sparsity: If the data is sparse or incomplete, it can be difficult to generate synthetic data that accurately reflects the distribution of the entire dataset.
- Human behavior: If the data involves human behavior, such as in social science or behavioral economics, it can be challenging to model the complex and nuanced behaviors of individuals and groups.
- Sensitive or confidential information: In some cases, the data may contain sensitive or confidential information that cannot be shared, making it challenging to generate synthetic data that preserves privacy while accurately reflecting the underlying distribution.
Overall, many patterns can be challenging to model accurately in synthetic data. It often requires careful consideration of the specific data characteristics and the synthetic data generation techniques’ limitations.
Easily Modeled Patterns and Behaviors
There are many simple and well-understood patterns that can be easily modeled in synthetic data, for example:
- Randomness: If the data is purely random, it can be easily generated using a random number generator or other simple techniques.
- Gaussian distribution: If the data follows a Gaussian or normal distribution, it can be generated using a Gaussian random number generator.
- Uniform distribution: If the data follows a uniform distribution, it can be easily generated using a uniform random number generator.
- Linear relationships: If the data follows a linear relationship between variables, it can be modeled using simple linear regression techniques.
- Categorical variables: If the data consists of categorical variables, such as gender or occupation, it can be generated using a categorical distribution.
- Text data: If the data consists of text, it can be generated using natural language processing techniques, such as language models or text generation algorithms.
- Time series: If the data consists of time series data, such as stock prices or weather data, it can be generated using time series models, such as Autoregressive integrated moving average (ARIMA) or Long short-term memory (LSTM).
- Seasonality: If the data exhibits seasonal patterns, such as higher sales data during holiday periods, it can be generated using seasonal time series models.
- Proportions and percentages: If the data consists of proportions or percentages, such as product sales distribution across different regions, it can be generated using beta or Dirichlet distributions.
- Multivariate normal distribution: If the data follows a multivariate normal distribution, it can be generated using a multivariate Gaussian random number generator.
- Networks: If the data consists of network or graph data, such as social networks or transportation networks, it can be generated using network models, such as Erdos-Renyi or Barabasi-Albert models.
- Binary data: If the data consists of binary data, such as whether a customer churned, it can be generated using a Bernoulli distribution.
- Geospatial data: If it involves geospatial data, such as the location of points of interest, it can be easily using geospatial models, such as point processes or spatial point patterns.
- Customer behaviors: If the data involves customer behaviors, such as browsing or purchase histories, it can be generated using customer journey models, such as Markov models.
In general, simple and well-understood patterns can be easily modeled using synthetic data techniques. In contrast, more complex and nuanced patterns may require more sophisticated modeling techniques and a deeper understanding of the underlying data characteristics.
Creating Synthetic Data with Generative AI
We can use many popular generative AI-powered tools to create synthetic data for testing applications, constructing analytics pipelines, and building machine learning models. Tools include OpenAI ChatGPT, Microsoft’s all-new Bing Chat, ChatSonic, Tabnine, GitHub Copilot, and Amazon CodeWhisperer. For more information on these tools, check out my recent blog post:
Accelerating Development with Generative AI-Powered Coding Tools
Explore six popular generative AI-powered tools, including ChatGPT, Copilot, CodeWhisperer, Tabnine, Bing, and…garystafford.medium.com
Let’s start with a simple example of generating synthetic sales data. Suppose we have created a new sales forecasting application for coffee shops that we need to test using synthetic data. We might start by prompting a generative AI tool like OpenAI’s ChatGPT for some data:
Create a CSV file with 25 random sales records for a coffee shop.
Each record should include the following fields:
- id (incrementing integer starting at 1)
- date (random date between 1/1/2022 and 12/31/2022)
- time (random time between 6:00am and 9:00pm in 1-minute increments)
- product_id (incrementing integer starting at 1)
- product
- calories
- price in USD
- type (drink or food)
- quantity (random integer between 1 and 3)
- amount (price * quantity)
- payment type (cash, credit, debit, or gift card)
The content and structure of a prompt can vary, and this can strongly influence ChatGPT’s response. Based on the above prompt, the results were accurate but not very useful for testing our application in this format. ChatGPT cannot create a physical CSV file. Furthermore, ChatGPT’s response length is limited; only about twenty records were returned. According to ChatGPT, in general, ChatGPT can generate responses of up to 2,048 tokens, the maximum output length allowed by the GPT-3 model.

Instead of outputting the actual synthetic data, we could ask ChatGPT to write a program that can, in turn, generate the synthetic data. This option is certainly more scalable. Let’s prompt ChatGPT to write a Python program to generate synthetic sales data with the same characteristics as before:
Create a Python3 program to generate 100 sales of common items
sold in a coffee shop. The data should be written to a CSV file
and include a header row. Each record should include the following fields:
- id (incrementing integer starting at 1)
- date (random date between 1/1/2022 and 12/31/2022)
- time (random time between 6:00am and 9:00pm in 1-minute increments)
- product_id (incrementing integer starting at 1)
- product
- calories
- price in USD
- type (drink or food)
- quantity (random integer between 1 and 3)
- amount (price * quantity)
- payment type (cash, credit, debit, or gift card)
Using a single concise prompt, ChatGPT generated a complete Python program, including code comments, to generate synthetic sales data. Unfortunately, given ChatGPT’s response size limitation, the coffee shop menu was limited to just six items. Reprompting for more items would result in the truncation of the output and, thus, the program, making it unrunnable. Instead, we could use an additional prompt to generate a longer Python list of menu items and combine the two pieces of code in our IDE. Regardless, we will still need to copy and paste the code into our IDE to review, debug, test, and run.

ChatGPT’s Python program, copied and pasted into VS Code, ran without modifications, and wrote 100 synthetic sales records to a CSV file!

Using IDE-based Generative AI Tools
Although generating synthetic data directly or snippets of code in chat-based generative AI tools are helpful for limited use cases, writing code in IDE gives us several advantages:
- Code does not need to be copied and pasted from external sources into an IDE
- Consecutive lines of code, method, and block code completion overcome the single response size limits of chat-based tools like OpenAI ChatGPT
- Code can be reused and adapted to evolving use cases over time
- Python interpreter and debugger or equivalent for other languages
- Automatic code formatting, linting, and code style enforcement
- Unit, integration, and functional testing
- Static code analysis (SCA)
- Vulnerability scanning
- IntelliSense for code completion
- Source code management (SCM) / version control
Let’s use the same techniques we used with ChatGPT, but from within an IDE to generate three types of synthetic data. We will choose Microsoft’s VS Code with GitHub Copilot and Python as our programming language.

Source Code
All the code examples shown in this post can be found on GitHub.
Example #1: Coffee Shop Sales Data
First, we will start by outlining the program’s objective using code comments on the top of our Python file. This detailed context helps us to clearly express our goal and enables Copilot to generate an accurate response.
# Write a program that creates synthetic sales data for a coffee shop.
# The program should accept a command line argument that specifies the number of records to generate.
# The program should write the sales data to a file called 'coffee_shop_sales_data.csv'.
# The program should contain the following functions:
# - main() function that calls the other functions
# - function that returns one random product from a list of dictionaries
# - function that returns a dictionary containing one sales record
# - function that writes the sales records to a file
Following the import statements also generated with the assistance of Copilot, we will write the first function to return a random product from a list of 25 products. Again, we will use code comments as a prompt to generate the code. Copilot was able to generate 100% of the function’s code from the comments.
# Write a function to create list of dictionaries.
# The list of dictionaries should contain 15 drink items and 10 food items sold in a coffee shop.
# Include the product id, product name, calories, price, and type (Food or Drink).
# Capilize the first letter of each product name.
# Return a random item from the list of dictionaries.
Below is an example of Copilot’s ability to generate complete lines of code. Ultimately, it generated 100% of the function including choosing the items sold in a coffee shop, with a reasonable price and caloric count. Copilot is not limited to just understanding code.

Next, we will write a function to return a random sales record.
# Write a function to return a random sales record.
# The record should be a dictionary with the following fields:
# - id (an incrementing integer starting at 1)
# - date (a random date between 1/1/2022 and 12/31/2022)
# - time (a random time between 6:00am and 9:00pm in 1 minute increments)
# - product_id, product, calories, price, and type (from the get_product function)
# - quantity (a random integer between 1 and 3)
# - amount (price * quantity)
# - payment type (Cash, Credit, Debit, Gift Card, Apple Pay, Google Pay, or Venmo)
Again, Copilot generated 100% of the function’s code as a single block based on the code comments.

Lastly, we will create a function to write the sales data into a CSV file using Copilot’s help.
# Write a function to write the sales records to a CSV file called 'coffee_shop_sales.csv'.
# Use an input parameter to specify the number of records to write.
# The CSV file must have a header row and be comma delimited.
# All string values must be enclosed in double quotes.
Again below, we see an example of Copilot’s ability to generate an entire Python function. I needed to correct a few problems with the generated code. First, there was a lack of quotes for string values, which I added to the function (quotechar='"', quoting=csv.QUOTE_NONNUMERIC). Also, the function was missing a key line of code, sale = get_sales_record(), which would have caused the code to fail. Remember, just because the code was generated does not mean it is correct.

Here is the complete program that creates synthetic sales data for a coffee shop with Copilot assistance:
Copilot generated an astounding 80–85% of the program’s final code. The initial program took 10–15 minutes to write using code comments. I then added a few new features, including the ability to pass in the record count on the command line and the hash-based transaction id, which took another 5 minutes. Finally, I used GitHub Code Brushes to optimize the code and generate the Python docstrings, and Black Formatter and Flake8 extensions to format and lint, all of which took less than 5 minutes. With testing and debugging, the total time was about 25–30 minutes.
The most significant difference with Copilot was that I never had to leave the IDE to look up code references or find existing sales datasets or even a coffee shop menu to duplicate. The code, as well as the list of products, price, calories, and product type, were all generated by Copilot.
To make this example more realistic, you could use Copilot’s assistance to write algorithms capable of reflecting daily, weekly, and seasonal variations in product choice and sales volumes. This might include simulating increased sales during the busy morning rush hour or a preference for iced drinks in the summer months versus hot drinks during the winter months.
Here is an example of the synthetic sales data output by the example application:
Example #2: Residential Address Data
We could use these same techniques to generate a list of residential addresses. To start, we can prompt Copilot for the values in a list of common street names and street types in the United States:
# Write a function that creates a list of common street names
# in the United States, in alphabetical order.
# List should be in alphabetical order. Each name should be unique.
# Return a random street name.
def get_street_name():
street_names = [
"Ash", "Bend", "Bluff", "Branch", "Bridge", "Broadway", "Brook", "Burg",
"Bury", "Canyon", "Cape", "Cedar", "Cove", "Creek", "Crest", "Crossing",
"Dale", "Dam", "Divide", "Downs", "Elm", "Estates", "Falls", "Fifth",
"First", "Fork", "Fourth", "Glen", "Green", "Grove", "Harbor", "Heights",
"Hickory", "Hill", "Hollow", "Island", "Isle", "Knoll", "Lake", "Landing",
...
]
return random.choice(street_names)
# Write a function that creates a list of common street types
# in the United States, in alphabetical order.
# List should be in alphabetical order. Each name should be unique.
# Return a random street type.
def get_street_type():
street_types = [
"Alley", "Avenue", "Bend", "Bluff", "Boulevard", "Branch", "Bridge", "Brook",
"Burg", "Circle", "Commons", "Court", "Drive", "Highway", "Lane", "Parkway",
"Place", "Road", "Square", "Street", "Terrace", "Trail", "Way"
]
return random.choice(street_types)
Next, we can create a function that returns a property type based on a categorical distribution of common residential property types with the prompt:
# Write a function to return a random property type.
# Accept a random value between 0 and 1 as an input parameter.
# The function must return one of the following values based on the %:
# 63% Single-family, 26% Multi-family, 4% Condo,
# 3% Townhouse, 2% Mobile home, 1% Farm, 1% Other.
Again, Copilot generated 100% of the function’s code as a single block based on the code comments.

Additionally, we could have Copilot help us generate a list of the 50 largest cities in the United States with state, zip code, and population, with the prompt:
# Write a function to returns the 50 largest cities in the United States.
# List should be sorted in descending order by population.
# Include the city, state abbreviation, zip code, and population.
# Return a list of dictionaries.
Once again, Copilot generated 100% of the function’s code using a combination of single lines and code blocks based on the code comments.

When randomly choosing a city, we can use a categorical distribution of populations of all the cities to control the distribution of cities in the final synthetic dataset. For example, there will be more addresses in larger cities like New York City or Los Angeles than in smaller cities like Buffalo or Virginia Beach, with the prompt:
# Write a function that calculates the total population of the list of cities.
# Add a 'pcnt_of_total_population' and 'pcnt_running_total' columns to list.
# Returns a sorted list of cities by population.
Here is the complete program that creates synthetic US-based address data with Copilot assistance:
To make this example more realistic, you could use Copilot’s assistance to write algorithms capable of accurately reflecting assessed property values based on the type of residence and the zip code.
Here is an example of the synthetic US-based residential address data output by the example application:
Example #3: Demographic Data
We could use the same techniques again to generate synthetic demographic data. With the assistance of Copilot, we can write functions that randomly return typical feminine or masculine first names (forenames) and common last names (surnames) found in the United States, for this use case.
# Write a function that generates a list of common feminine first names in the United States.
# List should be in alphabetical order.
# Each name should be unique.
# Return random first name.
def get_first_name_feminine():
first_name_feminine = [
"Alice", "Amanda", "Amy", "Angela", "Ann", "Anna", "Barbara", "Betty",
"Brenda", "Carol", "Carolyn", "Catherine", "Christine", "Cynthia", "Deborah", "Debra",
"Diane", "Donna", "Doris", "Dorothy", "Elizabeth", "Frances", "Gloria", "Heather",
"Helen", "Janet", "Jennifer", "Jessica", "Joyce", "Julie", "Karen", "Kathleen", "Kimberly",
]
return random.choice(first_name_feminine)
With the assistance of Copilot, we can also write functions that return demographic information, such as age, gender, race, marital status, religion, and political affiliation. Similar to the previous sales data example, we can influence the final synthetic dataset based on categorical distributions of different demographic categories, for instance, with the prompt:
# Write a function that returns a person's martial status.
# Accept a random value between 0 and 1 as an input parameter.
# The function must return one of the following values based on the %:
# 50% Married, 33% Single, 17% Unknown.
def get_martial_status(rnd_value):
if rnd_value < 0.50:
return "Married"
elif rnd_value < 0.83:
return "Single"
else:
return "Unknown"
By altering the categorical distributions, we can quickly alter the resulting synthetic dataset to reflect differing demographic characteristics: an older or younger population, the predominance of a single race, religious affiliation, or marital status, or the ratio of males to females.
Next, we can use a Gaussian distribution (aka normal distribution) to return the year of birth in a bell-shaped curve, given a mean year and a standard deviation, using Python’s random.normalvariate function.
# Write a function that generates a normal distribution of date of births.
# with a mean year of 1975 and a standard deviation of 10.
# Return random date of birth as a string in the format YYYY-MM-DD
def get_dob():
day_of_year = random.randint(1, 365)
year_of_birth = int(random.normalvariate(1975, 10))
dob = date(int(year_of_birth), 1, 1) + timedelta(day_of_year - 1)
dob = dob.strftime("%Y-%m-%d")
return dob
Here is the complete program that creates synthetic demographic data with Copilot’s assistance:
To make this example more realistic, you could use Copilot’s assistance to write algorithms capable of more accurately representing the nuanced associations and correlations between age, gender, race, marital status, religion, and political affiliation.
Here is an example of the synthetic demographic data output by the example application:
Generative AI Tools for Unit Testing
In addition to writing code and documentation, a common use of generative AI code assistants like Copilot is unit tests. For example, we can create unit tests for each function in our coffee shop sales data code generator, using the same method of prompting with code comments.

Conclusion
In this post, we learned how Generative AI could assist us in creating synthetic data for software development, analytics, and machine learning. The examples herein generated data using simple techniques. Using advanced modeling techniques, we could generate increasingly complex, realistic synthetic data.
To learn about other ways Generative AI can be used to assist in writing code, please read my previous article, Ten Ways to Leverage Generative AI for Development on AWS.
🔔 To keep up with future content, follow Gary Stafford on LinkedIn.
This blog represents my viewpoints and not those of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners.
Ten Ways to Leverage Generative AI for Development on AWS
Posted by Gary A. Stafford in AI/ML, AWS, Bash Scripting, Big Data, Build Automation, Client-Side Development, Cloud, DevOps, Enterprise Software Development, Kubernetes, Python, Serverless, Software Development, SQL on April 3, 2023
Explore ten ways you can use Generative AI coding tools to accelerate development and increase your productivity on AWS

Generative AI coding tools are a new class of software development tools that leverage machine learning algorithms to assist developers in writing code. These tools use AI models trained on vast amounts of code to offer suggestions for completing code snippets, writing functions, and even entire blocks of code.
Quote generated by OpenAI ChatGPT
Introduction
Combining the latest Generative AI coding tools with a feature-rich and extensible IDE and your coding skills will accelerate development and increase your productivity. In this post, we will look at ten examples of how you can use Generative AI coding tools on AWS:
- Application Development: Code, unit tests, and documentation
- Infrastructure as Code (IaC): AWS CloudFormation, AWS CDK, Terraform, and Ansible
- AWS Lambda: Serverless, event-driven functions
- IAM Policies: AWS IAM policies and Amazon S3 bucket policies
- Structured Query Language (SQL): Amazon RDS, Amazon Redshift, Amazon Athena, and Amazon EMR
- Big Data: Apache Spark and Flink on Amazon EMR, AWS Glue, and Kinesis Data Analytics
- Configuration and Properties files: Amazon MSK, Amazon EMR, and Amazon OpenSearch
- Apache Airflow DAGs: Amazon MWAA
- Containerization: Kubernetes resources, Helm Charts, Dockerfiles for Amazon EKS
- Utility Scripts: PowerShell, Bash, Shell, and Python
Choosing a Generative AI Coding Tool
In my recent post, Accelerating Development with Generative AI-Powered Coding Tools, I reviewed six popular tools: ChatGPT, Copilot, CodeWhisperer, Tabnine, Bing, and ChatSonic.
For this post, we will use GitHub Copilot, powered by OpenAI Codex, a new AI system created by OpenAI. Copilot suggests code and entire functions in real-time, right from your IDE. Copilot is trained in all languages that appear in GitHub’s public repositories. GitHub points out that the quality of suggestions you receive may depend on the volume and diversity of training data for that language. Similar tools in this category are limited in the number of languages they support compared to Copilot.

Copilot is currently available as an extension for Visual Studio Code, Visual Studio, Neovim, and JetBrains suite of IDEs. The GitHub Copilot extension for Visual Studio Code (VS Code) already has 4.8 million downloads, and the GitHub Copilot Nightly extension, used for this post, has almost 280,000 downloads. I am also using the GitHub Copilot Labs extension in this post.

Ten Ways to Leverage Generative AI
Take a look at ten examples of how you can use Generative AI coding tools to increase your development productivity on AWS. All the code samples in this post can be found on GitHub.
1. Application Development
According to GitHub, trained on billions of lines of code, GitHub Copilot turns natural language prompts into coding suggestions across dozens of languages. These features make Copilot ideal for developing applications, writing unit tests, and authoring documentation. You can use GitHub Copilot to assist with writing software applications in nearly any popular language, including Go.
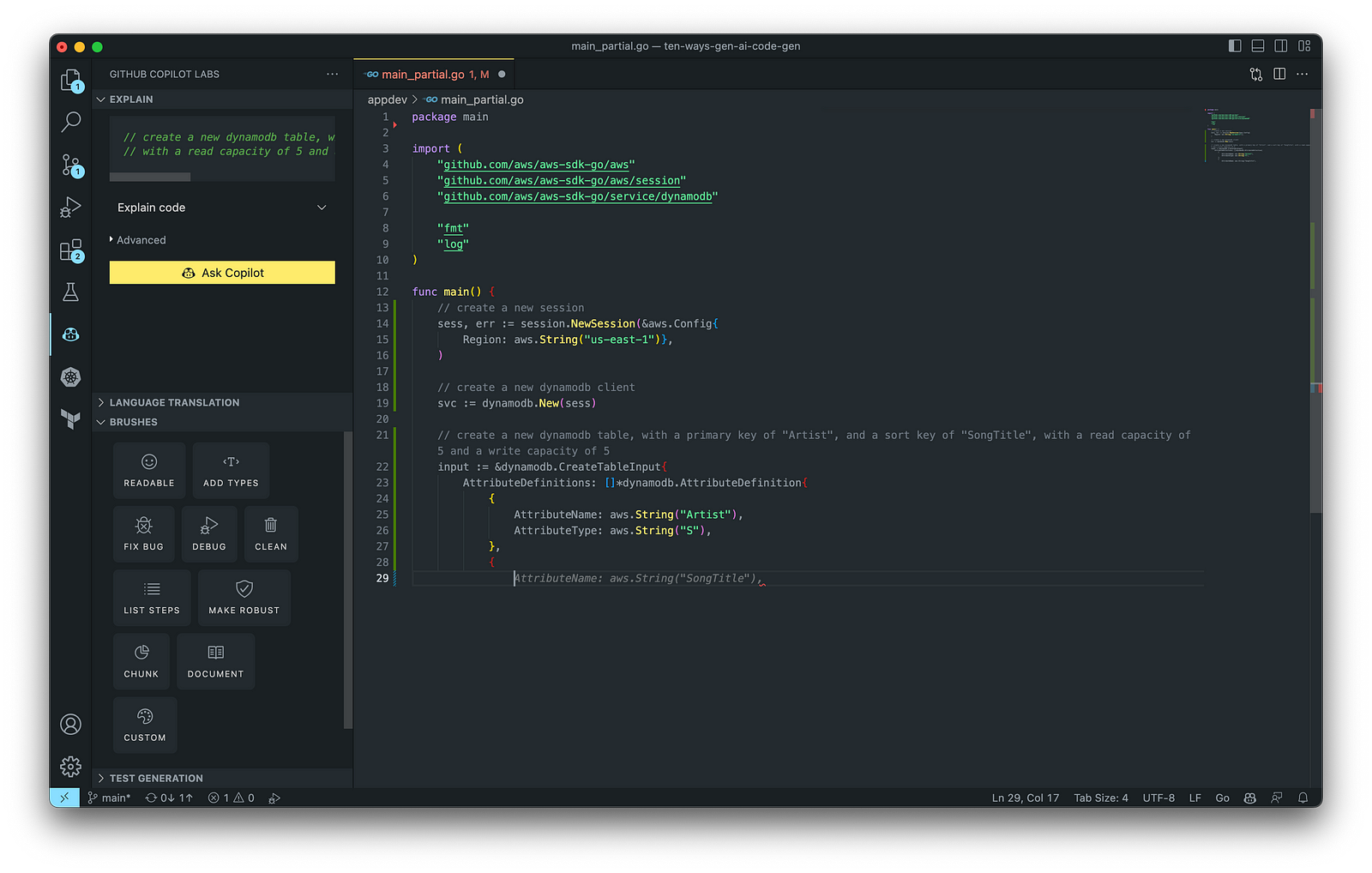
The final application, which uses the AWS SDK for Go to create an Amazon DynamoDB table, shown below, was formatted using the Go extension by Google and optimized using the ‘Readable,’ ‘Make Robust,’ and ‘Fix Bug’ GitHub Code Brushes.
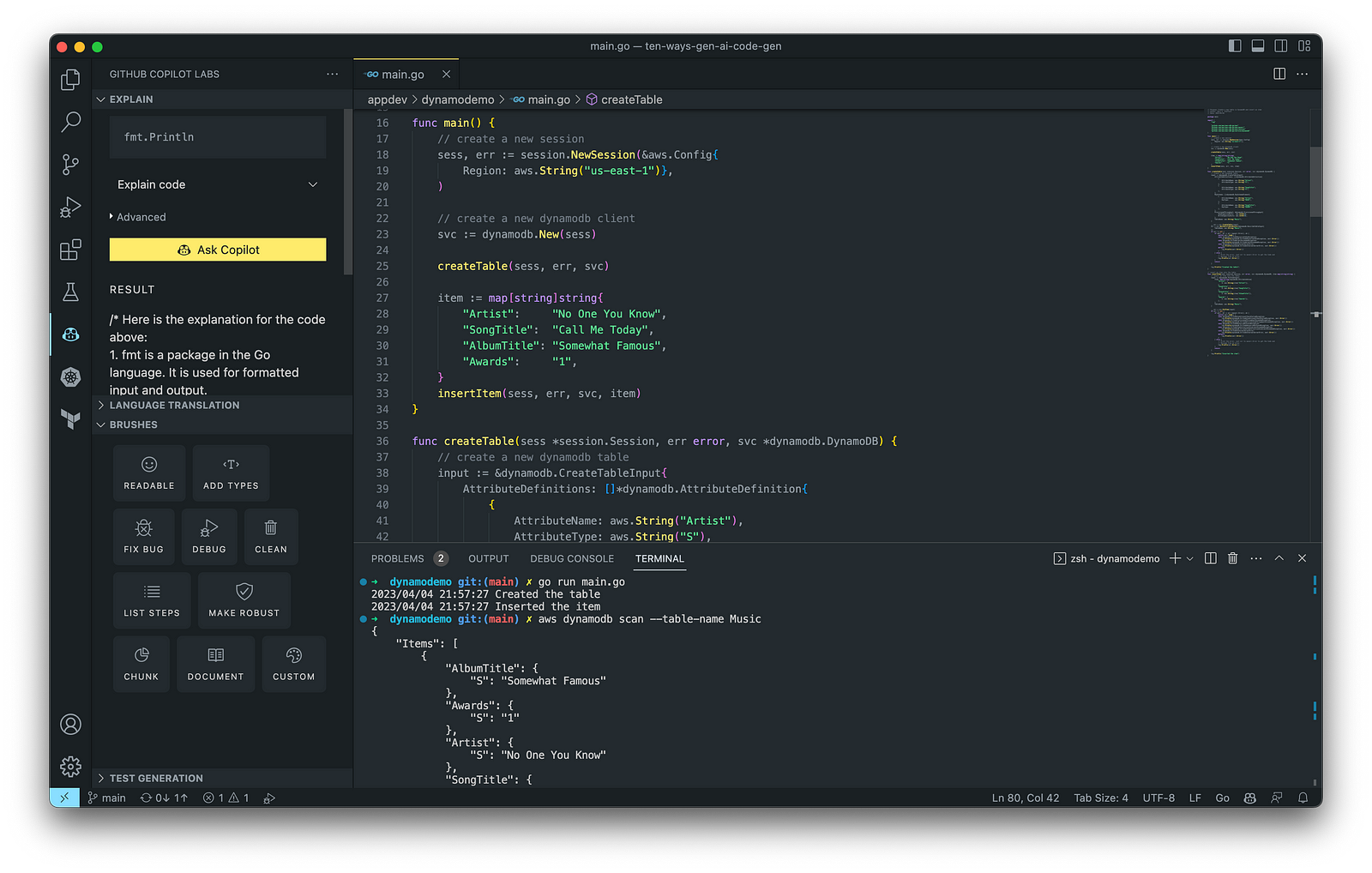
Generating Unit Tests
Using JavaScript and TypeScript, you can take advantage of TestPilot to generate unit tests based on your existing code and documentation. TestPilot, part of GitHub Copilot Labs, uses GitHub Copilot’s AI technology.

2. Infrastructure as Code (IaC)
Widespread Infrastructure as Code (IaC) tools include Pulumi, AWS CloudFormation, Azure ARM Templates, Google Deployment Manager, AWS Cloud Development Kit (AWS CDK), Microsoft Bicep, and Ansible. Many IaC tools, except AWS CDK, use JSON- or YAML-based domain-specific languages (DSLs).
AWS CloudFormation
AWS CloudFormation is an Infrastructure as Code (IaC) service that allows you to easily model, provision, and manage AWS and third-party resources. The CloudFormation template is a JSON or YAML formatted text file. You can use GitHub Copilot to assist with writing IaC, including AWS CloudFormation in either JSON or YAML.

You can use the YAML Language Support by Red Hat extension to write YAML in VS Code.

VS Code has native JSON support with JSON Schema Store, which includes AWS CloudFormation. VS Code uses the CloudFormation schema for IntelliSense and flag schema errors in templates.

HashiCorp Terraform
In addition to AWS CloudFormation, HashiCorp Terraform is an extremely popular IaC tool. According to HashiCorp, Terraform lets you define resources and infrastructure in human-readable, declarative configuration files and manages your infrastructure’s lifecycle. Using Terraform has several advantages over manually managing your infrastructure.
Terraform plugins called providers let Terraform interact with cloud platforms and other services via their application programming interfaces (APIs). You can use the AWS Provider to interact with the many resources supported by AWS.
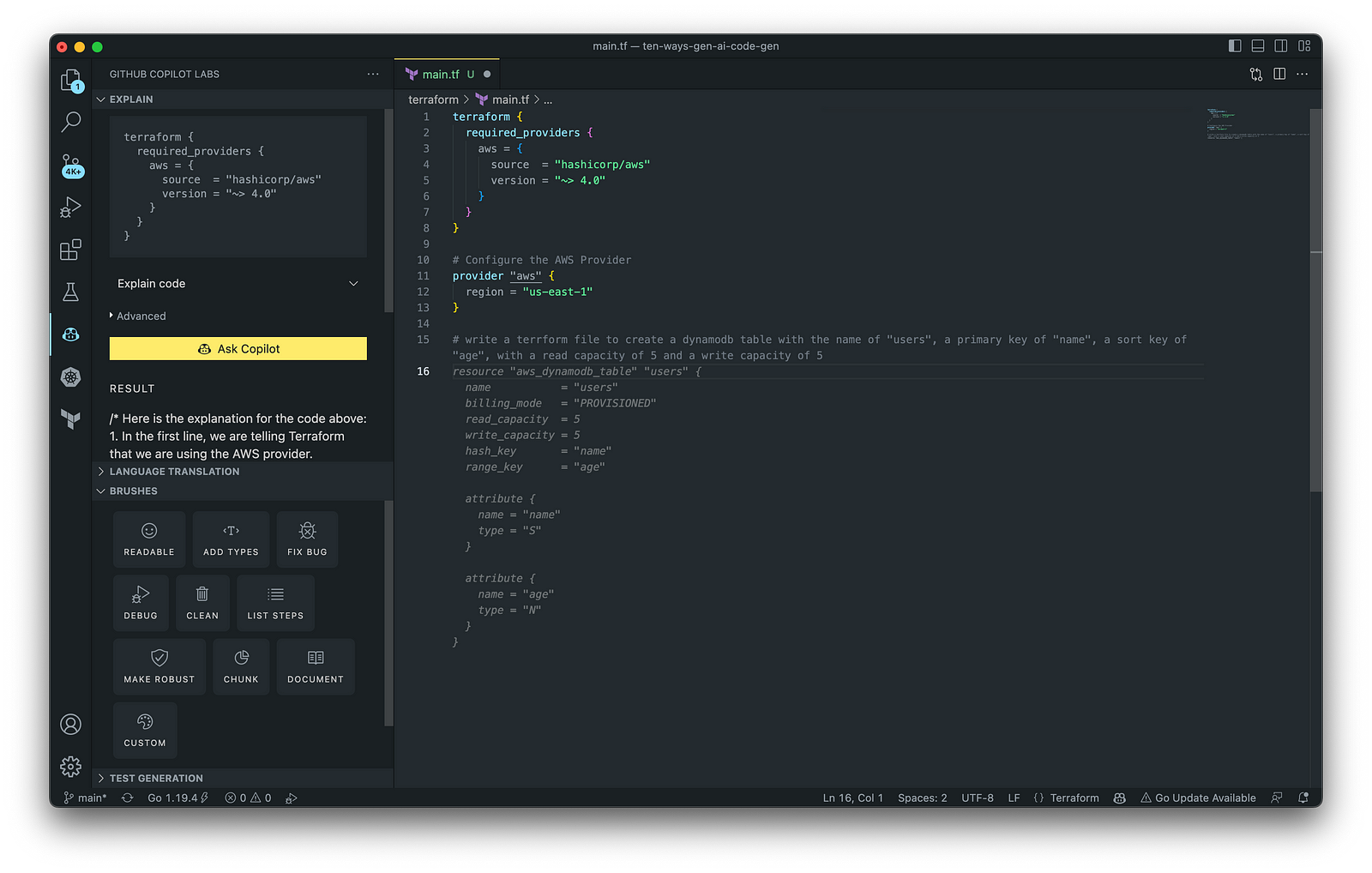
3. AWS Lambda
Lambda, according to AWS, is a serverless, event-driven compute service that lets you run code for virtually any application or backend service without provisioning or managing servers. You can trigger Lambda from over 200 AWS services and software as a service (SaaS) applications and only pay for what you use. AWS Lambda natively supports Java, Go, PowerShell, Node.js, C#, Python, and Ruby. AWS Lambda also provides a Runtime API allowing you to use additional programming languages to author your functions.
You can use GitHub Copilot to assist with writing AWS Lambda functions in any of the natively supported languages. You can further optimize the resulting Lambda code with GitHub’s Code Brushes.

The final Python-based AWS Lambda, below, was formatted using the Black Formatter and Flake8 extensions and optimized using the ‘Readable,’ ‘Debug,’ ‘Make Robust,’ and ‘Fix Bug’ GitHub Code Brushes.

You can easily convert the Python-based AWS Lambda to Java using GitHub Copilot Lab’s ability to translate code between languages. Install the GitHub Copilot Labs extension for VS Code to try out language translation.

4. IAM Policies
AWS Identity and Access Management (AWS IAM) is a web service that helps you securely control access to AWS resources. According to AWS, you manage access in AWS by creating policies and attaching them to IAM identities (users, groups of users, or roles) or AWS resources. A policy is an object in AWS that defines its permissions when associated with an identity or resource. IAM policies are stored on AWS as JSON documents. You can use GitHub Copilot to assist in writing IAM Policies.
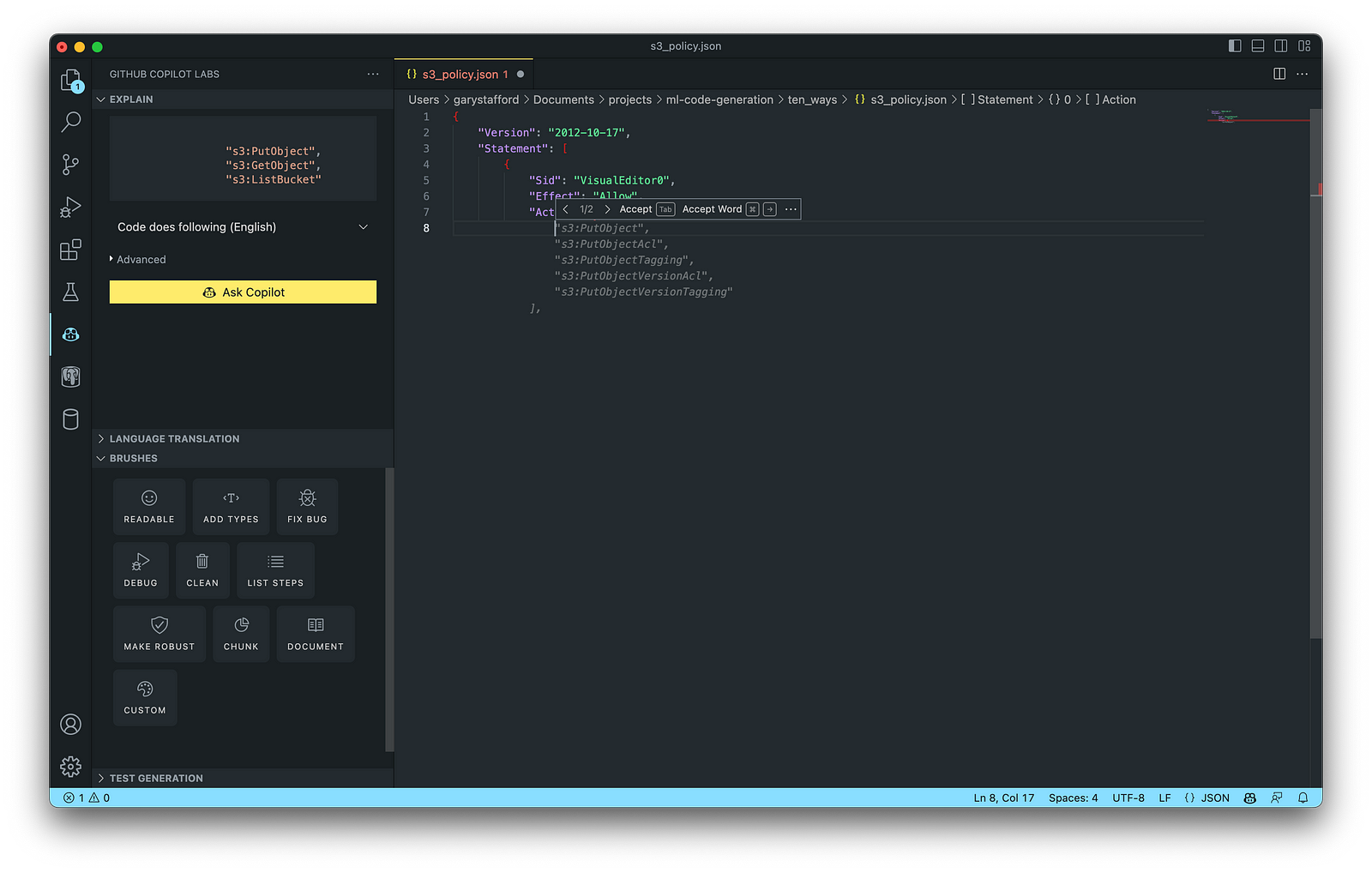
The final AWS IAM Policy, below, was formatted using VS Code’s built-in JSON support.

5. Structured Query Language (SQL)
SQL has many use cases on AWS, including Amazon Relational Database Service (RDS) for MySQL, PostgreSQL, MariaDB, Oracle, and SQL Server databases. SQL is also used with Amazon Aurora, Amazon Redshift, Amazon Athena, Apache Presto, Trino (PrestoSQL), and Apache Hive on Amazon EMR.
You can use IDEs like VS Code with its SQL dialect-specific language support and formatted extensions. You can further optimize the resulting SQL statements with GitHub’s Code Brushes.

The final PostgreSQL script, below, was formatted using the Sql Formatter extension and optimized using the ‘Readable’ and ‘Fix Bug’ GitHub Code Brushes.

6. Big Data
Big Data, according to AWS, can be described in terms of data management challenges that — due to increasing volume, velocity, and variety of data — cannot be solved with traditional databases. AWS offers managed versions of Apache Spark, Apache Flink, Apache Zepplin, and Jupyter Notebooks on Amazon EMR, AWS Glue, and Amazon Kinesis Data Analytics (KDA).
Apache Spark
According to their website, Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters. Spark jobs can be written in various languages, including Python (PySpark), SQL, Scala, Java, and R. Apache Spark is available on a growing number of AWS services, including Amazon EMR and AWS Glue.

The final Python-based Apache Spark job, below, was formatted using the Black Formatter extension and optimized using the ‘Readable,’ ‘Document,’ ‘Make Robust,’ and ‘Fix Bug’ GitHub Code Brushes.

7. Configuration and Properties Files
According to TechTarget, a configuration file (aka config) defines the parameters, options, settings, and preferences applied to operating systems, infrastructure devices, and applications. There are many examples of configuration and properties files on AWS, including Amazon MSK Connect (Kafka Connect Source/Sink Connectors), Amazon OpenSearch (Filebeat, Logstash), and Amazon EMR (Apache Log4j, Hive, and Spark).
Kafka Connect
Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other systems. It makes it simple to quickly define connectors that move large collections of data into and out of Kafka. AWS offers a fully-managed version of Kafka Connect: Amazon MSK Connect. You can use GitHub Copilot to write Kafka Connect Source and Sink Connectors with Kafka Connect and Amazon MSK Connect.

The final Kafka Connect Source Connector, below, was formatted using VS Code’s built-in JSON support. It incorporates the Debezium connector for MySQL, Avro file format, schema registry, and message transformation. Debezium is a popular open source distributed platform for performing change data capture (CDC) with Kafka Connect.

8. Apache Airflow DAGs
Apache Airflow is an open-source platform for developing, scheduling, and monitoring batch-oriented workflows. Airflow’s extensible Python framework enables you to build workflows connecting with virtually any technology. DAG (Directed Acyclic Graph) is the core concept of Airflow, collecting Tasks together, organized with dependencies and relationships to say how they should run.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a managed orchestration service for Apache Airflow. You can use GitHub Copilot to assist in writing DAGs for Apache Airflow, to be used with Amazon MWAA.

The final Python-based Apache Spark job, below, was formatted using the Black Formatter extension. Unfortunately, based on my testing, code optimization with GitHub’s Code Brushes is impossible with Airflow DAGs.

9. Containerization
According to Check Point Software, Containerization is a type of virtualization in which all the components of an application are bundled into a single container image and can be run in isolated user space on the same shared operating system. Containers are lightweight, portable, and highly conducive to automation. AWS describes containerization as a software deployment process that bundles an application’s code with all the files and libraries it needs to run on any infrastructure.
AWS has several container services, including Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Registry (Amazon ECR), and AWS Fargate. Several code-based resources can benefit from a Generative AI coding tool like GitHub Copilot, including Dockerfiles, Kubernetes resources, Helm Charts, Weaveworks Flux, and ArgoCD configuration.
Kubernetes
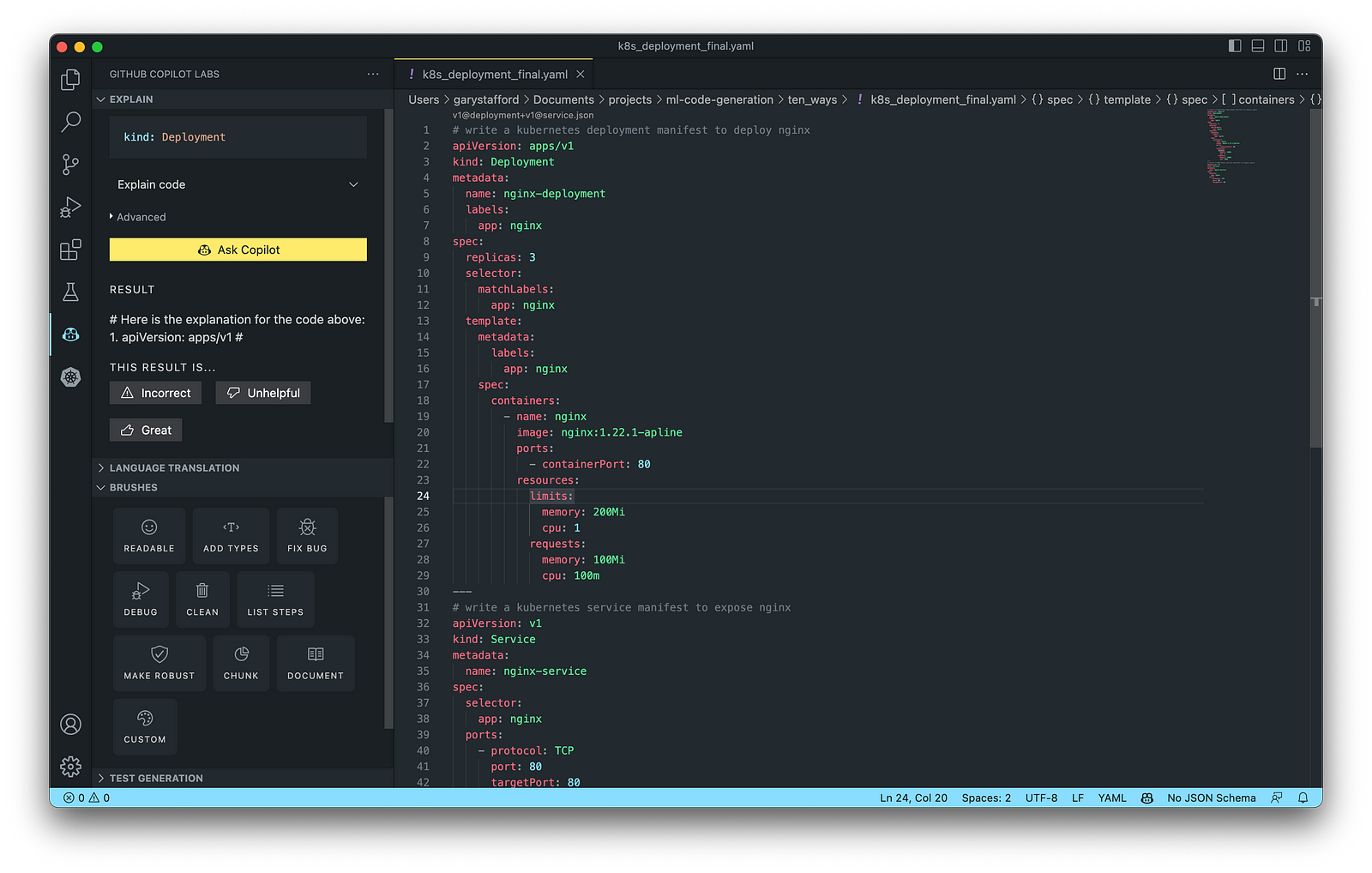
Kubernetes objects are represented in the Kubernetes API and expressed in YAML format. Below is a Kubernetes Deployment resource file, which creates a ReplicaSet to bring up multiple replicas of nginx Pods.

The final Kubernetes resource file below contains Deployment and Service resources. In addition to GitHub Copilot, you can use Microsoft’s Kubernetes extension for VS Code to use IntelliSense and flag schema errors in the file.
10. Utility Scripts
According to Bing AI — Search, utility scripts are small, simple snippets of code written as independent code files designed to perform a particular task. Utility scripts are commonly written in Bash, Shell, Python, Ruby, PowerShell, and PHP.
AWS utility scripts leverage the AWS Command Line Interface (AWS CLI) for Bash and Shell and AWS SDK for other programming languages. SDKs take the complexity out of coding by providing language-specific APIs for AWS services. For example, Boto3, AWS’s Python SDK, easily integrates your Python application, library, or script with AWS services, including Amazon S3, Amazon EC2, Amazon DynamoDB, and more.

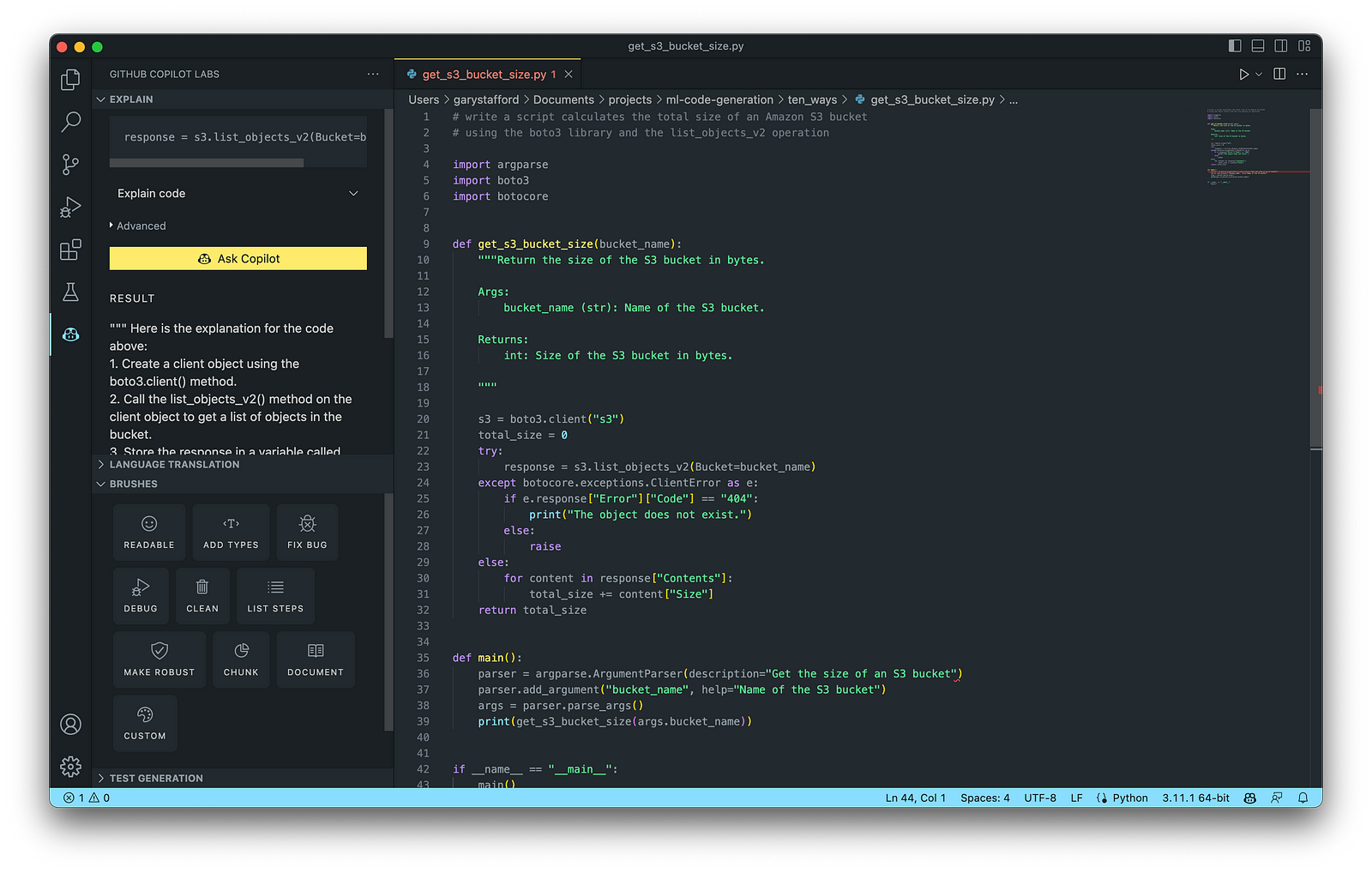
An example of a Python script to calculate the total size of an Amazon S3 bucket, below, was inspired by 100daysofdevops/N-days-of-automation, a fantastic set of open source AWS-oriented automation scripts.
Conclusion
In this post, you learned ten ways to leverage Generative AI coding tools like GitHub Copilot for development on AWS. You saw how combining the latest generation of Generative AI coding tools, a mature and extensible IDE, and your coding experience will accelerate development, increase productivity, and reduce cost.
🔔 To keep up with future content, follow Gary Stafford on LinkedIn.
This blog represents my viewpoints and not those of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners.
Accelerate Software Development with Six Popular Generative AI-Powered Coding Tools
Posted by Gary A. Stafford in AI/ML, Cloud, Software Development on March 25, 2023
Explore six popular generative AI-powered tools, including ChatGPT, Copilot, CodeWhisperer, Tabnine, Bing, and ChatSonic

Introduction
Modern software systems continue to grow inherently more complex over time. We have evolved from bulky monoliths to loosely coupled, event-driven, fault-tolerant, stateless, serverless, cloud-native, real-time, microservices-based, API-first, continuously deployed distributed systems, festooned with CQRS, 2PC, DDD, EDA, DOMA, Sagas, BFFs, GraphQL, gRPC, micro-frontends, contract tests, and Hexagonal architectures. Generative AI-powered coding tools do not necessarily make a developer’s job easier — they assist developers in dealing with increasing system complexity.
This post examines six popular generative AI-powered coding tools, including chat-based OpenAI ChatGPT, Microsoft’s all-new Bing Chat, and ChatSonic, as well as IDE-based Tabnine, GitHub Copilot, and Amazon CodeWhisperer (Preview). In this post, each tool will assist with developing an identical program to complete a series of common tasks on AWS. We will then compare and contrast each tool’s ease of use and the resulting code accuracy and quality.
“Generative AI coding tools are a new class of software development tools that leverage machine learning algorithms to assist developers in writing code. These tools use AI models trained on vast amounts of code to offer suggestions for completing code snippets, writing functions, and even entire blocks of code.” (quote generated by ChatGPT)
The generative AI space is evolving at a breakneck pace. Tools continue to rapidly improve their AI models, add new features, and adjust pricing. In just the short time it took to research and write this article:
- OpenAI announced GPT-4 on March 14, 2023
- Microsoft announced new Bing running on GPT-4 on March 14, 2023
- Google’s Bard AI launched in Early Access on March 21, 2023
- GPT-4 was added to Azure’s OpenAI Service on March 21, 2023
- Writesonic ChatSonic revised its pricing model on March 21, 2023
- GitHub announced GitHub Copilot X on March 22, 2023
- OpenAI announced ChatGPT plugins on March 23, 2023
Generative AI
According to McKinsey & Company in their recent article, What is generative AI?, “Generative artificial intelligence (AI) describes algorithms (such as ChatGPT) that can be used to create new content, including audio, code, images, text, simulations, and videos. Recent new breakthroughs in the field have the potential to drastically change the way we approach content creation.”
Generative AI for Code Generation
According to Papers with Code, “Code Generation is an important field to predict explicit code or program structure from multimodal data sources such as incomplete code, programs in another programming language, natural language descriptions or execution examples. Code Generation tools can assist the development of automatic programming tools to improve programming productivity.” Similarly, according to MarketTechPost, “Generative AI technologies have led to a surge of interest and progress in code generation applications. These technologies use machine learning algorithms and natural language processing to assist developers in automating the time-consuming and laborious portions of coding.”
Common Features
Standard features of leading generative AI-powered coding tools include the following:
- Whole-line, full-function, and block code completion
- Natural language to code completion
- Code suggestions based on the model’s pre-trained dataset
- Context-aware recommendations based on your existing code
- Context-aware recommendations based on your code comments
- Native integration with popular IDEs
- Multi-language coding support
- Respond to follow-up instructions (resulting in refinement of code)
Benefits
The benefits of generative AI-powered code generation include the following:
- Accelerate application development
- Improve development productivity
- Decrease development costs
- Produce higher-quality, more consistent code
- Enable better code documentation and test coverage
- Learn new programming languages and coding techniques
- Contributes to the democratization of programming
Methods of Code Generation
As you explore different generative AI tools for writing code, you will likely develop techniques for generating effective code based on the tool.
Long-form Narrative Approach
With chat-based tools like OpenAI ChatGPT, Microsoft Bing Chat, and ChatSonic, developers might use a longer narrative-type instruction (aka one-shot approach) rather than a series of more concise instructions to generate the code. For example:
- “Write a Python script to create a new DynamoDB table with a partition key of username, a sort key of last_name, and provisioned throughput of 5 RCUs and 5 WCUs. Pass the table name into the function as a variable. Wait until the table exists before continuing. Include try/except blocks and logging. If the table fails to be created, log a FATAL error and exit, and if the table already exists, log a WARNING. Add a main function and wrap everything in a Class called DynamoUtilities.”
- “Add three new functions, including a function to insert a new item into a table, a function to retrieve an item from a table, and a function to delete a table.”
Below is an example of OpenAI ChatGPT’s response using this approach. Of course, this method doesn’t limit you from following up with additional instructions to further enhance and refine the code.

Progressive Approach
Although the previous approach makes for an impressive demonstration, that method of writing code differs from how most developers work. Instead, a developer might use a progressive approach (aka chain of thought) to generate and refine the code with chat-based tools. In my tests with chat-based tools, I found a progressive approach of asking multiple, concise instructions to guide the model toward the desired behavior produced higher-quality code with fewer errors. For example:
- “Write a Python script to create a DynamoDB table with a partition key of username, a sort key of last_name, and provisioned throughput of 5 RCUs and 5 WCUs.”
- “Pass the table name into the create table function as a variable.”
- “Wait until the table exists before continuing.”
- “Add logging with the default level of INFO.”
- “Include try/except blocks, log a FATAL error and exit if the table fails to be created and a WARNING if the table already exists.”
- “Add a function to delete the table and wait until the table is deleted before continuing.”
- “Add a main function.”
- “Add a function to insert a new item into a table and a function to get an item from a table.”
- “Wrap the code in a Class called DynamoUtilities.”
- “Convert the Python code to Java.”
Below is an example of OpenAI ChatGPT’s response using a progressive code generation approach. The final code results from an initial prompt and a series of follow-up instructions to enhance and refine the code.
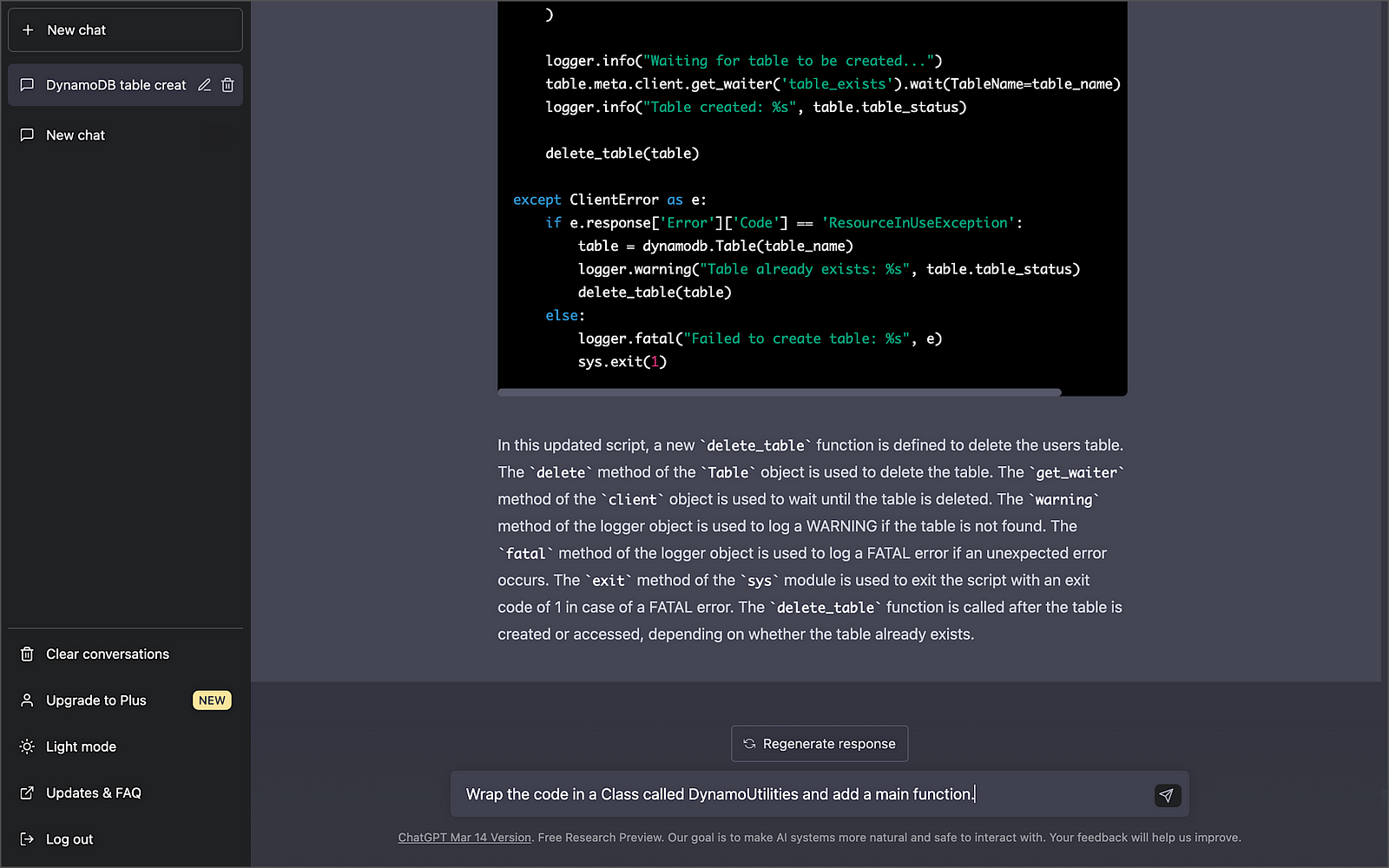
Be aware that most chat-based tools have a session limit. For example, Bing has a limit of 15 chats per session, which will limit the number of follow-up instructions you can use to modify the code. Additionally, the slightest variation in how an instruction is phrased may significantly impact the code generated. There is a whole science and blossoming industry around prompt optimization!
IDE-based Code Generation
Tabnine, GitHub Copilot, and Amazon CodeWhisperer use generative AI technology to predict and suggest new lines or blocks of code based on their trained pre-model and the context and syntax of existing code and code comments within your IDE. These tools differ from tools like OpenAI ChatGPT, Microsoft Bing Chat, and ChatSonic, which can generate code using a chat-based interaction with the user. IDE-based tools like Tabnine, GitHub Copilot, and Amazon CodeWhisperer are like having an AI-powered paired programming partner that enhances your development productivity. However, these tools also require a reasonable level of development experience, in my opinion.
Below, we see an example of Tabnine Pro’s ability to generate whole-line code completion (line 11) and full-function code completion (lines 12–41) based on the existing code context and syntax (lines 1–11).
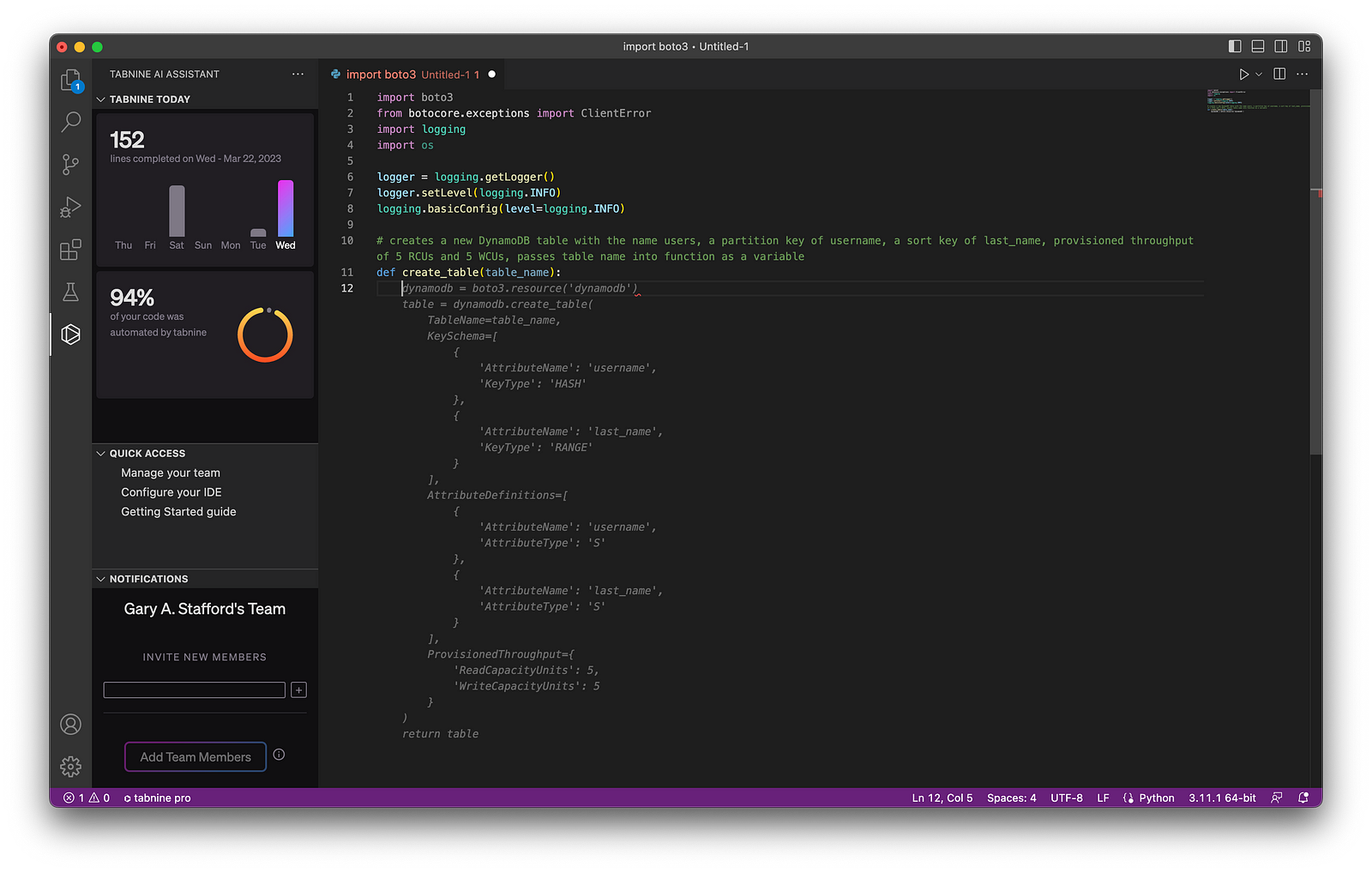
Although writing code comments may be perceived as easier than using generative code completion, many industry pundits dissuade what they call “ comment-driven development.” Instead, they believe using generative AI-based code completion results in superior results.
Testing Generative AI Tools
With the assistance of each tool, I have written a Python script to perform the following tasks: 1) create an Amazon DynamoDB table, 2) insert an item into a table, 3) retrieve an item from a table, and finally, 4) delete a table. Although I tested the results in multiple IDEs, I only included the results from Visual Studio Code (VS Code). Tool interactions and code results were consistent across IDEs.
As a reference for “what good looks like” when evaluating code accuracy and quality, I referenced the examples provided with AWS’s Boto3 SDK and DynamoDB API documentation and the PEP 8 — Style Guide for Python Code.

An example of the final code, written with the assistance of GitHub Copilot, including unit tests, is available on GitHub.
OpenAI ChatGPT

According to Wikipedia, ChatGPT (Generative Pre-trained Transformer) “is an artificial intelligence chatbot developed by OpenAI and launched in November 2022. It is built on top of OpenAI GPT-3 and GPT-4 [released March 14, 2023] families of large language models [LLMs] and has been fine-tuned (an approach to transfer learning) using both supervised and reinforcement learning techniques.”
According to the VC-backed California-based startup OpenAI, “ChatGPT interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer follow-up questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests.” Further, “ChatGPT was optimized for dialogue using Reinforcement Learning with Human Feedback (RLHF), which uses human demonstrations and preference comparisons to guide the model toward desired behavior.”
Getting Started with ChatGPT
You can get started with ChatGPT for free using the Free Plan. However, if you want to use the latest generative AI models, get faster results, and ensure availability, you should consider ChatGPT Plus for $20/month. GPT-4 is now available through the ChatGPT Plus Plan.

ChatGPT’s Free Plan is a great way to test the generative AI waters. However, due to potentially slow chat responses and unavailability during peak times, you will want to upgrade to ChatGPT Plus if your team plans to rely on the tool.

Using ChatGPT
OpenAI ChatGPT is available through a web-based chat interface or programmatically using OpenAI APIs. For API users, OpenAI provides online API references, code examples, and an interactive coding playground. According to OpenAI, “The OpenAI API can be applied to virtually any task that involves understanding or generating natural language, code, or images.”

Below is an example of output using ChatGPT’s UI. Using the UI, ChatGPT’s results are a mix of code blocks and explanatory text. ChatGPT has a straightforward, clean, and functional web-based user interface. There is a button to copy the resulting code to your clipboard, and previous chat sessions are saved and accessible.
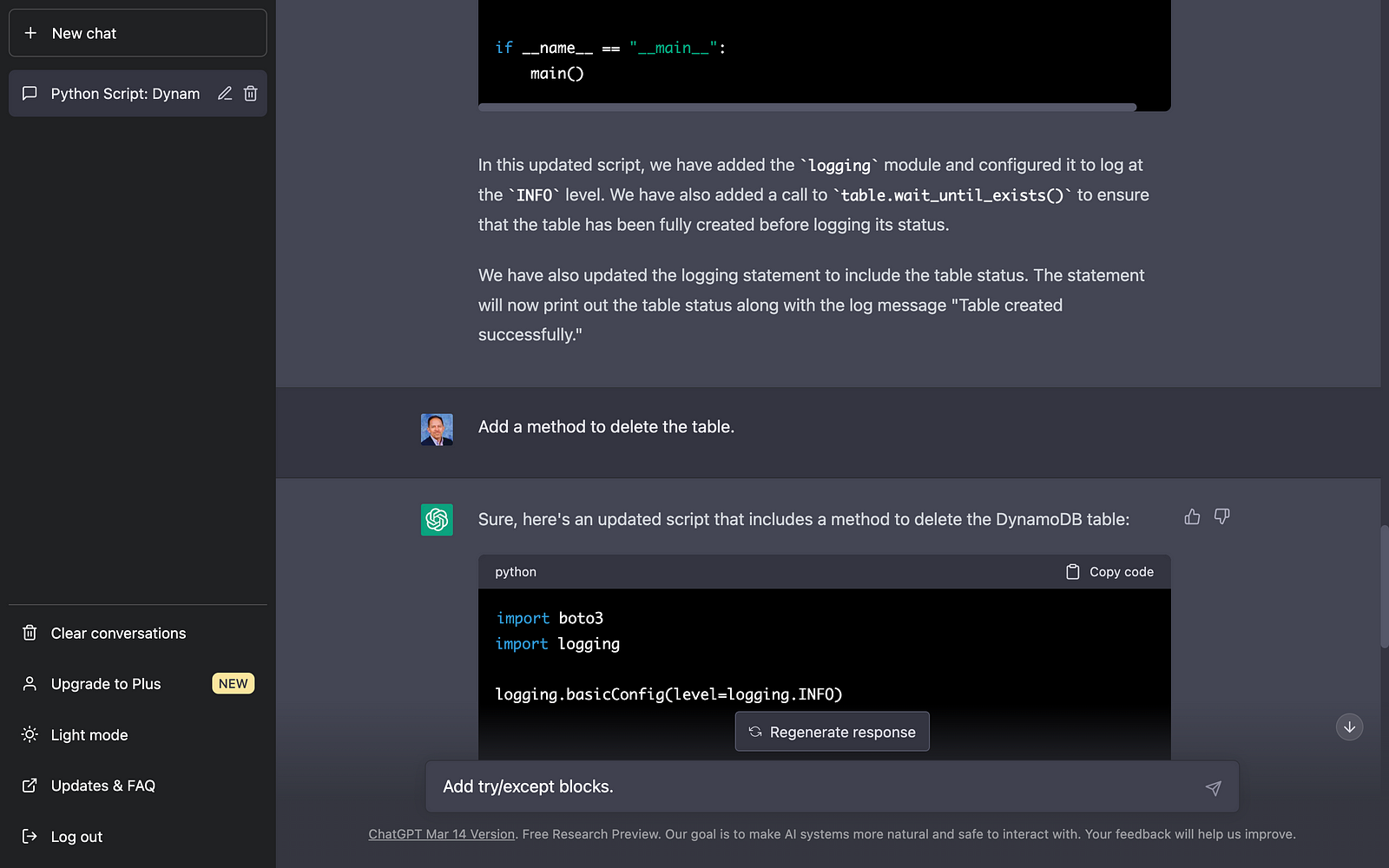
ChatGPT Results
In my tests, using a progressive chat approach to building the code with concise instructional questions versus a longer-form narrative approach produced better-quality code. The code created using a progressive chat approach was accurate, error-free, and well-written.
A significant advantage of ChatGPT is its ability to remember what happened earlier in the conversation. According to OpenAI documentation, the model can reference up to approximately 3k words (or 4k tokens) from the current conversation; any information beyond that is not stored.

Microsoft Bing Chat
According to their blog post on February 7, Microsoft launched “an all new, AI-powered Bing search engine and Edge browser, available in preview now at Bing.com, to deliver better search, more complete answers, a new chat experience and the ability to generate content. We think of these tools as an AI copilot for the web.” The latest version of Bing “is running on a new, next-generation OpenAI large language model that is more powerful than ChatGPT and customized specifically for search. It takes key learnings and advancements from ChatGPT and GPT-3.5 — and it is even faster, more accurate and more capable.” On March 14, Microsoft confirmed the new Bing runs on OpenAI’s latest GPT-4.
Getting Started with Bing Chat
Bing’s Chat mode is only available when you access Bing using Microsoft Edge.

Microsoft Edge is available for most major platforms, including MacOS, iOS, and Android.

Using Bing Chat
Bing Chat now supports up to 15 chats per session and 150 per day. Users can supply up to 15 prompts (questions or instructions) to create and improve the code results. When responding, Bing considers the context of previous prompts in the same chat session.

Bing Chat Results
Like OpenAI ChatGPT, Bing Chat delivered accurate, error-free, and well-written code. Although ChatGPT and Bing Chat are not IDE-based tools, the resulting code is easily copied into your project or saved to disk. Additionally, these tools provide an excellent opportunity to learn new languages and coding techniques without requiring an IDE.

ChatSonic

ChatSonic is a service of Writesonic. According to Y Combinator, startup Writesonic, founded by Samanyou Garg, is backed by leading venture capital firms, including Y Combinator, HOF Capital, Rebel Fund, Soma Capital, Broom Ventures, Amino Capital, and some of the best angels from different industries.
ChatSonic claims to improve upon the limitations of ChatGPT. According to Wordsonic, ChatSonic is “a powerful chatbot, powered by Google Search, allowing it to provide up-to-date and accurate content and hence superior to ChatGPT, which can not generate content on topics after September 2021. Additionally, it can create digital images and respond to voice commands and many more additional features. So, ChatSonic has addressed all the limitations of ChatGPT.”
Using ChatSonic
You can get started with ChatSonic for free, with up to 10,000 words. However, like OpenAI ChatGPT, if you want to take advantage of GPT-4, you will want to upgrade to a paid plan, starting at $13/month with an annual commitment.

Using ChatSonic is nearly identical to using OpenAI ChatGPT.

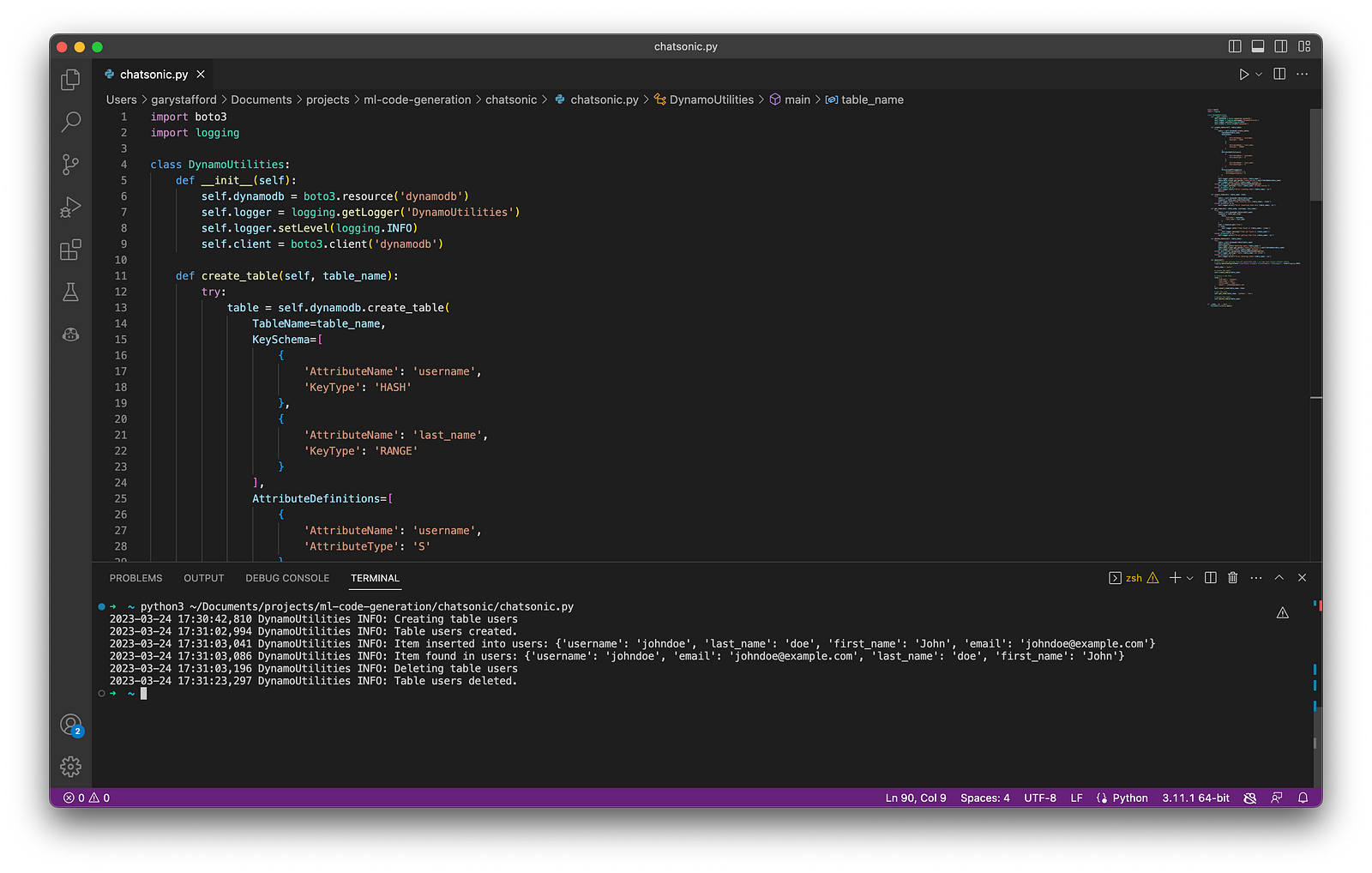
During my testing for this article, I ran into several issues with ChatSonic’s Premium Plan’s Free Trial. For example, the code block constantly flashed and refreshed on the screen using Chrome for Mac; a minor issue but highly annoying. Also, when copying or downloading code results, you get both code and the informational text, which you must separate. Worse, the final code block did not always include all the code output; the code was intermixed with informational text. Lastly, when using follow-up instructions to modify the results, the regenerated code often missed previous code modifications. In my tests, after several follow-up instructions, the resulting code was missing up to one-third of the previous statements. Due to these issues, the resulting code block was malformed and unrunnable. The more I chatted with ChatSonic, the worse the code issues became, and the issues were repeatable.


ChatSonic Results
Unlike ChatGPT and Bing Chat, ChatSonic’s Premium Plan’s Free Trial did not deliver accurate, error-free, or well-written code during my tests. Although later tests with fewer follow-up instructions provided better though incomplete results, my first impressions were unfavorable. The results might be improved using ChatSonic’s Superior or Ultimate Plans, which use the newest GPT-4 model. However, given the results of Premium, I was not keen to invest in the paid plan to find out.
Tabnine

According to the VC-backed, Israel-based startup Tabnine, “Tabnine is to create and deliver a top-to-bottom AI-assisted development workflow that empowers all code creators, in all languages, from concept through to completion.” Tabnine Pro serves whole-line, full-function, and natural language to code completions. Regarding AI, in Tabline’s opinion, “a multi-model approach far outperforms a monolithic approach. That’s why we’ve developed language-specific code native AI models, which are pre-trained on code and provide faster and more accurate code completions based on your tech stack.” To learn more about their models, read Tabnine’s blog post, Tabnine Enterprise vs. ChatGPT Plus.
Getting Started with Tabline
You can get started with Tabline for free with the Starter plan. However, the features of the Starter plan are limited compared to the Pro Plan, which starts at $12/month for a single user.

You can try out the Pro plan’s features, which are free for 14 days.

Tabnine supports a wide range of programming languages.
To get started with Tabline, choose your favorite IDE and install the required extensions or plugins.

Tabnine provides automated or manual IDE installation.

The Tabnine extension for VS Code already has a staggering 5.1 million downloads! A valuable tip learned from testing the IDE-based tools was to disable all non-essential extensions to give me a baseline of the tool’s capabilities. Initially, with over eighty VS Code extensions enabled, I found it hard to separate and understand each tool’s features and potential conflicts with other extensions I had loaded, especially other generative AI tools.

Using Tabnine
As discussed earlier, Tabnine, like GitHub Copilot and Amazon CodeWhisperer, uses generative AI technology to predict and suggest subsequent lines of code based on context and syntax within your IDE. It is like having IntelliSense on steroids.
Like Copilot and CodeWhisperer, it takes some practice to get efficient with Tabnine. After starting with the initial import and logging statements, I used code comments to generate the functions, then returned to add exception-catching and logging.
Tabnine, like Copilot and CodeWhisperer, includes a collapsible navigation bar. However, unlike those tools, I found Tabnine’s navigation bar provided little value, in my opinion. It seemed more like marketing stats and a way to encourage more users to sign-up rather than providing useful development features like Copilot and CodeWhisperer.
Below, we see an example of Tabnine Pro’s ability to generate whole-line code completion (line 11) and full-function code completion (lines 12–41) based on the existing code context and syntax (lines 1–11).
Tabnine Results
Given my development knowledge and experience with similar tools, I found the final code results with Tabnine Pro were accurate, error-free, and well-formed (Pythonic). However, I would have liked to see additional features to differentiate Tabnine from its competitors.

GitHub Copilot

According to GitHub, “Copilot is an AI pair programmer that offers autocomplete-style suggestions as you code. You can receive suggestions from GitHub Copilot either by starting to write the code you want to use or by writing a natural language comment describing what you want the code to do. In addition, GitHub Copilot analyzes the context in the file you are editing and related files, and offers suggestions from within your text editor.” Copilot is powered by OpenAI Codex, a new AI system created by OpenAI.
Given the vast popularity and volume of code on GitHub, it is no wonder Copilot is trained in all languages that appear in GitHub’s public repositories. GitHub points out that the quality of suggestions you receive may depend on the volume and diversity of training data for that language.
GitHub Copilot X
GitHub is extending Copilot’s capabilities, with the announcement of GitHub Copolit X on March 21, 2023. According to GitHub, “With chat and terminal interfaces, support for pull requests, and early adoption of OpenAI’s GPT-4, GitHub Copilot X is our vision for the future of AI-powered software development. Integrated into every part of your workflow.”
Getting Started with Copilot
Get started with GitHub Copilot for as little as $10/month. This Monthly Plan is a great way to test Copilot’s capabilities. In addition, GitHub is currently offering a 60-day free trial of Copilot.

Regarding IDE support, Copilot is currently available as an extension in Visual Studio Code, Visual Studio, Neovim, and the JetBrains suite of IDEs. The GitHub Copilot extension already has 4.2 million downloads, and the GitHub Copilot Nightly extension, used for this post, has almost 250,000 downloads.

GitHub Copilot can also be used with Codespaces, GitHub’s fully configured development environments in the Cloud based on VS Code, similar to AWS Cloud9.
Using Copilot
As discussed earlier, GitHub Copilot, like Tabnine and Amazon CodeWhisperer, uses generative AI technology to predict and suggest new lines of code based on existing context and syntax. In addition, Copilot includes an inline pop-up toolbar, which makes it easier to scroll through and accept code choices.
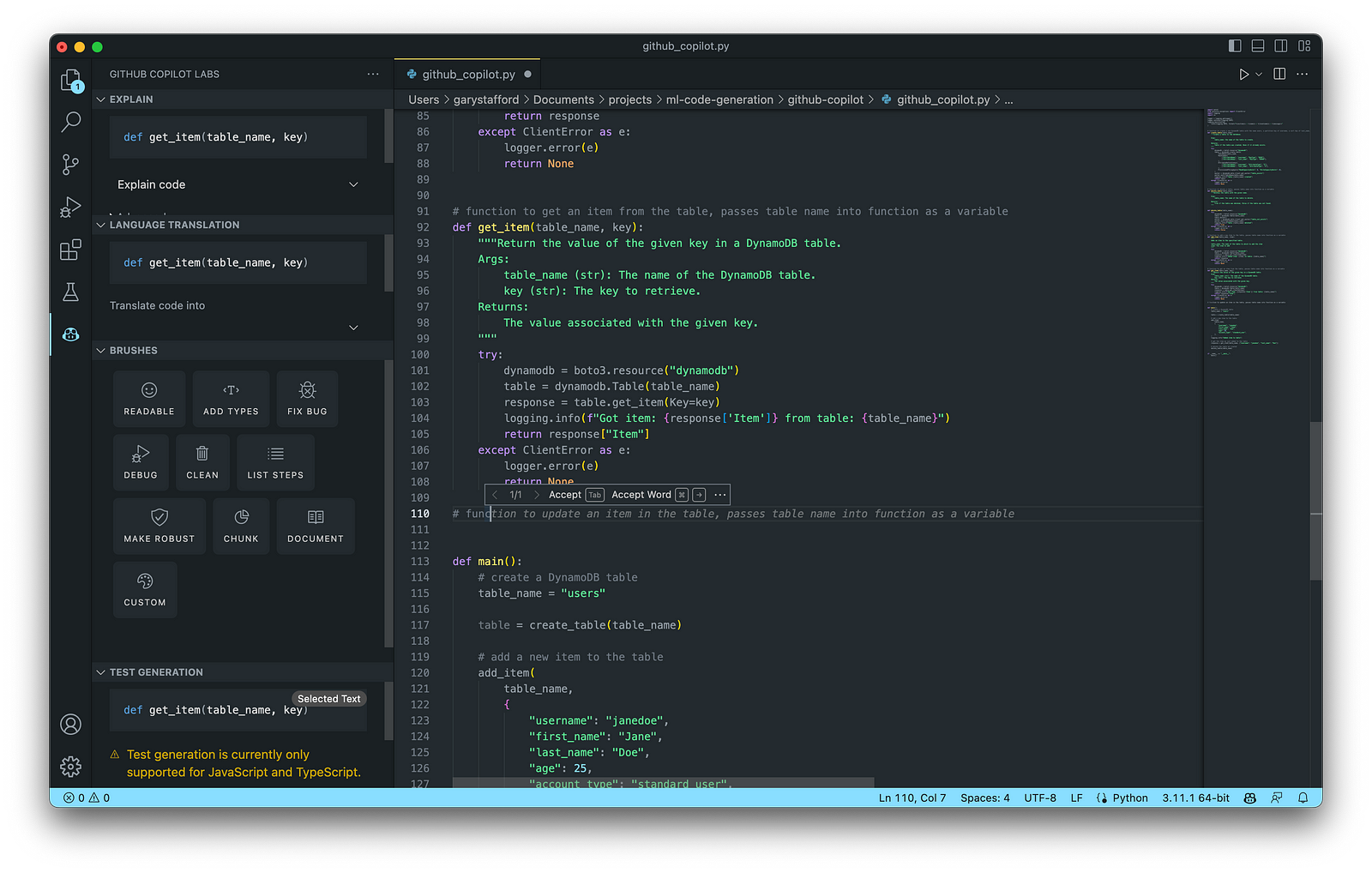
Copilot also has an extensive collapsible navigation bar, which can explain the code, offer language translations, provide access to Copilot’s Brushes, and can even generate tests. My only disappointment with Copilot is that test generation is currently only supported for JavaScript and TypeScript, given Python’s enormous popularity.

Below, we see an example of Copilot’s ability to generate whole-line code completion (line 14) and full-function code completion (lines 15–34) based on the existing code context and syntax (lines 1–14).

Copilot Results
Given my development knowledge and experience with similar tools, the final code results with Copilot were accurate, error-free, and well-formed. I found Copilot’s additional features, especially those found on its collapsible navigation bar, extended its functionality well beyond most similar generative AI tools I tested. Lastly, I felt Copilot’s ability to learn from the existing code context and syntax was superior to other tools.
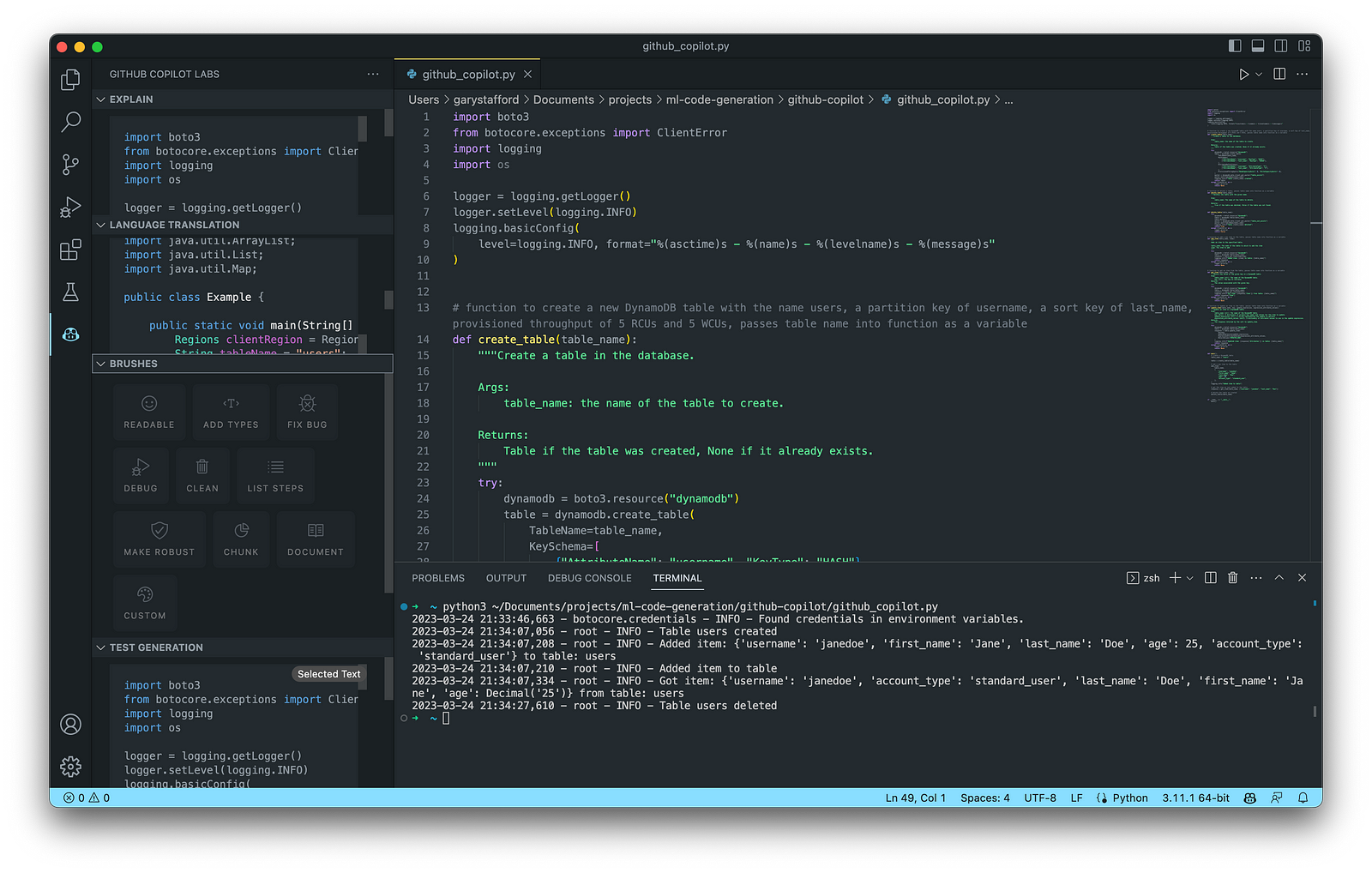
Amazon CodeWhisperer (Preview)

According to AWS, Amazon CodeWhisperer, announced in June 2022, “is a general purpose, machine learning-powered code generator that provides you with code recommendations, in real time. As you write code, CodeWhisperer automatically generates suggestions based on your existing code and comments. Your personalized recommendations can vary in size and scope, ranging from a single line comment to fully formed functions.” CodeWhisperer code generation is powered by ML models trained on various data sources, including Amazon and open-source code.
CodeWhisperer currently supports Java, JavaScript, Python, C#, and TypeScript. Although these are some of the most popular languages, CodeWhisperer’s language support is limited compared to Tabnine and Copilot.
Getting Started with CodeWhisperer
It is easy to get started with CodeWhisperer. Unfortunately, final pricing is unavailable since Amazon CodeWhisperer is still in Preview as of late March 2023.

CodeWhisperer enhances your IDE using AWS Toolkit for JetBrains, AWS Toolkit for Visual Studio Code, AWS Lambda console, and AWS Cloud9. With Lambda and AWS Cloud9, the setup simply involves activating CodeWhisperer within the IDE.

Getting started with CodeWhisperer requires installing the AWS Toolkit if applicable, choosing your authentication method, and setting up your Builder ID, IAM Identity Center (AWS SSO), or IAM.

AWS Builder ID
According to the documentation, “the AWS Builder ID is a new personal profile for everyone who builds on AWS. Your AWS Builder ID provides access to tools and builder services on AWS, including Amazon CodeCatalyst and Amazon CodeWhisperer. You can keep your AWS Builder ID as you move between jobs, schools, or other organizations. AWS Builder IDs are free. You only pay for the AWS resources you consume in your AWS accounts.”

Using CodeWhisperer
Nearly identical to Copilot and Tabnine, Amazon CodeWhisperer provides real-time code recommendations in your IDE. Unique features of CodeWhisperer include first-class support for AWS APIs, built-in security scans, a code reference tracker, and responsible AI/ML, which avoids bias by filtering out code recommendations that might be considered biased and unfair.
Below, we see an example of CodeWhisperer’s ability to generate whole-line code completion (line 14) and full-function code completion (lines 15–27) based on the existing code context and syntax (lines 1–14).

CodeWhisperer Results
Like my feedback on Tabnine and Copilot, the final code results with CodeWhisperer were accurate, error-free, and well-formed. In addition, I appreciated the added benefits of CodeWhisperer’s Security Scan and Reference Tracker to identify significant code from other projects.

Other Options
There are many other tools in the Generative AI coding category of comparable quality to the six featured in this post. New tools are being released on an almost daily basis.
Google Bard
On March 21, 2023, Google announced limited access to Bard, an early experiment that lets you collaborate with generative AI. They are beginning with the U.S. and the U.K. and will expand to more countries and languages over time. Bard is based on Google’s LaMDA (Language Model for Dialogue Applications), a transformer-based model.

Azure OpenAI Service with GPT-4
On March 21, 2023, Microsoft announced that GPT-4 was available in preview in Azure OpenAI Service. Unfortunately, Azure OpenAI Service requires registration and is currently only available to approved enterprise customers and partners. To get started, if you are qualified, you must trudge through the 25-question form.

Replit Ghostwriter
California-based VC-backed startup Replit has put the power of Replit’s AI into the world’s most popular online IDE. Replit “automates away the repetitive parts of coding, so you can stay focused on making your creative vision a reality.” Replit announced Ghostwriter Chat, which allows you to chat with a coding AI directly in your IDE. It now has a proactive debugger and awareness of your project’s code.
Conclusion
In this post, we examined six popular generative AI-powered coding tools, including chat-based OpenAI ChatGPT, Microsoft’s all-new Bing Chat, and ChatSonic, as well as IDE-based GitHub Copilot, Amazon CodeWhisperer (Preview), and Tabnine. Each tool assisted with developing an identical program to complete everyday database tasks on AWS. We then compared and contrasted the ease of use and the resulting code accuracy and quality of the tools. The generative AI space is moving at a breakneck pace. Tools continue to rapidly improve their AI models, add new features, and adjust pricing.
Recommended References
- Article: Top Artificial Intelligence (AI) Tools That Can Generate Code To Help Programmers (Marktechpost)
- Article: Top 29 ChatGPT alternatives that will blow your mind in 2023 (Free & Paid) (Writesonic)
- Research Paper: Deep Learning for Source Code Modeling and Generation: Models, Applications and Challenges (Triet H. M. Le, Hao Chen, M. Ali Babar)
- Article: NLP vs. NLU vs. NLG: the differences between three natural language processing concepts (IBM)
- Article: Top 17 Generative AI-based Programming Tools (For Developers) (Toward AI)
🔔 To keep up with future content, follow Gary Stafford on LinkedIn.
This blog represents my viewpoints and not those of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners.
Developing a Multi-Account AWS Environment Strategy
Posted by Gary A. Stafford in AWS, Cloud, DevOps, Enterprise Software Development, Technology Consulting on March 11, 2023
Explore twelve common patterns for developing an effective and efficient multi-account AWS environment strategy

Introduction
Every company is different: its organizational structure, the length of time it has existed, how fast it has grown, the industries it serves, its product and service diversity, public or private sector, and its geographic footprint. This uniqueness is reflected in how it organizes and manages its Cloud resources. Just as no two organizations are exactly alike, the structure of their AWS environments is rarely identical.
Some organizations successfully operate from a single AWS account, while others manage workloads spread across dozens or even hundreds of accounts. The volume and purpose of an organization’s AWS accounts are a result of multiple factors, including length of time spent on AWS, Cloud maturity, organizational structure and complexity, sectors, industries, and geographies served, product and service mix, compliance and regulatory requirements, and merger and acquisition activity.
“By design, all resources provisioned within an AWS account are logically isolated from resources provisioned in other AWS accounts, even within your own AWS Organizations.” (AWS)
Working with industry peers, the AWS community, and a wide variety of customers, one will observe common patterns for how organizations separate environments and workloads using AWS accounts. These patterns form an AWS multi-account strategy for operating securely and reliably in the Cloud at scale. The more planning an organization does in advance to develop a sound multi-account strategy, the less the burden that is required to manage changes as the organization grows over time.
The following post will explore twelve common patterns for effectively and efficiently organizing multiple AWS accounts. These patterns do not represent an either-or choice; they are designed to be purposefully combined to form a multi-account AWS environment strategy for your organization.
Patterns
- Pattern 1: Single “Uber” Account
- Pattern 2: Non-Prod/Prod Environments
- Pattern 3: Upper/Lower Environments
- Pattern 4: SDLC Environments
- Pattern 5: Major Workload Separation
- Pattern 6: Backup
- Pattern 7: Sandboxes
- Pattern 8: Centralized Management and Governance
- Pattern 9: Internal/External Environments
- Pattern 10: PCI DSS Workloads
- Pattern 11: Vendors and Contractors
- Pattern 12: Mergers and Acquisitions
Patterns 1–8 are progressively more mature multi-account strategies, while Patterns 9–12 represent special use cases for supplemental accounts.
Multi-Account Advantages
According to AWS’s whitepaper, Organizing Your AWS Environment Using Multiple Accounts, the benefits of using multiple AWS accounts include the following:
- Group workloads based on business purpose and ownership
- Apply distinct security controls by environment
- Constrain access to sensitive data (including compliance and regulation)
- Promote innovation and agility
- Limit the scope of impact from adverse events
- Support multiple IT operating models
- Manage costs (budgeting and cost attribution)
- Distribute AWS Service Quotas (fka limits) and API request rate limits
As we explore the patterns for organizing your AWS accounts, we will see how and to what degree each of these benefits is demonstrated by that particular pattern.
AWS Control Tower
Discussions about AWS multi-account environment strategies would not be complete without mentioning AWS Control Tower. According to the documentation, “AWS Control Tower offers a straightforward way to set up and govern an AWS multi-account environment, following prescriptive best practices.” AWS Control Tower includes Landing zone, described as “a well-architected, multi-account environment based on security and compliance best practices.”
AWS Control Tower is prescriptive in the Shared accounts it automatically creates within its AWS Organizations’ organizational units (OUs). Shared accounts created by AWS Control Tower include the Management, Log Archive, and Audit accounts. The previous standalone AWS service, AWS Landing Zone, maintained slightly different required accounts, including Shared Services, Log Archive, Security, and optional Network accounts. Although prescriptive, AWS Control Tower is also flexible and relatively unopinionated regarding the structure of Member accounts. Member accounts can be enrolled or unenrolled in AWS Control Tower.
You can decide whether or not to implement AWS Organizations or AWS Control Tower to set up and govern your AWS multi-account environment. Regardless, you will still need to determine how to reflect your organization’s unique structure and requirements in the purpose and quantity of the accounts you create within your AWS environment.
Common Multi-Account Patterns
While working with peers, community members, and a wide variety of customers, I regularly encounter the following twelve patterns for organizing AWS accounts. As noted earlier, these patterns do not represent an either-or choice; they are designed to be purposefully combined to form a multi-account AWS environment strategy for your organization.
Pattern 1: Single “Uber” Account
Organizations that effectively implement Pattern 1: Single “Uber” Account organize and separate environments and workloads at the sub-account level. They often use Amazon Virtual Private Cloud (Amazon VPC), an AWS account-level construct, to organize and separate environments and workloads. They may also use Subnets (VPC-level construct) or AWS Regions and Availability Zones to further organize and separate environments and workloads.
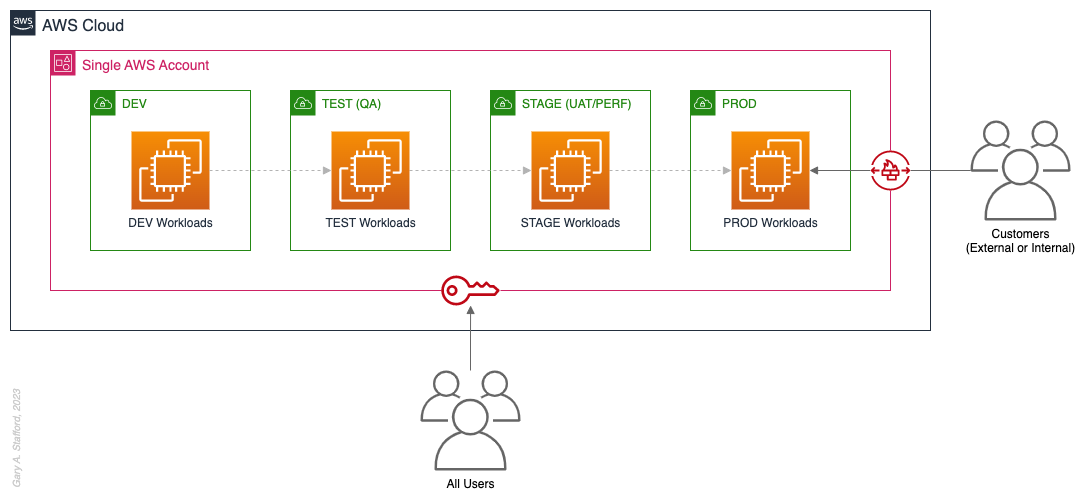
Pros
- Few, if any, significant advantages, especially for customer-facing workloads
Cons
- Decreased ability to limit the scope of impact from adverse events (widest blast radius)
- If the account is compromised, then all the organization’s workloads and data, possibly the entire organization, are potentially compromised (e.g., Ransomware attacks such as Encryptors, Lockers, and Doxware)
- Increased risk that networking or security misconfiguration could lead to unintended access to sensitive workloads and data
- Increased risk that networking, security, or resource management misconfiguration could lead to broad or unintended impairment of all workloads
- Decreased ability to perform team-, environment-, and workload-level budgeting and cost attribution
- Increased risk of resource depletion (soft and hard service quotas)
- Reduced ability to conduct audits and demonstrate compliance
Pattern 2: Non-Prod/Prod Environments
Organizations that effectively implement Pattern 2: Non-Prod/Prod Environments organize and separate non-Production workloads from Production (PROD) workloads using separate AWS accounts. Most often, they use Amazon VPCs within the non-Production account to separate workloads or Software Development Lifecycle (SDLC) environments, most often Development (DEV), Testing (TEST) or Quality Assurance (QA), and Staging (STAGE). Alternatively, these environments might also be designated as “N-1” (previous release), “N” (current release), “N+1” (next release), “N+2” (in development), and so forth, based on the currency of that version of that workload.
In some organizations, the Staging environment is used for User Acceptance Testing (UAT), performance (PERF) testing, and load testing before releasing workloads to Production. While in other organizations, STAGE, UAT, and PERF are each treated as separate environments at the account or VPC level.
Isolating Production workloads into their own account(s) and strictly limiting access to those workloads represents a significant first step in improving the overall maturity of your multi-account AWS environment strategy.
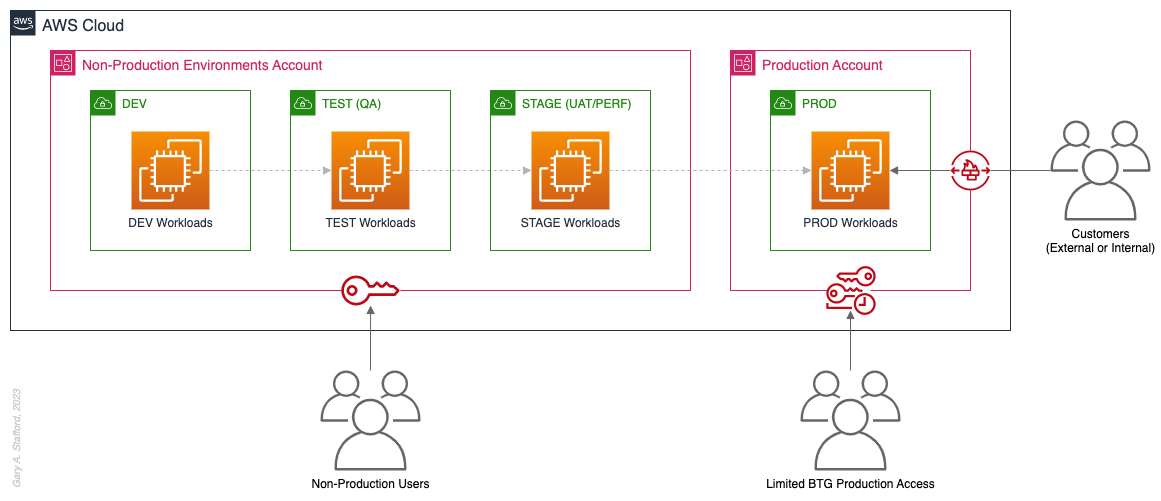
Pros
- Limits the scope of impact on Production as a result of adverse non-Production events (narrower blast radius)
- Logical separation and security of Production workloads and data
- Tightly control and limit access to Production, including the use of Break-the-Glass procedures (aka Break-glass or BTG); draws its name from “breaking the glass to pull a fire alarm”
- Eliminate the risk that non-Production networking or security misconfiguration could lead to unintended access to sensitive Production workloads and data
- Eliminate the chance that non-Production networking, security, or resource management misconfiguration could lead to broad or unintended impairment of Production workloads
- Conduct audits and demonstrate compliance with Production workloads
Cons
- If the Production account is compromised, then all the organization’s customer-facing workloads and data are potentially compromised
- Decreased ability to perform team-, environment-, and workload-level budgeting and cost attribution in the shared non-Production environment
- Increased risk of resource depletion (soft and hard service quotas) in the non-Production environment account
Pattern 3: Upper/Lower Environments
The next pattern, Pattern 3: Upper/Lower Environments, is a finer-grain variation of Pattern 2. With Pattern 3, we split all “Lower” environments into a single account and each “Upper” environment into its own account. In the software development process, initial environments, such as CI/CD for automated testing of code and infrastructure, Development, Test, UAT, and Performance, are called “Lower” environments. Conversely, later environments, such as Staging, Production, and even Disaster Recovery (DR), are called “Upper” environments. Upper environments typically require isolation for stability during testing or security for Production workloads and sensitive data.
Often, courser-grain patterns like Patterns 1–3 are carryovers from more traditional on-premises data centers, where compute, storage, network, and security resources were more constrained. Although these patterns can be successfully reproduced in the Cloud, they may not be optimal compared to more “cloud native” patterns, which provide improved separation of concerns.

Pros
- Limits the scope of impact on individual Upper environments as a result of adverse Lower environment events (narrower blast radius)
- Increased stability of Staging environment for critical UAT, performance, and load testing
- Logical separation and security of Production workloads and data
- Tightly control and limit access to Production, including the use of BTG
- Eliminate the risk that non-Production networking or security misconfiguration could lead to unintended access to sensitive Production workloads and data
- Eliminate the chance that non-Production networking, security, or resource management misconfiguration could lead to broad or unintended impairment of Production workloads
- Conduct audits and demonstrate compliance with Production workloads
Cons
- If the Production account is compromised, then all the organization’s customer-facing workloads and data are potentially compromised (e.g., Ransomware attack)
- Decreased ability to perform team-, environment-, and workload-level budgeting and cost attribution in the shared Lower environment
- Increased risk of resource depletion (soft and hard service quotas) in the Lower environment account
Pattern 4: SDLC Environments
The next pattern, Pattern 4: SDLC Environments, is a finer-grain variation of Pattern 3. With Pattern 4, we gain complete separation of each SDLC environment into its own AWS account. Using AWS services like AWS IAM Identity Center (fka AWS SSO), the Security team can enforce least-privilege permissions at an AWS Account level to individual groups of users, such as Developers, Testers, UAT, and Performance testers.
Based on my experience, Pattern 4 represents the minimal level of workload separation an organization should consider when developing its multi-account AWS environment strategy. Although Pattern 4 has a number of disadvantages, when combined with subsequent patterns and AWS best practices, this pattern begins to provide a scalable foundation for an organization’s growing workload portfolio.

Patterns, such as Pattern 4, not only apply to traditional software applications and services. These patterns can be applied to data analytics, AI/ML, IoT, media services, and similar workloads where separation of environments is required.

Pros
- Limits the scope of impact on one SDLC environment as a result of adverse events in another environment (narrower blast radius)
- Logical separation and security of Production workloads and data
- Increased stability of each SDLC environment
- Tightly control and limit access to Production, including the use of BTG
- Reduced risk that non-Production networking or security misconfiguration could lead to unintended access to sensitive Production workloads and data
- Reduced risk that non-Production networking, security, or resource management misconfiguration could lead to broad or unintended impairment of Production workloads
- Conduct audits and demonstrate compliance with Production workloads
- Increased ability to perform budgeting and cost attribution for each SDLC environment
- Reduced risk of resource depletion (soft and hard service limits) and IP conflicts and exhaustion within any single SDLC environment
Cons
- All workloads for each SDLC environment run within a single account, including Production, increasing the potential scope of impact from adverse events within that environment’s account
- If the Production account is compromised, then all the organization’s customer-facing workloads and data are potentially compromised
- Decreased ability to perform workload-level budgeting and cost attribution
Pattern 5: Major Workload Separation
The next pattern, Pattern 5: Major Workload Separation, is a finer-grain variation of Pattern 4. With Pattern 5, we separate each significant workload into its own separate SDLC environment account. The security team can enforce fine-grain least-privilege permissions at an AWS Account level to individual groups of users, such as Developers, Testers, UAT, and Performance testers, by their designated workload(s).
Pattern 5 has several advantages over the previous patterns. In addition to the increased workload-level security and reliability benefits, Pattern 5 can be particularly useful for organizations that operate significantly different technology stacks and specialized workloads, particularly at scale. Different technology stacks and specialized workloads often each have their own unique development, testing, deployment, and support processes. Isolating these types of workloads will help facilitate the support of multiple IT operating models.

Pros
- Limits the scope of impact on an individual workload as a result of adverse events from another workload or SDLC environment (narrowest blast radius)
- Increased ability to perform team-, environment-, and workload-level budgeting and cost attribution
Cons
- If the Production account is compromised, then all the organization’s customer-facing workloads and data are potentially compromised (e.g., Ransomware attack)
Pattern 6: Backup
In the earlier patterns, we mentioned that if the Production account were compromised, all the organization’s customer-facing workloads and data could be compromised. According to TechTarget, 2022 was a breakout year for Ransomware attacks. According to the US government’s CISA.gov website, “Ransomware is a form of malware designed to encrypt files on a device, rendering any files and the systems that rely on them unusable. Malicious actors then demand ransom in exchange for decryption.”
According to AWS best practices, one of the recommended preparatory actions to protect and recover from Ransomware attacks is backing up data to an alternate account using tools such as AWS Backup and an AWS Backup vault. Solutions such as AWS Backup protect and restore data regardless of how it was made inaccessible.
In Pattern 6: Backup, we create one or more Backup accounts to protect against unintended data loss or account compromise. In the example below, we have two Backup accounts, one for Production data and one for all non-Production data.

Pros
- If the Production account is compromised (e.g., Ransomware attacks such as Encryptors, Lockers, and Doxware), there are secure backups of data stored in a separate account, which can be used to restore or recreate the Production environment
Cons
- Few, if any, significant disadvantages when combined with previous patterns and AWS best-practices
Pattern 7: Sandboxes
The following pattern, Pattern 7: Sandboxes, supplements the previous patterns, designed to address the needs of an organization to allow individual users and teams to learn, build, experiment, and innovate on AWS without impacting the larger organization’s AWS environment. To quote the AWS blog, Best practices for creating and managing sandbox accounts in AWS, “Many organizations need another type of environment, one where users can build and innovate with AWS services that might not be permitted in production or development/test environments because controls have not yet been implemented.” Further, according to TechTarget, “a Sandbox is an isolated testing environment that enables users to run programs or open files without affecting the application, system, or platform on which they run.”
Due to the potential volume of individual user and team accounts, sometimes referred to as Sandbox accounts, mature infrastructure automation practices, cost controls, and self-service provisioning and de-provisioning of Sandbox accounts are critical capabilities for the organization.
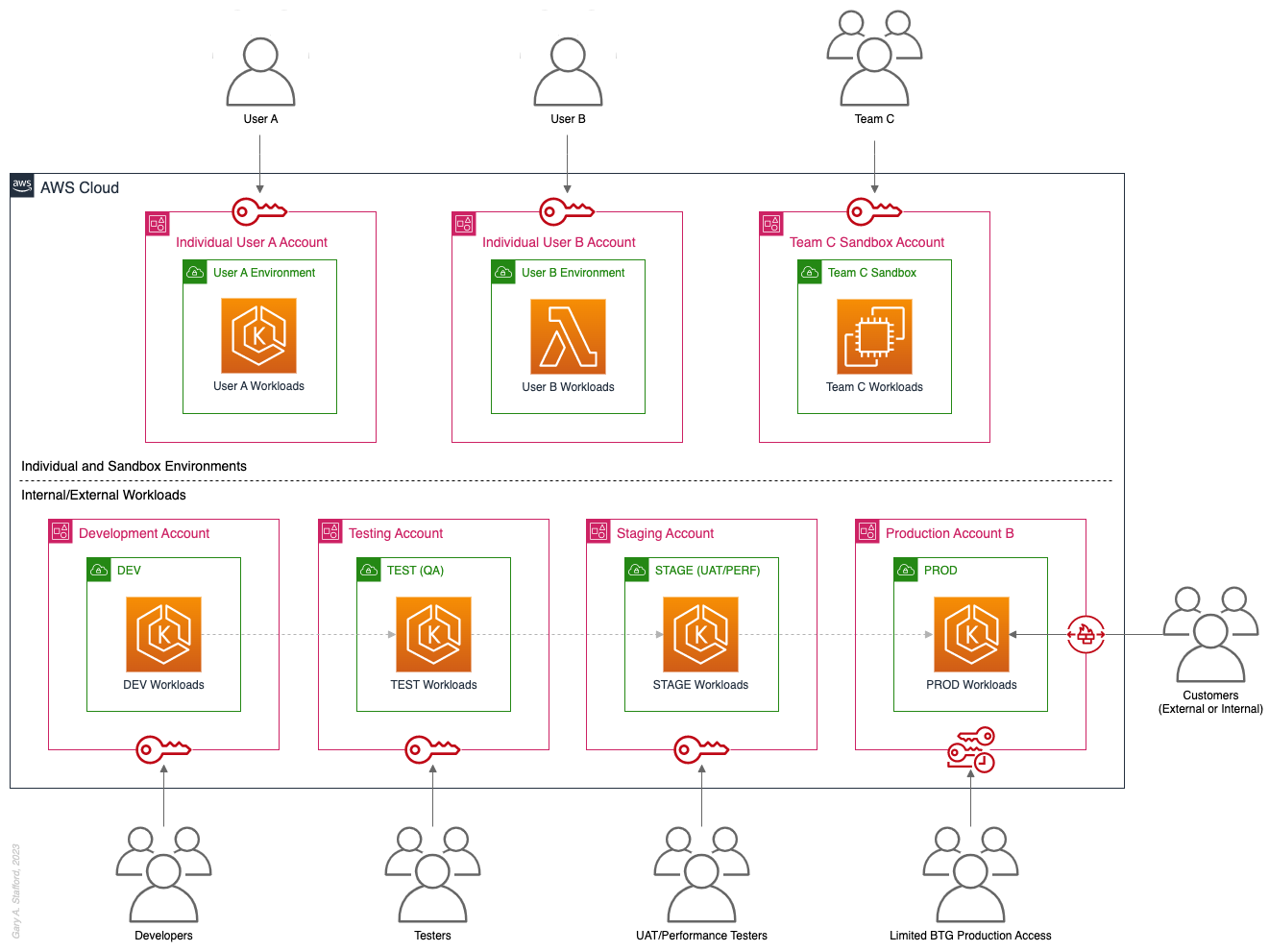
Pros
- Allow individual users and teams to learn, build, experiment, and innovate on AWS without impacting the rest of the organization’s AWS environment
Cons
- Without mature automation practices, cost controls, and self-service capabilities, managing multiple individual and team Sandbox accounts can become unwieldy and costly
Pattern 8: Centralized Management and Governance
We discussed AWS Control Tower at the beginning of this post. AWS Control Tower is prescriptive in creating Shared accounts within its AWS Organizations’ organizational units (OUs), including the Management, Log Archive, and Audit accounts. AWS encourages using AWS Control Tower to orchestrate multiple AWS accounts and services on your behalf while maintaining your organization’s security and compliance needs.
As exemplified in Pattern 8: Centralized Management and Governance, many organizations will implement centralized management whether or not they decide to implement AWS Control Tower. In addition to the Management account (payer account, fka master account), organizations often create centralized logging accounts, and centralized tooling (aka Shared services) accounts for functions such as CI/CD, IaC provisioning, and deployment. Another common centralized management account is a Security account. Organizations use this account to centralize the monitoring, analysis, notification, and automated mitigation of potential security issues within their AWS environment. The Security accounts will include services such as Amazon Detective, Amazon Inspector, Amazon GuardDuty, and AWS Security Hub.

Pros
- Increased ability to manage and maintain multiple AWS accounts with fewer resources
- Reduced duplication of management resources across accounts
- Increased ability to use automation and improve the consistency of processes and procedures across multiple accounts
Cons
- Few, if any, significant disadvantages when combined with previous patterns and AWS best-practices
Pattern 9: Internal/External Environments
The next pattern, Pattern 9: Internal/External Environments, focuses on organizations with internal operational systems (aka Enterprise systems) in the Cloud and customer-facing workloads. Pattern 9 separates internal operational systems, platforms, and workloads from external customer-facing workloads. For example, an organization’s divisions and departments, such as Sales and Marketing, Finance, Human Resources, and Manufacturing, are assigned their own AWS account(s). Pattern 9 allows the Security team to ensure that internal departmental or divisional users are isolated from users who are responsible for developing, testing, deploying, and managing customer-facing workloads.
Note that the diagram for Pattern 9 shows remote users who access AWS End User Computing (EUC) services or Virtual Desktop Infrastructure (VDI), such as Amazon WorkSpaces and Amazon AppStream 2.0. In this example, remote workers have secure access to EUC services provisioned in a separate AWS account, and indirectly, internal systems, platforms, and workloads.

Pros
- Separation of internal operational systems, platforms, and workloads from external customer-facing workloads
Cons
- Few, if any, significant disadvantages when combined with previous patterns and AWS best-practices
Pattern 10: PCI DSS Workloads
The next pattern, Pattern 10: PCI DSS Workloads, is a variation of previous patterns, which assumes the existence of Payment Card Industry Data Security Standard (PCI DSS) workloads and data. According to the AWS, “PCI DSS applies to entities that store, process, or transmit cardholder data (CHD) or sensitive authentication data (SAD), including merchants, processors, acquirers, issuers, and service providers. The PCI DSS is mandated by the card brands and administered by the Payment Card Industry Security Standards Council.”
According to AWS’s whitepaper, Architecting for PCI DSS Scoping and Segmentation on AWS, “By design, all resources provisioned within an AWS account are logically isolated from resources provisioned in other AWS accounts, even within your own AWS Organizations. Using an isolated account for PCI workloads is a core best practice when designing your PCI application to run on AWS.” With Pattern 10, we separate non-PCI DSS and PCI DSS Production workloads and data. The assumption is that only Production contains PCI DSS data. Data in lower environments is synthetically generated or sufficiently encrypted, masked, obfuscated, or tokenized.
Note that the diagram for Pattern 10 shows Administrators. Administrators with different spans of responsibility and access are present in every pattern, whether specifically shown or not.

Pros
- Increased ability to meet compliance requirements by separating non-PCI DSS and PCI DSS Production workloads
Cons
- Few, if any, significant disadvantages when combined with previous patterns and AWS best-practices
Pattern 11: Vendors and Contractors
The next pattern, Pattern 11: Vendors and Contractors, is focused on organizations that employ contractors or use third-party vendors who provide products and services that interact with their AWS-based environment. Like Pattern 10, Pattern 11 allows the Security team to ensure that contractor and vendor-based systems’ access to internal systems and customer-facing workloads is tightly controlled and auditable.
Vendor-based products and services are often deployed within an organization’s AWS environment without external means of ingress or egress. Alternatively, a vendor’s product or service may have a secure means of ingress from or egress to external endpoints. Such is the case with some SaaS products, which ship an organization’s data to an external aggregator for analytics or a security vendor’s product that pre-filters incoming data, external to the organization’s AWS environment. Using separate AWS accounts can improve an organization’s security posture and mitigate the risk of adverse events on the organization’s overall AWS environment.

Pros
- Ensure access to internal systems and customer-facing workloads by contractors and vendor-based systems is tightly controlled and auditable
Cons
- Few, if any, significant disadvantages when combined with previous patterns and AWS best-practices
Pattern 12: Mergers and Acquisitions
The next pattern, Pattern 12: Mergers and Acquisitions, is focused on managing the integration of external AWS accounts as a result of a merger or acquisition. This is a common occurrence, but the exact details of how best to handle the integration of two or more integrations depend on several factors. Factors include the required level of integration, for example, maintaining separate AWS Organizations, maintaining different AWS accounts, or merging resources from multiple accounts. Other factors that might impact account structure include changes in ownership or payer of acquired accounts, existing acquired cost-savings agreements (e.g., EDPs, PPAs, RIs, and Savings Plans), and AWS Marketplace vendor agreements. Even existing authentication and authorization methods of the acquiree versus the acquirer (e.g., AWS IAM Identity Center, Microsoft Active Directory (AD), Azure AD, and external identity providers (IdP) like Okta or Auth0).
The diagram for Pattern 12 attempts to show a few different M&A account scenarios, including maintaining separate AWS accounts for the acquirer and acquiree (e.g., acquiree’s Manufacturing Division account). If desired, the accounts can be kept independent but managed within the acquirer’s AWS Organizations’ organization. The diagram also exhibits merging resources from the acquiree’s accounts into the acquirer’s accounts (e.g., Sales and Marketing accounts). Resources will be migrated or decommissioned, and the account will be closed.

Pros
- Maintain separation between an acquirer and an acquiree’s AWS accounts within a single organization’s AWS environment
- Potentially consolidate and maximize cost-saving advantages of volume-related financial agreements and vendor licensing
Cons
- Migrating workloads between different organizations, depending on their complexity, requires careful planning and testing
- Consolidating multiple authentication and authorization methods requires careful planning and testing to avoid improper privileges
- Consolidating and optimizing separate licensing and cost-saving agreements between multiple organizations requires careful planning and an in-depth understanding of those agreements
Multi-Account AWS Environment Example
You can form an efficient and effective multi-account strategy for your organization by purposefully combining multiple patterns. Below is an example of combining the features of several patterns: Major Workload Separation, Backup, Sandboxes, Centralized Management and Governance, Internal/External Environments, and Vendors and Contractors.
According to AWS, “You can use AWS Organizations’ organizational units (OUs) to group accounts together to administer as a single unit. This greatly simplifies the management of your accounts.” If you decide to use AWS Organizations, each set of accounts associated with a pattern could correspond to an OU: Major Workload A, Major Workload B, Sandboxes, Backups, Centralized Management, Internal Environments, Vendors, and Contractors.

Conclusion
This post taught us twelve common patterns for effectively and efficiently organizing your AWS accounts. Instead of an either-or choice, these patterns are designed to be purposefully combined to form a multi-account strategy for your organization. Having a sound multi-account strategy will improve your security posture, maintain compliance, decrease the impact of adverse events on your AWS environment, and improve your organization’s ability to safely and confidently innovate and experiment on AWS.
Recommended References
- Establishing Your Cloud Foundation on AWS (AWS Whitepaper)
- Organizing Your AWS Environment Using Multiple Accounts (AWS Whitepaper)
- Building a Cloud Operating Model (AWS Whitepaper)
- AWS Security Reference Architecture (AWS Prescriptive Guidance)
- AWS Security Maturity Model (AWS Whitepaper)
- AWS re:Invent 2022 — Best practices for organizing and operating on AWS (YouTube Video)
- AWS Break Glass Role (GitHub)
🔔 To keep up with future content, follow Gary Stafford on LinkedIn.
This blog represents my viewpoints and not those of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners.
Exploring Popular Open-source Stream Processing Technologies: Part 2 of 2
Posted by Gary A. Stafford in Analytics, Big Data, Java Development, Python, Software Development, SQL on September 26, 2022
A brief demonstration of Apache Spark Structured Streaming, Apache Kafka Streams, Apache Flink, and Apache Pinot with Apache Superset
Introduction
According to TechTarget, “Stream processing is a data management technique that involves ingesting a continuous data stream to quickly analyze, filter, transform or enhance the data in real-time. Once processed, the data is passed off to an application, data store, or another stream processing engine.” Confluent, a fully-managed Apache Kafka market leader, defines stream processing as “a software paradigm that ingests, processes, and manages continuous streams of data while they’re still in motion.”
This two-part post series and forthcoming video explore four popular open-source software (OSS) stream processing projects: Apache Spark Structured Streaming, Apache Kafka Streams, Apache Flink, and Apache Pinot.

This post uses the open-source projects, making it easier to follow along with the demonstration and keeping costs to a minimum. However, you could easily substitute the open-source projects for your preferred SaaS, CSP, or COSS service offerings.
Part Two
We will continue our exploration in part two of this two-part post, covering Apache Flink and Apache Pinot. In addition, we will incorporate Apache Superset into the demonstration to visualize the real-time results of our stream processing pipelines as a dashboard.
Demonstration #3: Apache Flink
In the third demonstration of four, we will examine Apache Flink. For this part of the post, we will also use the third of the three GitHub repository projects, flink-kafka-demo. The project contains a Flink application written in Java, which performs stream processing, incremental aggregation, and multi-stream joins.

New Streaming Stack
To get started, we need to replace the first streaming Docker Swarm stack, deployed in part one, with the second streaming Docker Swarm stack. The second stack contains Apache Kafka, Apache Zookeeper, Apache Flink, Apache Pinot, Apache Superset, UI for Apache Kafka, and Project Jupyter (JupyterLab).
https://programmaticponderings.wordpress.com/media/601efca17604c3a467a4200e93d7d3ff
The stack will take a few minutes to deploy fully. When complete, there should be ten containers running in the stack.
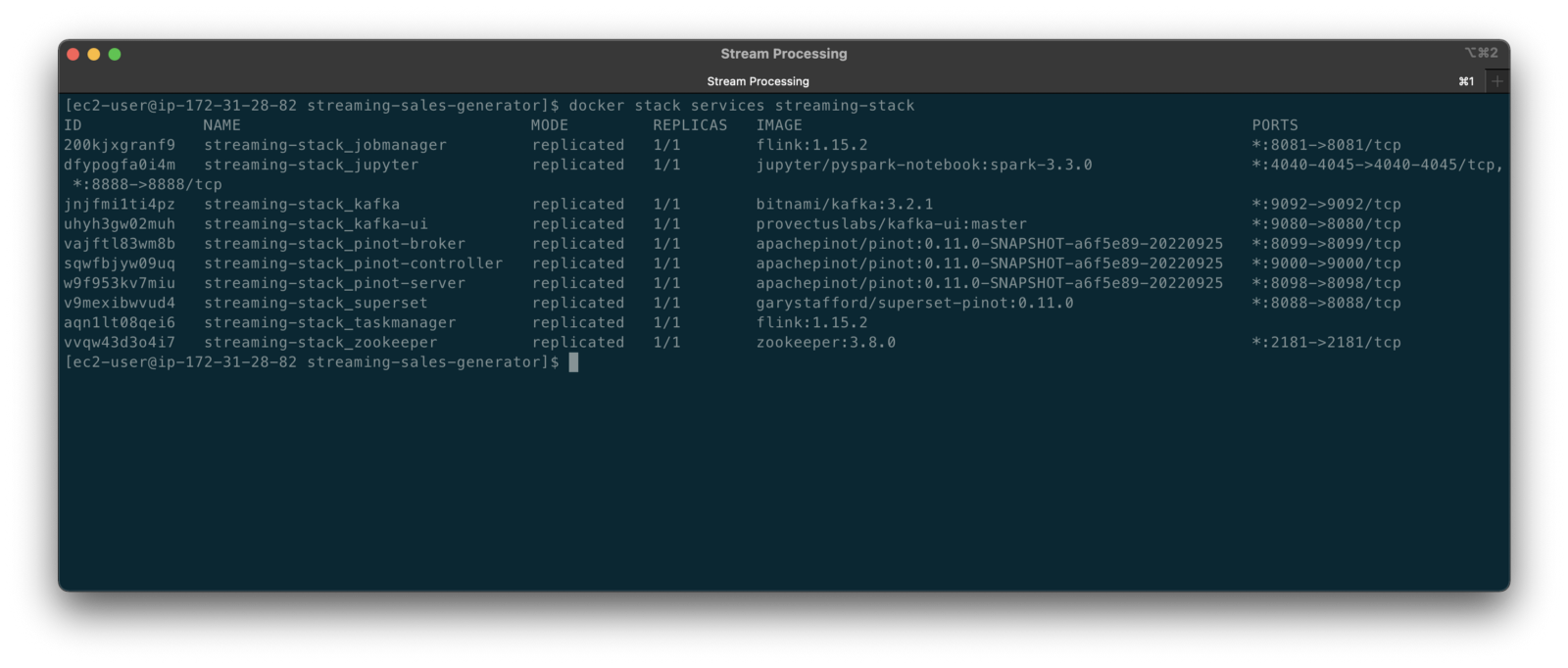
Flink Application
The Flink application has two entry classes. The first class, RunningTotals, performs an identical aggregation function as the previous KStreams demo.
The second class, JoinStreams, joins the stream of data from the demo.purchases topic and the demo.products topic, processing and combining them, in real-time, into an enriched transaction and publishing the results to a new topic, demo.purchases.enriched.
The resulting enriched purchases messages look similar to the following:
Running the Flink Job
To run the Flink application, we must first compile it into an uber JAR.
We can copy the JAR into the Flink container or upload it through the Apache Flink Dashboard, a browser-based UI. For this demonstration, we will upload it through the Apache Flink Dashboard, accessible on port 8081.
The project’s build.gradle file has preset the Main class (Flink’s Entry class) to org.example.JoinStreams. Optionally, to run the Running Totals demo, we could change the build.gradle file and recompile, or simply change Flink’s Entry class to org.example.RunningTotals.

Before running the Flink job, restart the sales generator in the background (nohup python3 ./producer.py &) to generate a new stream of data. Then start the Flink job.

To confirm the Flink application is running, we can check the contents of the new demo.purchases.enriched topic using the Kafka CLI.

Alternatively, you can use the UI for Apache Kafka, accessible on port 9080.

Demonstration #4: Apache Pinot
In the fourth and final demonstration, we will explore Apache Pinot. First, we will query the unbounded data streams from Apache Kafka, generated by both the sales generator and the Apache Flink application, using SQL. Then, we build a real-time dashboard in Apache Superset, with Apache Pinot as our datasource.

Creating Tables
According to the Apache Pinot documentation, “a table is a logical abstraction that represents a collection of related data. It is composed of columns and rows (known as documents in Pinot).” There are three types of Pinot tables: Offline, Realtime, and Hybrid. For this demonstration, we will create three Realtime tables. Realtime tables ingest data from streams — in our case, Kafka — and build segments from the consumed data. Further, according to the documentation, “each table in Pinot is associated with a Schema. A schema defines what fields are present in the table along with the data types. The schema is stored in Zookeeper, along with the table configuration.”
Below, we see the schema and config for one of the three Realtime tables, purchasesEnriched. Note how the columns are divided into three categories: Dimension, Metric, and DateTime.
To begin, copy the three Pinot Realtime table schemas and configurations from the streaming-sales-generator GitHub project into the Apache Pinot Controller container. Next, use a docker exec command to call the Pinot Command Line Interface’s (CLI) AddTable command to create the three tables: products, purchases, and purchasesEnriched.
To confirm the three tables were created correctly, use the Apache Pinot Data Explorer accessible on port 9000. Use the Tables tab in the Cluster Manager.

We can further inspect and edit the table’s config and schema from the Tables tab in the Cluster Manager.

The three tables are configured to read the unbounded stream of data from the corresponding Kafka topics: demo.products, demo.purchases, and demo.purchases.enriched.
Querying with Pinot
We can use Pinot’s Query Console to query the Realtime tables using SQL. According to the documentation, “Pinot provides a SQL interface for querying. It uses the [Apache] Calcite SQL parser to parse queries and uses MYSQL_ANSI dialect.”

With the generator still running, re-query the purchases table in the Query Console (select count(*) from purchases). You should notice the document count increasing each time you re-run the query since new messages are published to the demo.purchases topic by the sales generator.
If you do not observe the count increasing, ensure the sales generator and Flink enrichment job are running.

Table Joins?
It might seem logical to want to replicate the same multi-stream join we performed with Apache Flink in part three of the demonstration on the demo.products and demo.purchases topics. Further, we might presume to join the products and purchases realtime tables by writing a SQL statement in Pinot’s Query Console. However, according to the documentation, at the time of this post, version 0.11.0 of Pinot did not [currently] support joins or nested subqueries.
This current join limitation is why we created the Realtime table, purchasesEnriched, allowing us to query Flink’s real-time results in the demo.purchases.enriched topic. We will use both Flink and Pinot as part of our stream processing pipeline, taking advantage of each tool’s individual strengths and capabilities.
Note, according to the documentation for the latest release of Pinot on the main branch, “the latest Pinot multi-stage supports inner join, left-outer, semi-join, and nested queries out of the box. It is optimized for in-memory process and latency.” For more information on joins as part of Pinot’s new multi-stage query execution engine, read the documentation, Multi-Stage Query Engine.

demo.purchases.enriched topic in real-timeAggregations
We can perform real-time aggregations using Pinot’s rich SQL query interface. For example, like previously with Spark and Flink, we can calculate running totals for the number of items sold and the total sales for each product in real time.

We can do the same with the purchasesEnriched table, which will use the continuous stream of enriched transaction data from our Apache Flink application. With the purchasesEnriched table, we can add the product name and product category for richer results. Each time we run the query, we get real-time results based on the running sales generator and Flink enrichment job.

Query Options and Indexing
Note the reference to the Star-Tree index at the start of the SQL query shown above. Pinot provides several query options, including useStarTree (true by default).
Multiple indexing techniques are available in Pinot, including Forward Index, Inverted Index, Star-tree Index, Bloom Filter, and Range Index, among others. Each has advantages in different query scenarios. According to the documentation, by default, Pinot creates a dictionary-encoded forward index for each column.
SQL Examples
Here are a few examples of SQL queries you can try in Pinot’s Query Console:
Troubleshooting Pinot
If have issues with creating the tables or querying the real-time data, you can start by reviewing the Apache Pinot logs:
Real-time Dashboards with Apache Superset
To display the real-time stream of data produced results of our Apache Flink stream processing job and made queriable by Apache Pinot, we can use Apache Superset. Superset positions itself as “a modern data exploration and visualization platform.” Superset allows users “to explore and visualize their data, from simple line charts to highly detailed geospatial charts.”
According to the documentation, “Superset requires a Python DB-API database driver and a SQLAlchemy dialect to be installed for each datastore you want to connect to.” In the case of Apache Pinot, we can use pinotdb as the Python DB-API and SQLAlchemy dialect for Pinot. Since the existing Superset Docker container does not have pinotdb installed, I have built and published a Docker Image with the driver and deployed it as part of the second streaming stack of containers.
First, we much configure the Superset container instance. These instructions are documented as part of the Superset Docker Image repository.
Once the configuration is complete, we can log into the Superset web-browser-based UI accessible on port 8088.
Pinot Database Connection and Dataset
Next, to connect to Pinot from Superset, we need to create a Database Connection and a Dataset.
The SQLAlchemy URI is shown below. Input the URI, test your connection (‘Test Connection’), make sure it succeeds, then hit ‘Connect’.
Next, create a Dataset that references the purchasesEnriched Pinot table.

purchasesEnriched Pinot tableModify the dataset’s transaction_time column. Check the is_temporal and Default datetime options. Lastly, define the DateTime format as epoch_ms.
transaction_time columnBuilding a Real-time Dashboard
Using the new dataset, which connects Superset to the purchasesEnriched Pinot table, we can construct individual charts to be placed on a dashboard. Build a few charts to include on your dashboard.
Create a new Superset dashboard and add the charts and other elements, such as headlines, dividers, and tabs.

We can apply a refresh interval to the dashboard to continuously query Pinot and visualize the results in near real-time.
Conclusion
In this two-part post series, we were introduced to stream processing. We explored four popular open-source stream processing projects: Apache Spark Structured Streaming, Apache Kafka Streams, Apache Flink, and Apache Pinot. Next, we learned how we could solve similar stream processing and streaming analytics challenges using different streaming technologies. Lastly, we saw how these technologies, such as Kafka, Flink, Pinot, and Superset, could be integrated to create effective stream processing pipelines.
This blog represents my viewpoints and not of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners. All diagrams and illustrations are the property of the author unless otherwise noted.
Exploring Popular Open-source Stream Processing Technologies: Part 1 of 2
Posted by Gary A. Stafford in Analytics, Big Data, Java Development, Python, Software Development, SQL on September 24, 2022
A brief demonstration of Apache Spark Structured Streaming, Apache Kafka Streams, Apache Flink, and Apache Pinot with Apache Superset
Introduction
According to TechTarget, “Stream processing is a data management technique that involves ingesting a continuous data stream to quickly analyze, filter, transform or enhance the data in real-time. Once processed, the data is passed off to an application, data store, or another stream processing engine.” Confluent, a fully-managed Apache Kafka market leader, defines stream processing as “a software paradigm that ingests, processes, and manages continuous streams of data while they’re still in motion.”
Batch vs. Stream Processing
Again, according to Confluent, “Batch processing is when the processing and analysis happens on a set of data that have already been stored over a period of time.” A batch processing example might include daily retail sales data, which is aggregated and tabulated nightly after the stores close. Conversely, “streaming data processing happens as the data flows through a system. This results in analysis and reporting of events as it happens.” To use a similar example, instead of nightly batch processing, the streams of sales data are processed, aggregated, and analyzed continuously throughout the day — sales volume, buying trends, inventory levels, and marketing program performance are tracked in real time.
Bounded vs. Unbounded Data
According to Packt Publishing’s book, Learning Apache Apex, “bounded data is finite; it has a beginning and an end. Unbounded data is an ever-growing, essentially infinite data set.” Batch processing is typically performed on bounded data, whereas stream processing is most often performed on unbounded data.
Stream Processing Technologies
There are many technologies available to perform stream processing. These include proprietary custom software, commercial off-the-shelf (COTS) software, fully-managed service offerings from Software as a Service (or SaaS) providers, Cloud Solution Providers (CSP), Commercial Open Source Software (COSS) companies, and popular open-source projects from the Apache Software Foundation and Linux Foundation.
The following two-part post and forthcoming video will explore four popular open-source software (OSS) stream processing projects, including Apache Spark Structured Streaming, Apache Kafka Streams, Apache Flink, and Apache Pinot. Each of these projects has some equivalent SaaS, CSP, and COSS offerings.
This post uses the open-source projects, making it easier to follow along with the demonstration and keeping costs to a minimum. However, you could easily substitute the open-source projects for your preferred SaaS, CSP, or COSS service offerings.
Apache Spark Structured Streaming
According to the Apache Spark documentation, “Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data.” Further, “Structured Streaming queries are processed using a micro-batch processing engine, which processes data streams as a series of small batch jobs thereby achieving end-to-end latencies as low as 100 milliseconds and exactly-once fault-tolerance guarantees.” In the post, we will examine both batch and stream processing using a series of Apache Spark Structured Streaming jobs written in PySpark.

Apache Kafka Streams
According to the Apache Kafka documentation, “Kafka Streams [aka KStreams] is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka’s server-side cluster technology.” In the post, we will examine a KStreams application written in Java that performs stream processing and incremental aggregation.

Apache Flink
According to the Apache Flink documentation, “Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.” Further, “Apache Flink excels at processing unbounded and bounded data sets. Precise control of time and state enables Flink’s runtime to run any kind of application on unbounded streams. Bounded streams are internally processed by algorithms and data structures that are specifically designed for fixed-sized data sets, yielding excellent performance.” In the post, we will examine a Flink application written in Java, which performs stream processing, incremental aggregation, and multi-stream joins.

Apache Pinot
According to Apache Pinot’s documentation, “Pinot is a real-time distributed OLAP datastore, purpose-built to provide ultra-low-latency analytics, even at extremely high throughput. It can ingest directly from streaming data sources — such as Apache Kafka and Amazon Kinesis — and make the events available for querying instantly. It can also ingest from batch data sources such as Hadoop HDFS, Amazon S3, Azure ADLS, and Google Cloud Storage.” In the post, we will query the unbounded data streams from Apache Kafka, generated by Apache Flink, using SQL.

Streaming Data Source
We must first find a good unbounded data source to explore or demonstrate these streaming technologies. Ideally, the streaming data source should be complex enough to allow multiple types of analyses and visualize different aspects with Business Intelligence (BI) and dashboarding tools. Additionally, the streaming data source should possess a degree of consistency and predictability while displaying a reasonable level of variability and randomness.
To this end, we will use the open-source Streaming Synthetic Sales Data Generator project, which I have developed and made available on GitHub. This project’s highly-configurable, Python-based, synthetic data generator generates an unbounded stream of product listings, sales transactions, and inventory restocking activities to a series of Apache Kafka topics.

Source Code
All the source code demonstrated in this post is open source and available on GitHub. There are three separate GitHub projects:
Docker
To make it easier to follow along with the demonstration, we will use Docker Swarm to provision the streaming tools. Alternatively, you could use Kubernetes (e.g., creating a Helm chart) or your preferred CSP or SaaS managed services. Nothing in this demonstration requires you to use a paid service.
The two Docker Swarm stacks are located in the Streaming Synthetic Sales Data Generator project:
- Streaming Stack — Part 1: Apache Kafka, Apache Zookeeper, Apache Spark, UI for Apache Kafka, and the KStreams application
- Streaming Stack — Part 2: Apache Kafka, Apache Zookeeper, Apache Flink, Apache Pinot, Apache Superset, UI for Apache Kafka, and Project Jupyter (JupyterLab).*
* the Jupyter container can be used as an alternative to the Spark container for running PySpark jobs (follow the same steps as for Spark, below)
Demonstration #1: Apache Spark
In the first of four demonstrations, we will examine two Apache Spark Structured Streaming jobs, written in PySpark, demonstrating both batch processing (spark_batch_kafka.py) and stream processing (spark_streaming_kafka.py). We will read from a single stream of data from a Kafka topic, demo.purchases, and write to the console.

Deploying the Streaming Stack
To get started, deploy the first streaming Docker Swarm stack containing the Apache Kafka, Apache Zookeeper, Apache Spark, UI for Apache Kafka, and the KStreams application containers.
The stack will take a few minutes to deploy fully. When complete, there should be a total of six containers running in the stack.

Sales Generator
Before starting the streaming data generator, confirm or modify the configuration/configuration.ini. Three configuration items, in particular, will determine how long the streaming data generator runs and how much data it produces. We will set the timing of transaction events to be generated relatively rapidly for test purposes. We will also set the number of events high enough to give us time to explore the Spark jobs. Using the below settings, the generator should run for an average of approximately 50–60 minutes: (((5 sec + 2 sec)/2)*1000 transactions)/60 sec=~58 min on average. You can run the generator again if necessary or increase the number of transactions.
Start the streaming data generator as a background service:
The streaming data generator will start writing data to three Apache Kafka topics: demo.products, demo.purchases, and demo.inventories. We can view these topics and their messages by logging into the Apache Kafka container and using the Kafka CLI:
Below, we see a few sample messages from the demo.purchases topic:

demo.purchases topicAlternatively, you can use the UI for Apache Kafka, accessible on port 9080.

demo.purchases topic in the UI for Apache Kafka
demo.purchases topic using the UI for Apache KafkaPrepare Spark
Next, prepare the Spark container to run the Spark jobs:
Running the Spark Jobs
Next, copy the jobs from the project to the Spark container, then exec back into the container:
Batch Processing with Spark
The first Spark job, spark_batch_kafka.py, aggregates the number of items sold and the total sales for each product, based on existing messages consumed from the demo.purchases topic. We use the PySpark DataFrame class’s read() and write() methods in the first example, reading from Kafka and writing to the console. We could just as easily write the results back to Kafka.
The batch processing job sorts the results and outputs the top 25 items by total sales to the console. The job should run to completion and exit successfully.

To run the batch Spark job, use the following commands:
Stream Processing with Spark
The stream processing Spark job, spark_streaming_kafka.py, also aggregates the number of items sold and the total sales for each item, based on messages consumed from the demo.purchases topic. However, as shown in the code snippet below, this job continuously aggregates the stream of data from Kafka, displaying the top ten product totals within an arbitrary ten-minute sliding window, with a five-minute overlap, and updates output every minute to the console. We use the PySpark DataFrame class’s readStream() and writeStream() methods as opposed to the batch-oriented read() and write() methods in the first example.
Shorter event-time windows are easier for demonstrations — in Production, hourly, daily, weekly, or monthly windows are more typical for sales analysis.

To run the stream processing Spark job, use the following commands:
We could just as easily calculate running totals for the stream of sales data versus aggregations over a sliding event-time window (example job included in project).

Be sure to kill the stream processing Spark jobs when you are done, or they will continue to run, awaiting more data.
Demonstration #2: Apache Kafka Streams
Next, we will examine Apache Kafka Streams (aka KStreams). For this part of the post, we will also use the second of the three GitHub repository projects, kstreams-kafka-demo. The project contains a KStreams application written in Java that performs stream processing and incremental aggregation.
KStreams Application
The KStreams application continuously consumes the stream of messages from the demo.purchases Kafka topic (source) using an instance of the StreamBuilder() class. It then aggregates the number of items sold and the total sales for each item, maintaining running totals, which are then streamed to a new demo.running.totals topic (sink). All of this using an instance of the KafkaStreams() Kafka client class.
Running the Application
We have at least three choices to run the KStreams application for this demonstration: 1) running locally from our IDE, 2) a compiled JAR run locally from the command line, or 3) a compiled JAR copied into a Docker image, which is deployed as part of the Swarm stack. You can choose any of the options.
Compiling and running the KStreams application locally
We will continue to use the same streaming Docker Swarm stack used for the Apache Spark demonstration. I have already compiled a single uber JAR file using OpenJDK 17 and Gradle from the project’s source code. I then created and published a Docker image, which is already part of the running stack.
Since we ran the sales generator earlier for the Spark demonstration, there is existing data in the demo.purchases topic. Re-run the sales generator (nohup python3 ./producer.py &) to generate a new stream of data. View the results of the KStreams application, which has been running since the stack was deployed using the Kafka CLI or UI for Apache Kafka:
Below, in the top terminal window, we see the output from the KStreams application. Using KStream’s peek() method, the application outputs Purchase and Total instances to the console as they are processed and written to Kafka. In the lower terminal window, we see new messages being published as a continuous stream to output topic, demo.running.totals.

Part Two
In part two of this two-part post, we continue our exploration of the four popular open-source stream processing projects. We will cover Apache Flink and Apache Pinot. In addition, we will incorporate Apache Superset into the demonstration, building a real-time dashboard to visualize the results of our stream processing.
This blog represents my viewpoints and not of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners. All diagrams and illustrations are the property of the author unless otherwise noted.
Lakehouse Data Modeling using dbt, Amazon Redshift, Redshift Spectrum, and AWS Glue
Learn how dbt makes it easy to transform data and materialize models in a modern cloud data lakehouse built on AWS
Introduction
Data lakes have grabbed much of the analytics community’s attention in recent years, thanks to an overabundance of VC-backed analytics startups and marketing dollars. Nonetheless, data warehouses, specifically modern cloud data warehouses, continue to gain market share, led by Snowflake, Amazon Redshift, Google Cloud BigQuery, and Microsoft’s Azure Synapse Analytics.
Several factors have fostered the renewed interest and appeal of data warehouses, including the data lakehouse architecture. According to Databricks, “a lakehouse is a new, open architecture that combines the best elements of data lakes and data warehouses. Lakehouses are enabled by a new system design: implementing similar data structures and data management features to those in a data warehouse directly on top of low-cost cloud storage in open formats.” Similarly, Snowflake describes a lakehouse as “a data solution concept that combines elements of the data warehouse with those of the data lake. Data lakehouses implement data warehouses’ data structures and management features for data lakes, which are typically more cost-effective for data storage.”
dbt
In the following post, we will explore the use of dbt (data build tool), developed by dbt Labs, to transform data in an AWS-based data lakehouse, built with Amazon Redshift, Redshift Spectrum, AWS Glue, and Amazon S3. According to dbt Labs, “dbt enables analytics engineers to transform data in their warehouses by simply writing select statements. dbt handles turning these select statements into tables and views.” Further, “dbt does the T in ELT (Extract, Load, Transform) processes — it doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse.”
Amazon Redshift
According to AWS, “Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes using AWS-designed hardware and machine learning to deliver the best price-performance at any scale.” AWS claims Amazon Redshift is the most widely used cloud data warehouse.
Amazon Redshift Spectrum
According to AWS, “Redshift Spectrum allows you to efficiently query and retrieve structured and semi-structured data from files in Amazon S3 without having to load the data into Amazon Redshift tables.” Redshift Spectrum tables define the data structure for the files in Amazon S3. The external tables exist in an external data catalog, which can be AWS Glue, the data catalog that comes with Amazon Athena, or an Apache Hive metastore.
dbt can interact with Amazon Redshift Spectrum to create external tables, refresh external table partitions, and access raw data in an Amazon S3-based data lake from the data warehouse. We will use dbt along with the dbt package, dbt_external_tables, to create the external tables in an AWS Glue data catalog.
Prerequisites
Prerequisites to follow along with this post’s demonstration include:
- Amazon S3 bucket to store raw data;
- Amazon Redshift or Amazon Redshift Serverless cluster;
- AWS IAM Role with permissions to Amazon Redshift, Amazon S3, and AWS Glue;
- dbt Cloud account;
- dbt CLI (dbt Core) and dbt Amazon Redshift adapter installed locally;
- Microsoft Visual Studio Code (VS Code) with dbt extensions installed;
The post’s demonstration uses dbt Cloud, VS Code, and the dbt CLI interchangeably with the project’s GitHub repository as a source. Follow along with the demonstration using any or all of these three dbt options.
Cost Warning!
Be careful when creating a new, provisioned Amazon Redshift cluster for this demonstration. The suggested default Production cluster with two ra3.4xlarge on-demand compute nodes and AQUA (Redshift’s Advanced Query Accelerator) enabled is estimated at $4,694/month ($3.26/node/hour). For this demonstration, choose the minimum size provisioned Redshift cluster configuration of one dc2.large on-demand compute node, estimated to cost $180/month ($0.25/node/hour). Be sure to delete the cluster when the demonstration is complete.

Amazon Redshift Serverless Option
AWS recently announced the general availability (GA) of Amazon Redshift Serverless on July 12, 2022. Amazon Redshift Serverless allows data analysts, developers, and data scientists to run and scale analytics without having to provision and manage data warehouse clusters. dbt is fully compatible with Amazon Redshift Serverless and is an alternative to provisioned Redshift for this demonstration. According to AWS, Amazon Redshift Serverless measures data warehouse capacity in Redshift Processing Units (RPUs). You pay for the workloads you run in RPU-hours on a per-second basis (with a 60-second minimum charge), including queries that access data in open file formats in Amazon S3.
Source Code
All the source code demonstrated in this post is open source and available on GitHub.
Sample Data
This demonstration uses the TICKIT sample database provided by AWS and designed for use with Amazon Redshift. This sample database application tracks sales activity for the fictional online TICKIT website, where users buy and sell tickets for sporting events, shows, and concerts. The database consists of seven tables in a star schema: five dimension tables and two fact tables. A clean copy of the raw TICKIT data, formatted as pipe-delimited text files, is included in this GitHub project. Use the following shell commands to copy the raw data to Amazon S3:
Prepare Amazon Redshift for dbt
Create New Database
Create a new Redshift database to use for the demonstration, demo.
Create Database Schemas
Within the new Redshift database,demo, create the external schema, tickit_external, and the corresponding external AWS Glue Data Catalog, tickit_dbt, using the CREATE EXTERNAL SCHEMA Redshift SQL command. Make sure to update the command to reflect your IAM Role’s ARN. Next, create the schema that will hold our dbt models, tickit_dbt. Lastly, as a security best practice, drop the default public schema.
From the AWS Glue console, we should observe a new tickit_dbt AWS Glue Data Catalog. The description shown below was manually added after the catalog was created.

Create dbt Database User and Group
As a security best practice, create a separate database dbt user and dbt group. We are assigning a completely arbitrary connection limit of ten. Then, apply the grants to allow the dbt group access to the new database and schemas. Lastly, change the two schema’s owners to the dbt.
Alternately, we could use an IAM Role with a SAML 2.0-compliant IdP.
Initialize and Configure dbt for Redshift
Next, configure your dbt Cloud account and dbt locally with your Amazon Redshift connection information using the dbt init command. On a Mac, this configuration is stored in the /Users/<your_usernama>/.dbt/profiles.yml file. You will need your Redshift cluster host URL, port, database, username, and password. With your local install of dbt, we can use the dbt debug command to confirm the new configuration.

Project Structure
The GitHub project structure follows many of the best practices outlined in dbt Labs’ Best Practice Guide. Data models in the models directory is organized into the recommended staging, intermediate, and marts subdirectories (aka layers).

From a data lineage perspective, in this project, the staging layer’s data models depend on the external tables (AWS Glue/Amazon Redshift Spectrum). The intermediate layer’s data models depend on the staging models. The marts layer’s data models depend on staging and intermediate models.

Install dbt Packages
The GitHub project’s packages.yml contains a few commonly recommended packages. The only one required for this post is the dbt-labs/dbt_external_tables package. Make sure your project is referring to the latest version of the package.
Use the dbt deps command to install the packages locally.

External Tables
The _tickit__sources.yml file in the models/staging/tickit/external_tables/ model’s subdirectory defines the schema and S3 location for each of the seven external TICKIT database tables: category, date, event, listing, sale, user, and venue. You will need to update this file to reflect the name of your Amazon S3 bucket, in seven places.
Execute the command, dbt run-operation stage_external_sources, to create the seven external tables in the AWS Glue Data Catalog. This command is part of the dbt_external_tables package we installed earlier. It iterates through all source nodes, creates the tables if missing, and refreshes metadata.

If we failed to run the previous SQL statements to set schema ownership to the dbt user, the following error will likely occur.

Once the command completes, we should observe seven new tables in the AWS Glue Data Catalog.

Examining one of the AWS Glue data catalog tables, we can observe how the configuration in the _tickit__sources.yml file was used to define the table’s properties and schema. Note the Location field indicates where the underlying data is located in our Amazon S3 bucket.

Staging Layer
In their best practices guide, dbt describes the staging layer in the following manner: “you can think of the staging layer as condensing and refining this material into the individual atoms we’ll later build more intricate and useful structures with.” The staging data models are the base tables and views we will use to build more complex aggregations and analytics queries in Redshift. The schema.yml file, also in the models/staging/tickit/ model’s subdirectory, defines seven late-binding views, modeled by dbt, to be created in Amazon Redshift.
The staging model’s SQL statements also follow many of dbt’s best practices. Below, we see an example of the stg_tickit__sales model (stg_tickit__sales.sql). This model performs a SELECT from the external sale table in the external_table schema. The model performs column renaming and basic calculations.
The the dbt run command, according to dbt, “executes compiled SQL model files against the current target database. dbt connects to the target database and runs the relevant SQL, required to materialize all data models using the specified materialization strategies.” Instead of using the dbt run command to create all the project’s tables and views at once, for now, we are limiting the command to just the models in the ./models/staging/tickit/ directory using the --select optional argument. Execute the dbt run --select staging command to materialize the seven corresponding staging tables in Amazon Redshift.

Once the command completes, we should observe seven new views in Amazon Redshift demo database’s tickit_dbt schema with the stg_ prefix.

Selecting from any of the views should return data.

Late Binding Views
This demonstration uses late binding views for staging and intermediate layer models. According to dbt, “using late-binding views in a production deployment of dbt can vastly improve the availability of data in the warehouse, especially for models that are materialized as late-binding views and are queried by end-users, since they won’t be dropped when upstream models are updated. Additionally, late binding views can be used with external tables via Redshift Spectrum.”
Alternatively, we could define the seven staging models as tables instead of late binding views. Once created as tables, the dependent intermediate and marts views will not require a late-binding reference, as in this project.
Intermediate Layer
In their best practices guide, dbt describes the intermediate layer as “purpose-built transformation steps.” Further, “the best guiding principle is to think about verbs (e.g. pivoted, aggregated_to_user, joined, fanned_out_by_quanity, funnel_created, etc.) in the intermediate layer.”
The project’s intermediate layer consists of two models related to users. The sample TICKIT database lumps all users into a single table. However, for analytics purposes, different user personas might interest marketing teams, such as buyers, sellers, sellers who also buy, and non-buyers (users who have never purchased tickets). The two models in the project’s intermediate layer filter for buyers and for sellers, resulting in two separate views of user personas.
To materialize the intermediate layer’s two data models into views, execute the command, dbt run --select intermediate.

Once the command completes, we should observe a total of nine views in Amazon Redshift demo database’s tickit_dbt schema — seven staging and two intermediate, identified with the int_ prefix.

Marts Layer
In their best practices guide, dbt describes the marts layer as “business defined entities.” Further, “this is the layer where everything comes together and we start to arrange all of our atoms (staging models) and molecules (intermediate models) into full-fledged cells that have identity and purpose. We sometimes like to call this the entity layer or concept layer, to emphasize that all our marts are meant to represent a specific entity or concept at its unique grain.”
The project’s marts layer consists of four data models across marketing and sales. The models are materialized as two dimension tables and two fact tables. Although it is common practice to describe and label these as traditional star schema dimension (dim_) or fact (fct_) tables, in reality, the fact tables in this demonstration are actually flat, de-normalized, wide tables. Wide tables generally have better analytics performance in a modern data warehouse, according to Fivetran and others.
The marts layer’s models take various dependencies through joins on staging and intermediate models. The data model above, fct_sales, has dependencies on multiple staging and intermediate models.

To materialize the marts layer’s four data models into tables, execute the command, dbt run --select marts.

Once the command completes, we should observe four tables and nine views in the Redshift demo database’s tickit_dbt schema. Note how the dbt model for fct_sales (shown above), with its Jinja templating and multiple CTEs have been compiled into the resulting table in Redshift, this is the real magic of dbt!

At this point, all of the project’s models have been compiled and created in the Redshift demo database by dbt.
Analyses
The demonstration’s project also contains example analyses. dbt allows us to version control more analytical-oriented SQL files within our dbt project using the analyses functionality of dbt. These analyses do not fit the fairly opinionated dbt model definition. We can compile the analyses SQL file using the dbt compile command, then copy and paste the resulting SQL statements from the target/compiled/ subdirectory into our data warehouse’s query tool of choice.

Project Documentation
Using the dbt docs generate command will automatically generate the project’s documentation website from the SQL and YAML files. Documentations can be generated and displayed from your dbt Cloud account or hosted locally.

Testing
According to dbt, “Tests are assertions you make about your models and other resources in your dbt project (e.g. sources, seeds, and snapshots). When you run dbt test, dbt will tell you if each test in your project passes or fails.” The project contains over 50 tests, split between the _tickit__sources.yml file and individual tests in the test/ directory. Typical dbt tests check for non-null and unique values, values within an expected numeric range, and values from a known list of strings. Any SELECT statement written in SQL can be tested.
Execute the project’s tests using the dbt test command. We can execute individual tests using the --select optional argument, for example, dbt test --select assert_all_sale_amounts_are_positive. We can also use the --threads optional argument with most dbt commands, including dbt test, increasing parallelism and reducing execution time. The example below uses 10 threads, the arbitrary maximum configured for the Amazon Redshift dbt user.


Jobs
According to dbt, Jobs are a set of dbt commands that you want to run on a schedule. For example, dbt run and dbt test. Jobs can load packages, run tests, materialize models, check source freshness (dbt source freshness), and regenerate documentation. Below, we have created a daily job to test, refresh, and document our project as the data is updated in the data lake.

Notifications
According to dbt, Setting up notifications in dbt Cloud will allow you to receive alerts via Email or a chosen Slack channel when a job run succeeds, fails, or is canceled.

The Slack notifications include run status, timings, and a link to open the job in dbt Cloud. Below, we see a notification regarding our project’s daily job run.

Exposures
Exposures are a recent addition to dbt. Exposures make it possible to define and describe a downstream use of our dbt project, such as in a dashboard, application, or data science pipeline. Below we see an example of an exposure describing a sales dashboard created in Amazon QuickSight.
The exposure YAML file shown above describes the Amazon QuickSight dashboard shown below.

Exposures work with dbt’s auto-documentation feature. dbt populates a dedicated page in the auto-generated documentation site with context relevant to data consumers.


Conclusion
In this post, we covered some of the basic functionality of dbt. We learned how dbt enables analysts to work more like software engineers. We also learned how dbt makes it easy to codify data models in SQL, to version control and manage data models as code with git, and collaborate on data models with other data team members.
Topics not explored in this post but critical to most large-scale dbt-managed production environments include advanced Jinja templating and macros, model freshness, orchestration, job scheduling, Continuous Integration and GitOps, notifications, environment variables, and incremental models. We will explore these additional dbt capabilities in future posts.
This blog represents my viewpoints and not of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners. All diagrams and illustrations are the property of the author unless otherwise noted.
Serverless Analytics on AWS: Getting Started with Amazon EMR Serverless and Amazon MSK Serverless
Utilizing the recently released Amazon EMR Serverless and Amazon MSK Serverless for batch and streaming analytics with Apache Spark and Apache Kafka
Introduction
Amazon EMR Serverless
AWS recently announced the general availability (GA) of Amazon EMR Serverless on June 1, 2022. EMR Serverless is a new serverless deployment option in Amazon EMR, in addition to EMR on EC2, EMR on EKS, and EMR on AWS Outposts. EMR Serverless provides a serverless runtime environment that simplifies the operation of analytics applications that use the latest open source frameworks, such as Apache Spark and Apache Hive. According to AWS, with EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters to run applications with these frameworks.
Amazon MSK Serverless
Similarly, on April 28, 2022, AWS announced the general availability of Amazon MSK Serverless. According to AWS, Amazon MSK Serverless is a cluster type for Amazon MSK that makes it easy to run Apache Kafka without managing and scaling cluster capacity. MSK Serverless automatically provisions and scales compute and storage resources, so you can use Apache Kafka on demand and only pay for the data you stream and retain.
Serverless Analytics
In the following post, we will learn how to use these two new, powerful, cost-effective, and easy-to-operate serverless technologies to perform batch and streaming analytics. The PySpark examples used in this post are similar to those featured in two earlier posts, which featured non-serverless alternatives Amazon EMR on EC2 and Amazon MSK: Getting Started with Spark Structured Streaming and Kafka on AWS using Amazon MSK and Amazon EMR and Stream Processing with Apache Spark, Kafka, Avro, and Apicurio Registry on AWS using Amazon MSK and EMR.
Source Code
All the source code demonstrated in this post is open-source and available on GitHub.
git clone --depth 1 -b main \
https://github.com/garystafford/emr-msk-serverless-demo.git
Architecture
The post’s high-level architecture consists of an Amazon EMR Serverless Application, Amazon MSK Serverless Cluster, and Amazon EC2 Kafka client instance. To support these three resources, we will need two Amazon Virtual Private Clouds (VPCs), a minimum of three subnets, an AWS Internet Gateway (IGW) or equivalent, an Amazon S3 Bucket, multiple AWS Identity and Access Management (IAM) Roles and Policies, Security Groups, and Route Tables, and a VPC Gateway Endpoint for S3. All resources are constrained to a single AWS account and a single AWS Region, us-east-1.
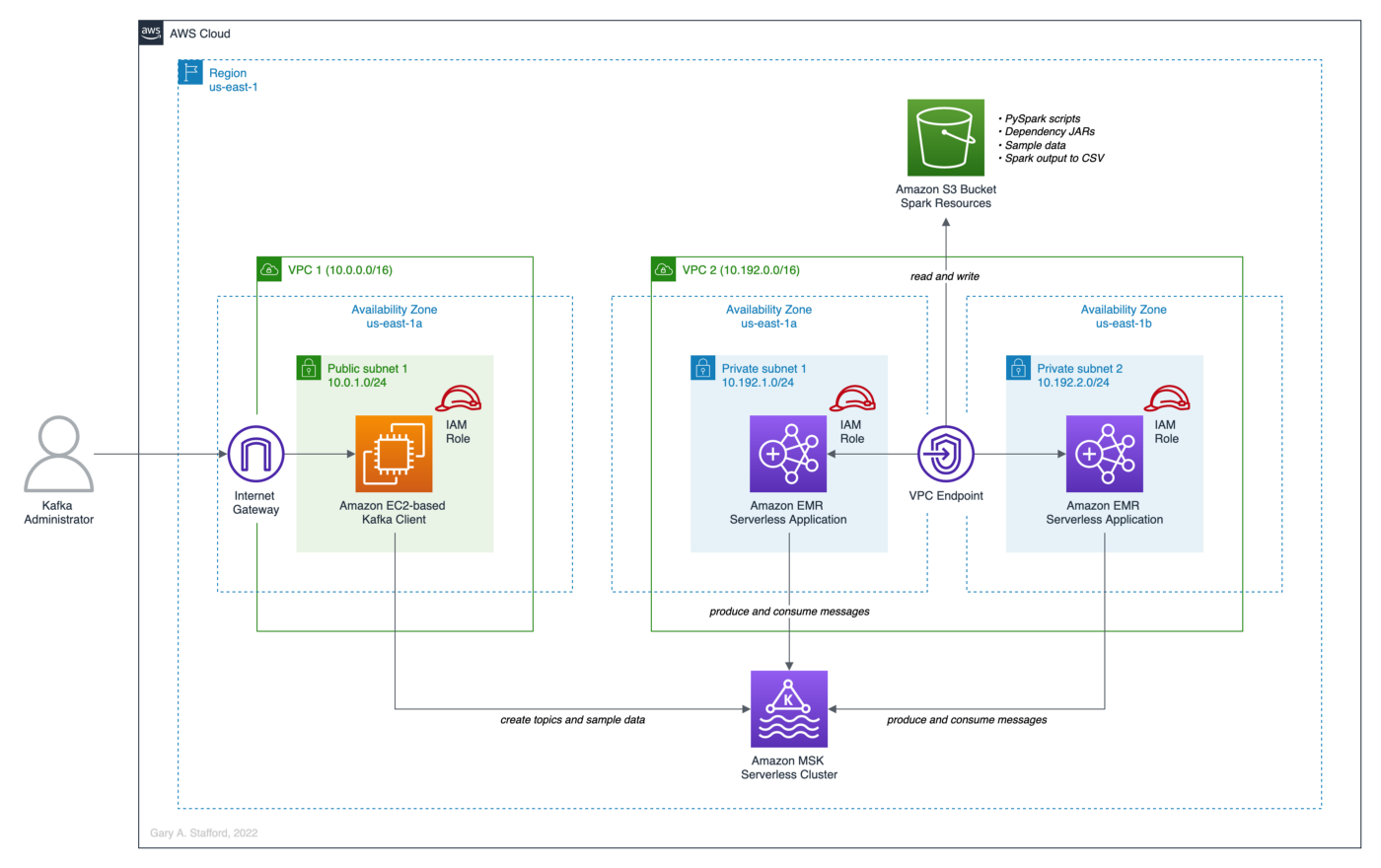
Prerequisites
As a prerequisite for this post, you will need to create the following resources:
- (1) Amazon EMR Serverless Application;
- (1) Amazon MSK Serverless Cluster;
- (1) Amazon S3 Bucket;
- (1) VPC Endpoint for S3;
- (3) Apache Kafka topics;
- PySpark applications, related JAR dependencies, and sample data files uploaded to Amazon S3 Bucket;
Let’s walk through each of these prerequisites.
Amazon EMR Serverless Application
Before continuing, I suggest familiarizing yourself with the AWS documentation for Amazon EMR Serverless, especially, What is Amazon EMR Serverless? Create a new EMR Serverless Application by following the AWS documentation, Getting started with Amazon EMR Serverless. The creation of the EMR Serverless Application includes the following resources:
- Amazon S3 bucket for storage of Spark resources;
- Amazon VPC with at least two private subnets and associated Security Group(s);
- EMR Serverless runtime AWS IAM Role and associated IAM Policy;
- Amazon EMR Serverless Application;
For this post, use the latest version of EMR available in the EMR Studio Serverless Application console, the newly released version 6.7.0, to create a Spark application.

Keep the default pre-initialized capacity, application limits, and application behavior settings.

Since we are connecting to MSK Serverless from EMR Serverless, we need to configure VPC access. Select the new VPC and at least two private subnets in different Availability Zones (AZs).

According to the documentation, the subnets selected for EMR Serverless must be private subnets. The associated route tables for the subnets should not contain direct routes to the Internet.


Amazon MSK Serverless Cluster
Similarly, before continuing, I suggest familiarizing yourself with the AWS documentation for Amazon MSK Serverless, especially MSK Serverless. Create a new MSK Serverless Cluster by following the AWS documentation, Getting started using MSK Serverless clusters. The creation of the MSK Serverless Cluster includes the following resources:
- AWS IAM Role and associated IAM Policy for the Amazon EC2 Kafka client instance;
- VPC with at least one public subnet and associated Security Group(s);
- Amazon EC2 instance used as Apache Kafka client, provisioned in the public subnet of the above VPC;
- Amazon MSK Serverless Cluster;

Associate the new MSK Serverless Cluster with the EMR Serverless Application’s VPC and two private subnets. Also, associate the cluster with the EC2-based Kafka client instance’s VPC and its public subnet.


According to the AWS documentation, Amazon MSK does not support all AZs. For example, I tried to use a subnet in us-east-1e threw an error. If this happens, choose an alternative AZ.


VPC Endpoint for S3
To access the Spark resource in Amazon S3 from EMR Serverless running in the two private subnets, we need a VPC Endpoint for S3. Specifically, a Gateway Endpoint, which sends traffic to Amazon S3 or DynamoDB using private IP addresses. A gateway endpoint for Amazon S3 enables you to use private IP addresses to access Amazon S3 without exposure to the public Internet. EMR Serverless does not require public IP addresses, and you don’t need an internet gateway (IGW), a NAT device, or a virtual private gateway in your VPC to connect to S3.

Create the VPC Endpoint for S3 (Gateway Endpoint) and add the route table for the two EMR Serverless private subnets. You can add additional routes to that route table, such as VPC peering connections to data sources such as Amazon Redshift or Amazon RDS. However, do not add routes that provide direct Internet access.

Kafka Topics and Sample Messages
Once the MSK Serverless Cluster and EC2-based Kafka client instance are provisioned and running, create the three required Kafka topics using the EC2-based Kafka client instance. I recommend using AWS Systems Manager Session Manager to connect to the client instance as the ec2-user user. Session Manager provides secure and auditable node management without the need to open inbound ports, maintain bastion hosts, or manage SSH keys. Alternatively, you can SSH into the client instance.

Before creating the topics, use a utility like telnet to confirm connectivity between the Kafka client and the MSK Serverless Cluster. Verifying connectivity will save you a lot of frustration with potential security and networking issues.
With MSK Serverless Cluster connectivity confirmed, create the three Kafka topics: topicA, topicB, and topicC. I am using the default partitioning and replication settings from the AWS Getting Started Tutorial.
To create some quick sample data, we will copy and paste 250 messages from a file included in the GitHub project, sample_data/sales_messages.txt, into topicA. The messages are simple mock sales transactions.
Use the kafka-console-producer Shell script to publish the messages to the Kafka topic. Use the kafka-console-consumer Shell script to validate the messages made it to the topic by consuming a few messages.
The output should look similar to the following example.

Spark Resources in Amazon S3
To submit and run the five Spark Jobs included in the project, you will need to copy the following resources to your Amazon S3 bucket: (5) Apache Spark jobs, (5) related JAR dependencies, and (2) sample data files.
PySpark Applications
To start, copy the five PySpark applications to a scripts/ subdirectory within your Amazon S3 bucket.

Sample Data
Next, copy the two sample data files to a sample_data/ subdirectory within your Amazon S3 bucket. The large file contains 2,000 messages, while the small file contains 600 messages. These two files can be used interchangeably with the post’s final streaming example.

PySpark Dependencies
Lastly, the PySpark applications have a handful of JAR dependencies that must be available when the job runs, which are not on the EMR Serverless classpath by default. If you are unsure which JARs are already on the EMR Serverless classpath, you can check the Spark UI’s Environment tab’s Classpath Entries section. Accessing the Spark UI is demonstrated in the first PySpark application example, below.

It is critical to choose the correct version of each JAR dependency based on the version of libraries used with the EMR and MSK. Using the wrong version or inconsistent versions, especially Scala, can result in job failures. Specifically, we are targeting Spark 3.2.1 and Scala 2.12 (EMR v6.7.0: Amazon’s Spark 3.2.1, Scala 2.12.15, Amazon Corretto 8 version of OpenJDK), and Apache Kafka 2.8.1 (MSK Serverless: Kafka 2.8.1).
Download the seven JAR files locally, then copy them to a jars/ subdirectory within your Amazon S3 bucket.

PySpark Applications Examples
With the EMR Serverless Application, MSK Serverless Cluster, Kafka topics, and sample data created, and the Spark resources uploaded to Amazon S3, we are ready to explore four different Spark examples.
Example 1: Kafka Batch Aggregation to the Console
The first PySpark application, 01_example_console.py, reads the same 250 sample sales messages from topicA you published earlier, aggregates the messages, and writes the total sales and quantity of orders by country to the console (stdout).
There are no hard-coded values in any of the PySpark application examples. All required environment-specific variables, such as your MSK Serverless bootstrap server (host and port) and Amazon S3 bucket name, will be passed to the running Spark jobs as arguments from the spark-submit command.
To submit your first PySpark job to the EMR Serverless Application, use the emr-serverless API from the AWS CLI. You will need (4) values: 1) your EMR Serverless Application’s application-id, 2) the ARN of your EMR Serverless Application’s execution IAM Role, 3) your MSK Serverless bootstrap server (host and port), and 4) the name of your Amazon S3 bucket containing the Spark resources.
Switching to the EMR Serverless Application console, you should see the new Spark job you just submitted in one of several job states.

You can click on the Spark job to get more details. Note the Script arguments and Spark properties passed in from the spark-submit command.

From the Spark job details tab, access the Spark UI, aka Spark Web UI, from a button in the upper right corner of the screen. If you have experience with Spark, you are most likely familiar with the Spark Web UI to monitor and tune Spark jobs.

From the initial screen, the Spark History Server tab, click on the App ID. You can access an enormous amount of Spark-related information about your job and EMR environment from the Spark Web UI.



The Executors tab will give you access to the Spark job’s output. The output we are most interested in is the driver executor’s stderr and stdout (first row of the second table, shown below).

The stderr contains output related to the running Spark job. Below we see an example of Kafka consumer configuration values output to stderr. Several of these values were passed in from the Spark job, including items such as kafka.bootstrap.servers, security.protocol, sasl.mechanism, and sasl.jaas.config.

The stdout from the driver executor contains the console output as directed from the Spark job. Below we see the successfully aggregated results of the first Spark job, output to stdout.
Example 2: Kafka Batch Aggregation to CSV in S3
Although the console is useful for development and debugging, it is typically not used in Production. Instead, Spark typically sends results to S3 as CSV, JSON, Parquet, or Arvo formatted files, to Kafka, to a database, or to an API endpoint. The second PySpark application, 02_example_csv_s3.py, reads the same 250 sample sales messages from topicA you published earlier, aggregates the messages, and writes the total sales and quantity of orders by country to a CSV file in Amazon S3.
To submit your second PySpark job to the EMR Serverless Application, use the emr-serverless API from the AWS CLI. Similar to the first example, you will need (4) values: 1) your EMR Serverless Application’s application-id, 2) the ARN of your EMR Serverless Application’s execution IAM Role, 3) your MSK Serverless bootstrap server (host and port), and 4) the name of your Amazon S3 bucket containing the Spark resources.
If successful, the Spark job should create a single CSV file in the designated Amazon S3 key (directory path) and an empty _SUCCESS indicator file. The presence of an empty _SUCCESS file signifies that the save() operation completed normally.

Below we see the expected pipe-delimited output from the second Spark job.
Example 3: Kafka Batch Aggregation to Kafka
The third PySpark application, 03_example_kafka.py, reads the same 250 sample sales messages from topicA you published earlier, aggregates the messages, and writes the total sales and quantity of orders by country to a second Kafka topic, topicB. This job now has both read and write options.
To submit your next PySpark job to the EMR Serverless Application, use the emr-serverless API from the AWS CLI. Similar to the first two examples, you will need (4) values: 1) your EMR Serverless Application’s application-id, 2) the ARN of your EMR Serverless Application’s execution IAM Role, 3) your MSK Serverless bootstrap server (host and port), and 4) the name of your Amazon S3 bucket containing the Spark resources.
Once the job completes, you can confirm the results by returning to your EC2-based Kafka client. Use the same kafka-console-consumer command you used previously to show messages from topicB.
If the Spark job and the Kafka client command worked successfully, you should see aggregated messages similar to the example output below. Note we are not using keys with the Kafka messages, only values for these simple examples.

Example 4: Spark Structured Streaming
For our final example, we will switch from batch to streaming — from read to readstream and from write to writestream. Before continuing, I suggest reading the Structured Streaming Programming Guide.
In this example, we will demonstrate how to continuously measure a common business metric — real-time sales volumes. Imagine you are sell products globally and want to understand the relationship between the time of day and buying patterns in different geographic regions in real-time. For any given window of time — this 15-minute period, this hour, this day, or this week— you want to know the current sales volumes by country. You are not reviewing previous sales periods or examing running sales totals, but real-time sales during a sliding time window.
We will use two PySpark jobs running concurrently to simulate this metric. The first application, 04_stream_sales_to_kafka.py, simulates streaming data by continuously writing messages to topicC — 2,000 messages with a 0.5-second delay between messages. In my tests, the job ran for ~28–29 minutes.
Simultaneously, the PySpark application, 05_streaming_kafka.py, continuously consumes the sales transaction messages from the same topic, topicC. Then, Spark aggregates messages over a sliding event-time window and writes the results to the console.
To submit the two PySpark jobs to the EMR Serverless Application, use the emr-serverless API from the AWS CLI. Again, you will need (4) values: 1) your EMR Serverless Application’s application-id, 2) the ARN of your EMR Serverless Application’s execution IAM Role, 3) your MSK Serverless bootstrap server (host and port), and 4) the name of your Amazon S3 bucket containing the Spark resources.
Switching to the EMR Serverless Application console, you should see both Spark jobs you just submitted in one of several job states.

Using the Spark UI again, we can review the output from the second job, 05_streaming_kafka.py.

With Spark Structured Streaming jobs, we have an extra tab in the Spark UI, Structured Streaming. This tab displays all running jobs with their latest [micro]batch number, the aggregate rate of data arriving, and the aggregate rate at which Spark is processing data. Unfortunately, with MSK Serverless, AWS doesn’t appear to allow access to the detailed streaming query statistics via the Run ID, which greatly reduces its value. You receive a 502 error when clicking on the Run ID hyperlink.

The output we are most interested in, again, is contained in the driver executor’s stderr and stdout (first row of the second table, shown below).

Below we see sample output from stderr. The output shows the results of a micro-batch. According to the Apache Spark documentation, internally, by default, Structured Streaming queries are processed using a micro-batch processing engine. The engine processes data streams as a series of small batch jobs, achieving end-to-end latencies as low as 100ms and exactly-once fault-tolerance guarantees.
The corresponding output to the micro-batch output above is shown below. We see the initial micro-batch results, starting with the first micro-batch before any messages are streamed to topicC.
If you are familiar with Spark Structured Streaming, you are likely aware that these Spark jobs run continuously. In other words, the streaming jobs will not stop; they continually await more streaming data.

The first job, 04_stream_sales_to_kafka.py, will run for ~28–29 minutes and stop with a status of Sucess. However, the second job, 05_streaming_kafka.py, the Spark Structured Streaming job, must be manually canceled.

Cleaning Up
You can delete your resources from the AWS Management Console or AWS CLI. However, to delete your Amazon S3 bucket, all objects (including all object versions and delete markers) in the bucket must be deleted before the bucket itself can be deleted.
Conclusion
In this post, we discovered how easy it is to adopt a serverless approach to Analytics on AWS. With EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters to run applications with these frameworks. With MSK Serverless, you can use Apache Kafka on demand and pay for the data you stream and retain. In addition, MSK Serverless automatically provisions and scales compute and storage resources. Given suitable analytics use cases, EMR Serverless with MSK Serverless will likely save you time, effort, and expense.
This blog represents my viewpoints and not of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners. All diagrams and illustrations are the property of the author unless otherwise noted.
Utilizing In-memory Data Caching to Enhance the Performance of Data Lake-based Applications
Posted by Gary A. Stafford in Analytics, AWS, Big Data, Cloud, Java Development, Software Development, SQL on July 12, 2022
Significantly improve the performance and reduce the cost of data lake-based analytics applications using Amazon ElastiCache for Redis
Introduction
The recent post, Developing Spring Boot Applications for Querying Data Lakes on AWS using Amazon Athena, demonstrated how to develop a Cloud-native analytics application using Spring Boot. The application queried data in an Amazon S3-based data lake via an AWS Glue Data Catalog utilizing the Amazon Athena API.
Securely exposing data in a data lake using RESTful APIs can fulfill many data-consumer needs. However, access to that data can be significantly slower than access from a database or data warehouse. For example, in the previous post, we imported the OpenAPI v3 specification from the Spring Boot service into Postman. The API specification contained approximately 17 endpoints.
From my local development laptop, the Postman API test run times for all service endpoints took an average of 32.4 seconds. The Spring Boot service was running three Kubernetes pod replicas on Amazon EKS in the AWS US East (N. Virginia) Region.
Compare the data lake query result times to equivalent queries made against a minimally-sized Amazon RDS for PostgreSQL database instance containing the same data. The average run times for all PostgreSQL queries averaged 10.8 seconds from a similar Spring Boot service. Although not a precise benchmark, we can clearly see that access to the data in the Amazon S3-based data lake is substantially slower, approximately 3x slower, than that of the PostgreSQL database. Tuning the database would easily create an even greater disparity.
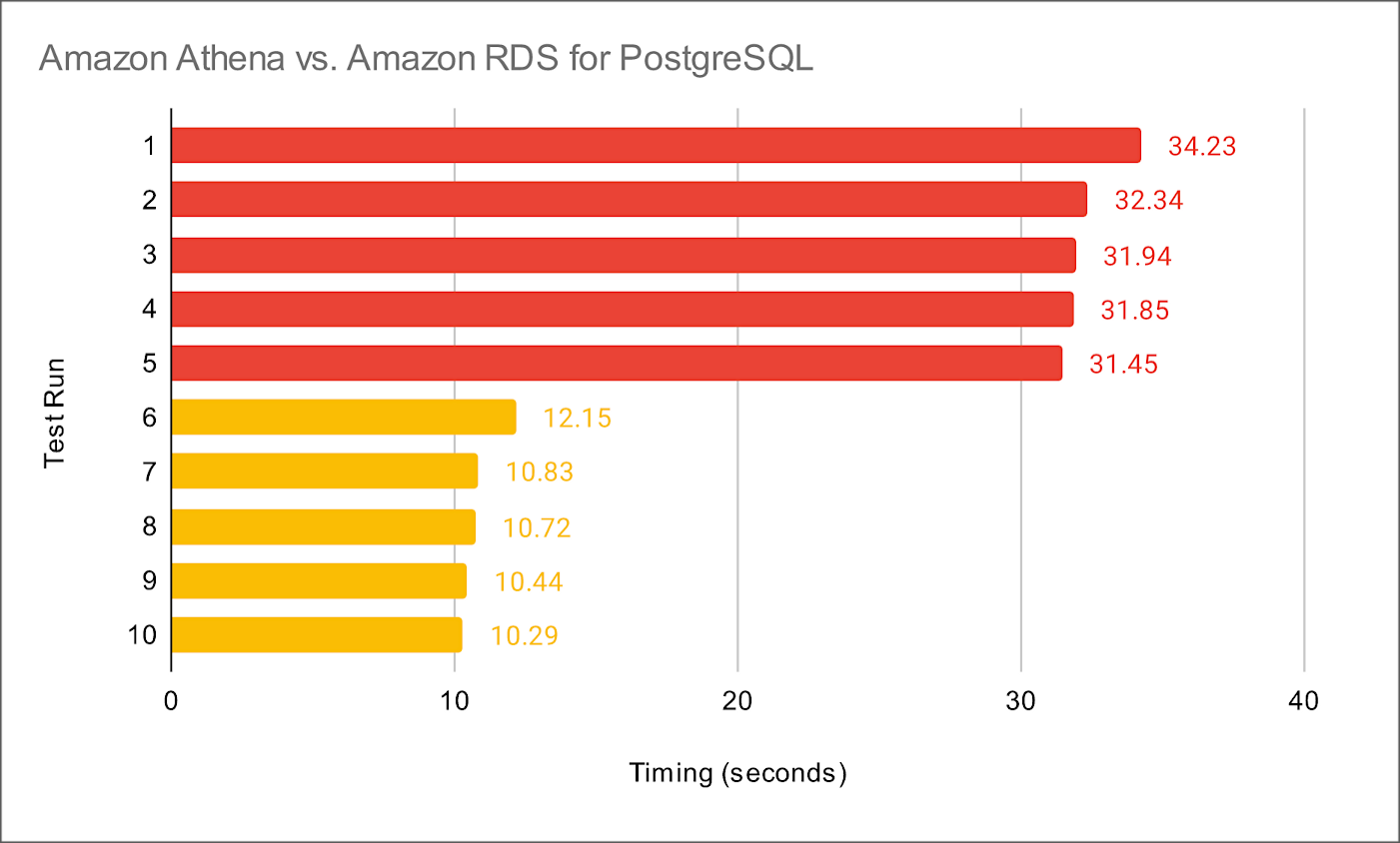
Caching for Data Lakes
According to AWS, the speed and throughput of a database can be the most impactful factor for overall application performance. Consequently, in-memory data caching can be one of the most effective strategies to improve overall application performance and reduce database costs. This same caching strategy can be applied to analytics applications built atop data lakes, as this post will demonstrate.
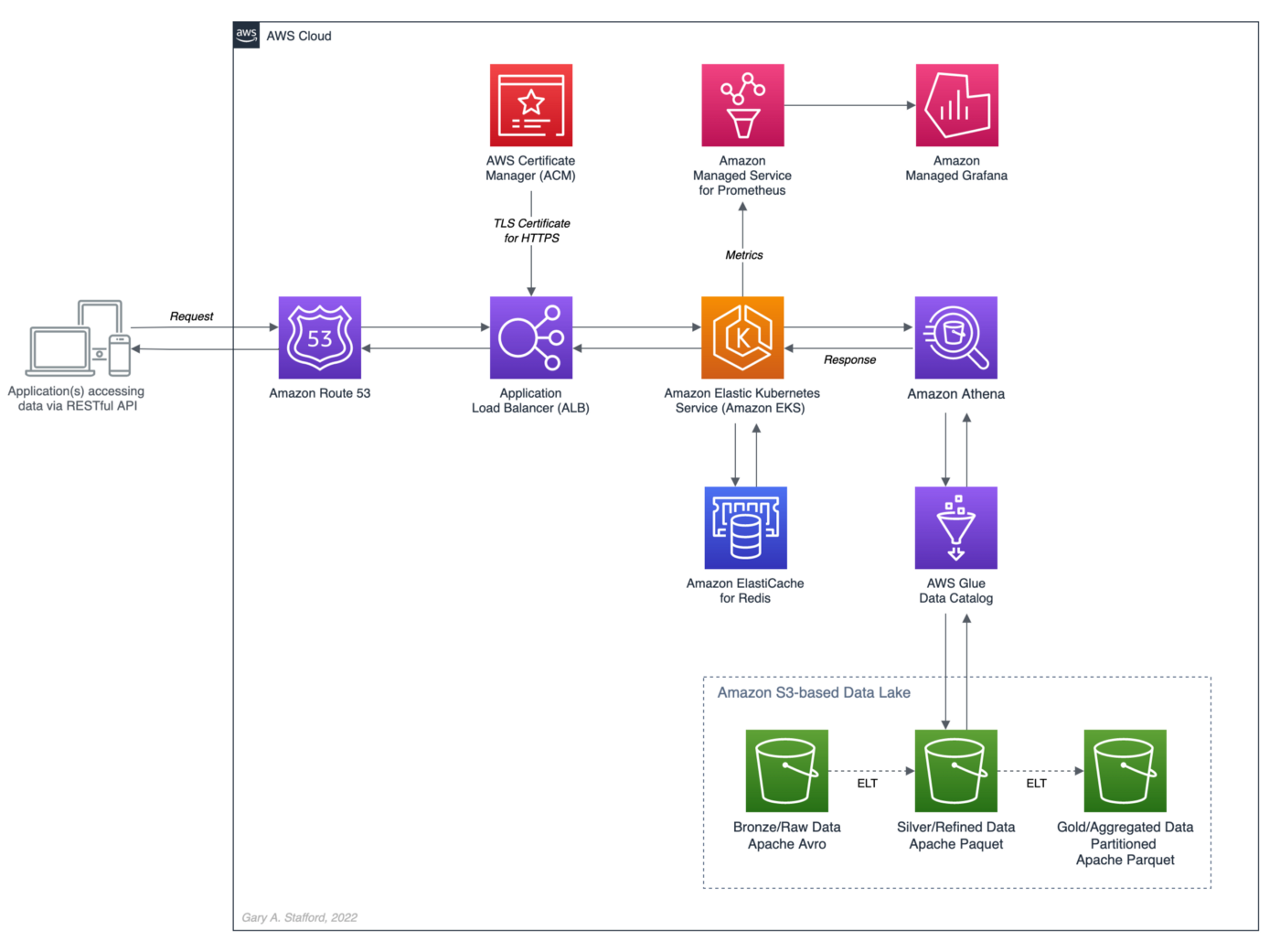
In-memory Caching
According to Hazelcast, memory caching (aka in-memory caching), often simply referred to as caching, is a technique in which computer applications temporarily store data in a computer’s main memory (e.g., RAM) to enable fast retrievals of that data. The RAM used for the temporary storage is known as the cache. As an application tries to read data, typically from a data storage system like a database, it checks to see if the desired record already exists in the cache. If it does, the application will read the data from the cache, thus eliminating the slower access to the database. If the desired record is not in the cache, then the application reads the record from the source. When it retrieves that data, it writes it to the cache so that when the application needs that same data in the future, it can quickly retrieve it from the cache.
Further, according to Hazelcast, as an application tries to read data, typically from a data storage system like a database, it checks to see if the desired record already exists in the cache. If it does, the application will read the data from the cache, thus eliminating the slower access to the database. If the desired record is not in the cache, then the application reads the record from the source. When it retrieves that data, it writes it to the cache so that when the application needs that same data in the future, it can quickly retrieve it from the cache.
Redis In-memory Data Store
According to their website, Redis is the open-source, in-memory data store used by millions of developers as a database, cache, streaming engine, and message broker. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. In addition, Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Amazon ElastiCache for Redis
According to AWS, Amazon ElastiCache for Redis, the fully-managed version of Redis, according to AWS, is a blazing fast in-memory data store that provides sub-millisecond latency to power internet-scale real-time applications. Redis applications can work seamlessly with ElastiCache for Redis without any code changes. ElastiCache for Redis combines the speed, simplicity, and versatility of open-source Redis with manageability, security, and scalability from AWS. As a result, Redis is an excellent choice for implementing a highly available in-memory cache to decrease data access latency, increase throughput, and ease the load on relational and NoSQL databases.
ElastiCache Performance Results
In the following post, we will add in-memory caching to the Spring Boot service introduced in the previous post. In preliminary tests with Amazon ElastiCache for Redis, the Spring Boot service delivered a 34x improvement in average response times. For example, test runs with the best-case scenario of a Redis cache hit ratio of 100% averaged 0.95 seconds compared to 32.4 seconds without Redis.

Source Code
All the source code and Docker and Kubernetes resources are open-source and available on GitHub.
git clone --depth 1 -b redis \
https://github.com/garystafford/athena-spring-app.git
In addition, a Docker image for the Redis-base Spring Boot service is available on Docker Hub. For this post, use the latest tag with the .redis suffix.
Code Changes
The following code changes are required to the Spring Boot service to implement Spring Boot Cache with Redis.
Gradle Build
The gradle.build file now implements two additional dependencies, Spring Boot’s spring-boot-starter-cache and spring-boot-starter-data-redis (lines 45–46).
Application Properties
The application properties file, application.yml, has been modified for both the dev and prod Spring Profiles. The dev Spring Profile expects Redis to be running on localhost. Correspondingly, the project’s docker-compose.yml file now includes a Redis container for local development. The time-to-live (TTL) for all Redis caches is arbitrarily set to one minute for dev and five minutes for prod. To increase application performance and reduce the cost of querying the data lake using Athena, increase Redis’s TTL. Note that increasing the TTL will reduce data freshness.
Athena Application Class
The AthenaApplication class declaration is now decorated with Spring Framework’s EnableCaching annotation (line 22). Additionally, two new Beans have been added (lines 58–68). Spring Redis provides an implementation for the Spring cache abstraction through the org.springframework.data.redis.cache package. The RedisCacheManager cache manager creates caches by default upon the first write. The RedisCacheConfiguration cache configuration helps to customize RedisCache behavior such as caching null values, cache key prefixes, and binary serialization.
POJO Data Model Classes
Spring Boot Redis caching uses Java serialization and deserialization. Therefore, all the POJO data model classes must implement Serializable (line 14).
Service Classes
Each public method in the Service classes is now decorated with Spring Framework’s Cachable annotation (lines 42 and 66). For example, the findById(int id) method in the CategoryServiceImp class is annotated with @Cacheable(value = "categories", key = "#id"). The method’s key parameter uses Spring Expression Language (SpEL) expression for computing the key dynamically. Default is null, meaning all method parameters are considered as a key unless a custom keyGenerator has been configured. If no value is found in the Redis cache for the computed key, the target method will be invoked, and the returned value will be stored in the associated cache.
Controller Classes
There are no changes required to the Controller classes.
Amazon ElastiCache for Redis
Multiple options are available for creating an Amazon ElastiCache for Redis cluster, including cluster mode, multi-AZ option, auto-failover option, node type, number of replicas, number of shards, replicas per shard, Availability Zone placements, and encryption at rest and encryption in transit options. The results in this post are based on a minimally-configured Redis version 6.2.6 cluster, with one shard, two cache.r6g.large nodes, and cluster mode, multi-AZ option, and auto-failover all disabled. In addition, encryption at rest and encryption in transit were also disabled. This cluster configuration is sufficient for development and testing, but not Production.


Testing the Cache
To test Amazon ElastiCache for Redis, we will use Postman again with the imported OpenAPI v3 specification. With all data evicted from existing Redis caches, the first time the Postman tests run, they cause the service’s target methods to be invoked and the returned data stored in the associated caches.
To confirm this caching behavior, use the Redis CLI’s --scan option. To access the redis-cli, I deployed a single Redis pod to Amazon EKS. The first time the --scan command runs, we should get back an empty list of keys. After the first Postman test run, the same --scan command should return a list of cached keys.

Use the Redis CLI’s MONITOR option to further confirm data is being cached, as indicated by the set command.

After the initial caching of data, use the Redis CLI’s MONITOR option, again, to confirm the cache is being hit instead of calling the target methods, which would then invoke the Athena API. Rerunning the Postman tests, we should see get commands as opposed to set commands.

Lastly, to confirm the Spring Boot service is effectively using Redis to cache data, we can also check Amazon Athena’s Recent queries tab in the AWS Management Console. After repeated sequential test runs within the TTL window, we should only see one Athena query per endpoint.
Conclusion
In this brief follow-up to the recent post, Developing Spring Boot Applications for Querying Data Lakes on AWS using Amazon Athena, we saw how to substantially increase data lake application performance using Amazon ElastiCache for Redis. Although this caching technique is often associated with databases, it can also be effectively applied to data lake-based applications, as demonstrated in the post.
This blog represents my viewpoints and not of my employer, Amazon Web Services (AWS). All product names, logos, and brands are the property of their respective owners. All diagrams and illustrations are property of the author unless otherwise noted.
-
You are currently browsing the archives for the Software Development category.
Gary Stafford
AWS Area Principal Solutions Architect | 10x AWS Certified Pro | DevOps | Data/ML | Serverless | Polyglot Developer | Former ThoughtWorks and Accenture
